[논문리뷰] AHA-WAM:Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jisong Cai, Long Ling, Shiwei Chu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- AHA-WAM: Asynchronous Horizon-Adaptive World-Action Modeling의 약어로, 로봇 조작을 위해 비디오 기반 World-Action Model과 행동 제어를 비동기적으로 분리한 프레임워크입니다.
- DiT (Diffusion Transformer): 본 논문에서 World Planner(비디오 기반)와 Action Executor(행동 예측)의 기반 아키텍처로 사용된 생성 모델 구조입니다.
- OVCR (Observation-Guided Video-Context Routing): 실시간 관측 정보(Observation)를 활용하여 캐싱된 저주파수 Planner Context를 고주파수 Executor가 바로 활용할 수 있도록 동적으로 라우팅 및 업데이트하는 기법입니다.
- Horizon-Adaptive Offset Training: 비동기식 실행에서 발생하는 Planner와 Executor 간의 시간적 위상 차이(Phase shift)에 모델이 강건하게 대응할 수 있도록, 학습 과정에서 액션 청크의 오프셋을 무작위로 변경하여 훈련하는 기법입니다.
- Rolling Planner Memory: 과거의 비디오 상태를 FIFO(First-In, First-Out) 방식으로 저장하여 Planner가 긴 시간 범위의 장기적인 장면 변화를 유지하도록 돕는 메모리 구조입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 World-Action Model(WAM)이 월드 모델링과 액션 실행을 동일한 시간 해상도로 강제 결합함으로써 발생하는 구조적 비효율 문제를 해결하고자 합니다 [Figure 1]. 기존 모델은 주변 프레임의 미세한 변화를 모델링하는 데 과도한 컴퓨팅 자원을 소모하며, 이는 실시간 로봇 제어의 반응성을 저하시키는 원인이 됩니다. 저자들은 월드 플래닝과 액션 실행을 시간적 비대칭성에 맞춰 비동기적으로 분리해야 한다고 주장합니다. 이러한 비동기 구조가 도입될 경우, 데이터가 일치하지 않거나(stale) 위상이 틀어질 수 있는 문제를 해결하는 것이 본 연구의 핵심 당면 과제입니다.
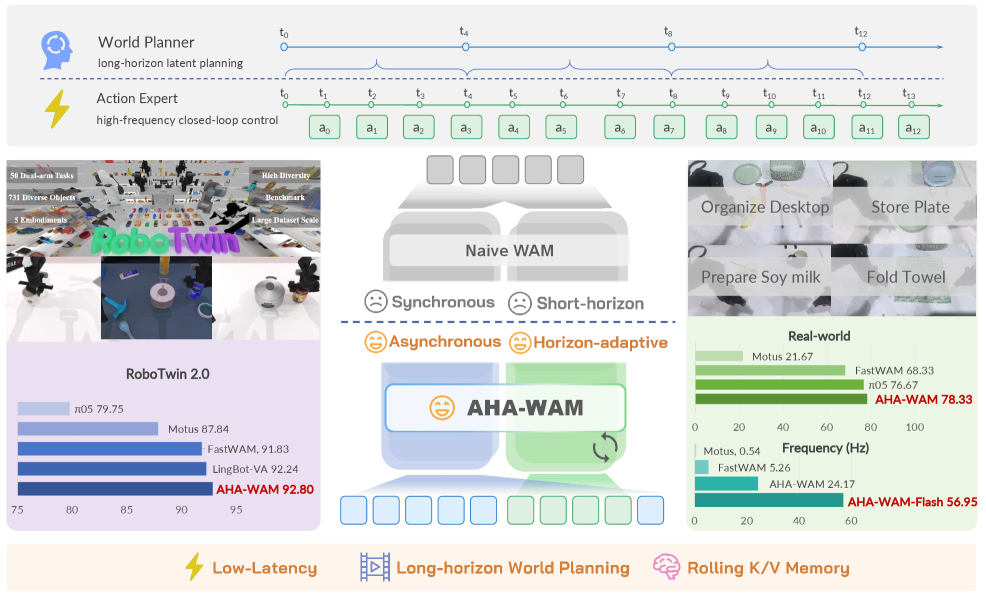
Figure 1 — AHA-WAM 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 비동기적 구조를 실현하기 위해 저주파수 Video DiT Planner와 고주파수 Action DiT Executor를 결합한 이중 구조를 제안합니다 [Figure 2]. Video DiT는 재사용 가능한 장기적 장면 컨텍스트를 생성하며, Action DiT는 이 컨텍스트를 활용해 실시간 폐루프(closed-loop) 제어를 수행합니다. 특히 OVCR은 Planner가 매번 재계산되지 않아도 최신 관측 정보에 맞게 컨텍스트를 적응시키는 핵심 역할을 수행하며, Horizon-Adaptive Offset Training은 다양한 위상 오프셋 환경에서도 모델이 안정적으로 동작하도록 합니다 [Figure 3].
