[논문리뷰] Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xin Gao, Cheng Yang, Chufan Shi, Taylor Berg-Kirkpatrick
1. Key Terms & Definitions (핵심 용어 및 정의)
- UMMs (Unified Multimodal Models): 텍스트와 이미지 처리 능력을 하나의 백본 모델 내에 통합하여 이해와 생성을 동시에 수행하는 모델 구조입니다.
- Knowledge Editing (KE): 모델을 재학습시키지 않고 특정 파라미터나 가중치를 수정하여 모델의 지식(Fact)을 업데이트하는 기술입니다.
- UniKE: 본 논문에서 제안하는, UMMs의 텍스트 기반 지식 수정이 실제 이미지 생성 결과에 반영되는지 평가하기 위한 최초의 cross-modality 지식 편집 벤치마크입니다.
- Reasoning-augmented Parameter Editing: 모델이 이미지 생성 전 중간 추론 단계(Rationale)를 명시적으로 생성하게 하여, 수정된 지식을 활성화하고 시각적 생성 결과로 전이시키는 프레임워크입니다.
- VQA (Visual Question Answering) Verification: 생성된 이미지가 편집된 지식과 일치하는지 자동으로 검증하기 위해 VQA 모델을 판별기로 사용하는 평가 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 UMMs에서 수행된 텍스트 기반 지식 편집(Knowledge Editing)이 이미지 생성 과정으로 적절히 전이되는지 검증하고자 합니다 [Figure 1]. 기존의 텍스트 도메인 지식 편집 기법들은 텍스트 출력에서는 높은 성공률을 보이지만, 동일한 수정이 시각적 생성 결과로까지 일관되게 이어지는지는 불명확합니다. 저자들은 이러한 모달리티 간 지식 전이의 불일치를 "cross-modality knowledge-editing gap"으로 정의하고, 이를 체계적으로 분석할 필요성을 강조합니다. 특히 텍스트 지식 편집이 시각적 합성(Image Synthesis)의 기반이 되는 잠재 표현(Latent Representation)을 충분히 변화시키지 못하는 문제에 주목합니다 [Figure 1].
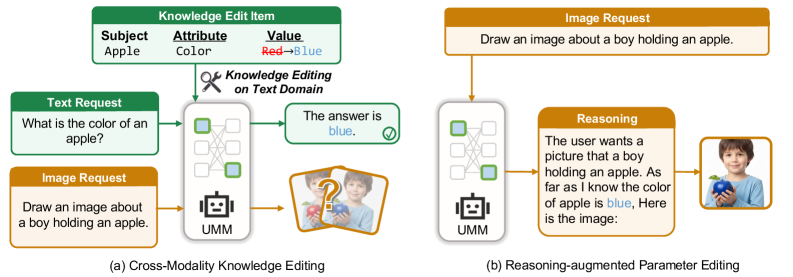
Figure 1 — 교차 모달 지식 편집 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Attribute(속성)와 Relation(관계)을 포함한 2,971개의 편집 항목으로 구성된 UniKE 벤치마크를 구축하여 실험을 수행하였습니다 [Table 1, Figure 2]. 제안된 Reasoning-augmented Parameter Editing은 이미지 생성 직전에 모델이 스스로 수정된 사실을 추론하도록 유도하여, 이를 텍스트 조건(Textual Condition)으로 삼아 생성 모델의 시각적 출력을 제어합니다 [Figure 1]. 실험 결과, 기존의 직접 편집 방식으로는 텍스트 효능(Efficacy)이 ~92%에 달함에도 불구하고, 시각적 검증 정확도(VQA Accuracy)는 18.5% 이하에 그치는 현상이 관찰되었습니다. 반면, 제안한 추론 증강 기법을 도입했을 때 모든 평가 모델에서 VQA Accuracy가 유의미하게 상승하였으며, 최대 18.6%p의 성능 향상을 기록했습니다 [Table 3]. 또한 기계적 분석(Mechanistic Analysis) 결과, 편집된 지식이 시각 생성부(DiT, Diffusion Transformer)로 전달되는 과정에서 일종의 'Conditioning-pathway bottleneck'이 발생함을 확인하였습니다 [Figure 4, Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 텍스트 기반의 지식 편집이 이미지 생성 도메인으로 자동 전이되지 않는다는 중요한 한계를 증명하였습니다. 제안된 UniKE 벤치마크는 향후 UMMs의 멀티모달 지식 업데이트 연구를 위한 기준을 제시하며, Reasoning-augmented 프레임워크는 지식 편집 기술이 멀티모달 환경에서 효과적으로 작동하기 위한 실질적인 해법을 제공합니다. 이 연구는 모델의 내적 지식이 모달리티 경계를 넘어 어떻게 표현되고 제어되는지에 대한 심층적인 통찰을 제공하며, 보다 신뢰할 수 있고 제어 가능한 멀티모달 AI 시스템 개발에 기여할 것으로 기대됩니다.

Figure 2 — UniKE 데이터 예시
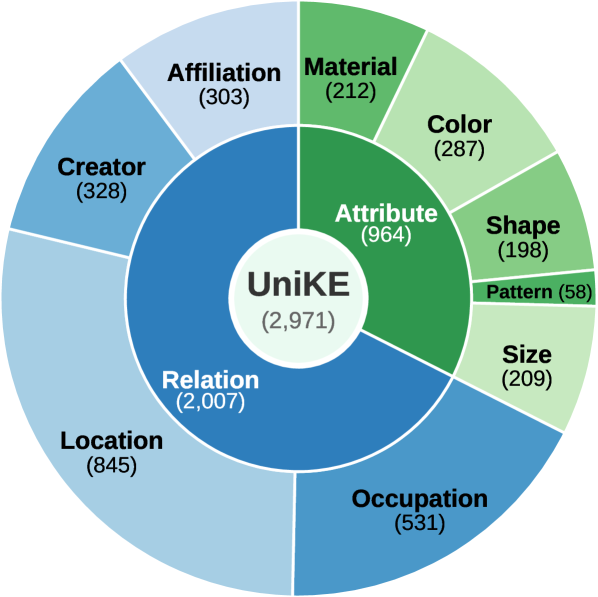
Figure 3 — 벤치마크 구성 도표
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Visual Generation Unlocks Human-Like Reasoning through Multimodal World Models
- [논문리뷰] ROVER: Benchmarking Reciprocal Cross-Modal Reasoning for Omnimodal Generation
- [논문리뷰] Representation Forcing for Bottleneck-Free Unified Multimodal Models
- [논문리뷰] Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
- [논문리뷰] Semantic Generative Tuning for Unified Multimodal Models
Review 의 다른글
- 이전글 [논문리뷰] Deep Embedded Multiplicative DMD for Algebra-Preserving Koopman Learning
- 현재글 : [논문리뷰] Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
- 다음글 [논문리뷰] Echo-Infinity: Learning Evolving Memory for Real-Time Infinite Video Generation
댓글