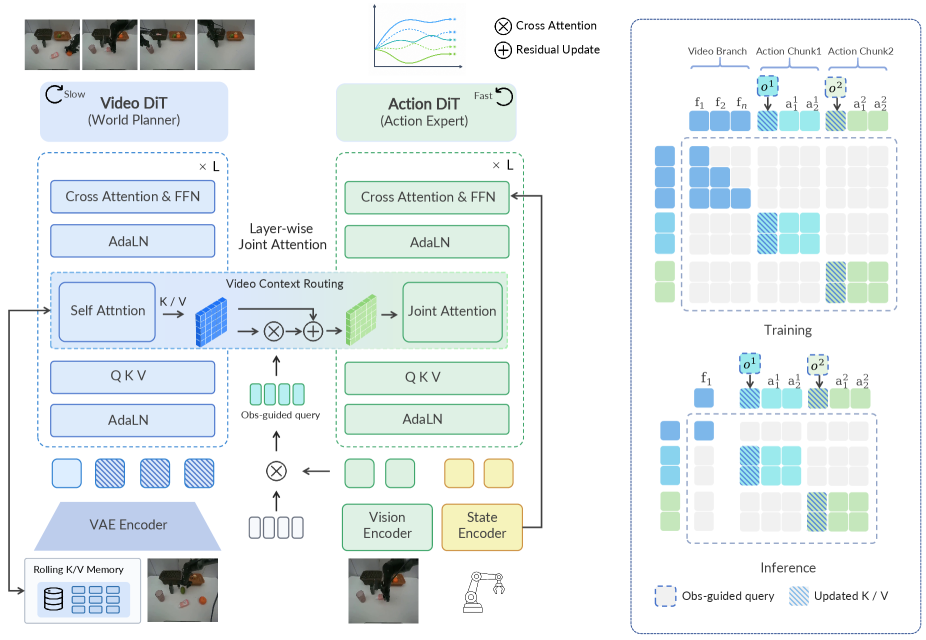
Figure 2 — Planner-Executor 분리 구조 및 어텐션 마스크

Figure 3 — Horizon-adaptive 오프셋 훈련 과정
정량적 실험 결과, AHA-WAM은 RoboTwin 벤치마크에서 로봇 데이터 사전 학습 없이도 92.80%의 평균 성공률을 기록하여 SOTA 수준의 성능을 입증했습니다. 또한 실시간 제어 측면에서 Fast-WAM 대비 4.59배 향상된 속도를 기록했으며, ODE distillation과 최적화를 적용한 버전은 최대 10.82배 속도 향상과 56.9 Hz의 제어 주파수를 달성하였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 월드 모델과 액션 모델을 시간적 해상도에 따라 비동기적으로 분리하는 것이 로봇 조작 성능과 효율성을 동시에 확보할 수 있는 유망한 설계임을 증명했습니다. AHA-WAM은 거대 규모의 로봇 데이터 사전 학습 없이도 높은 일반화 성능을 달성함으로써, 제한된 컴퓨팅 자원 내에서 로봇 제어기의 실시간성과 정교함을 향상시킬 수 있는 실질적인 토대를 마련했습니다. 본 연구의 설계 철학은 향후 비동기적 로봇 학습 프레임워크의 표준적 접근 방식으로 활용될 가능성이 높습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Text-to-Image Models Need Less from Text Encoders Than You Think
- [논문리뷰] SwiftVR: Real-Time One-Step Generative Video Restoration
- [논문리뷰] Robots Need More than VLA and World Models
- [논문리뷰] NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
- [논문리뷰] StreamChar: Long-Horizon Streaming Character Audio-Video Generation with Decoupled Orchestration
Review 의 다른글
- 이전글 [논문리뷰] A Geometric Account of Activation Steering through Angle-Norm Decomposition
- 현재글 : [논문리뷰] AHA-WAM:Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
- 다음글 [논문리뷰] Answer Presence Drives RAG Rewriting Gains
댓글