[논문리뷰] ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziyan Liu, Xueda Shen, Yuzhe Gu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LRMs (Large Reasoning Models): 복잡한 논리적 추론 및 단계별 사고(CoT)를 수행하기 위해 설계된 대규모 언어 모델입니다.
- RLVR (Reinforcement Learning with Verifiable Rewards): 최종적인 결과의 정확성만을 보상으로 삼아 모델을 최적화하는 학습 패러다임입니다.
- Fold Anchor: 긴 추론 과정에서 불필요한 단계를 제거한 후, 핵심적인 논리 흐름을 재연결하기 위해 정의된 특정 추론 단계를 의미합니다.
- Introspective Redundancy Identification: 모델 스스로 성공적인 추론 경로 내에서 중복되거나 비효율적인 단계를 반복적으로 제거하고 검증하는 탐색 전략입니다.
- Dynamic Mask Strategy: 추론 경로 내 특정 토큰이나 단계에 대해 학습 과정에서 차별적인 가중치를 부여하여 효율적인 경로를 학습시키는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LRMs가 추론 과정에서 "오버씽킹(overthinking)" 현상으로 인해 불필요하게 긴 CoTs를 생성하여 비효율적인 계산 자원을 소모하는 문제를 해결하고자 합니다. 기존의 RLVR 방식은 최종 정확도만을 보상으로 사용하기 때문에, 정답에 도달하는 경로 내에 포함된 반복적인 시행착오나 중복된 탐색 과정까지 모두 강화 학습 대상이 되어 모델이 비효율적인 추론 패턴을 습득하게 됩니다. [Figure 1]에서 볼 수 있듯이, 이러한 방식은 모델이 성공적인 논리적 추론뿐만 아니라 그 과정의 불필요한 노이즈까지 함께 암기하게 만듭니다. 기존의 길이 기반 페널티(Length-Reward) 연구들은 단계별 세밀한 신호 전달이 부족하여 정확도와 효율성 사이의 근본적인 절충안을 제시하지 못하는 한계가 있습니다.
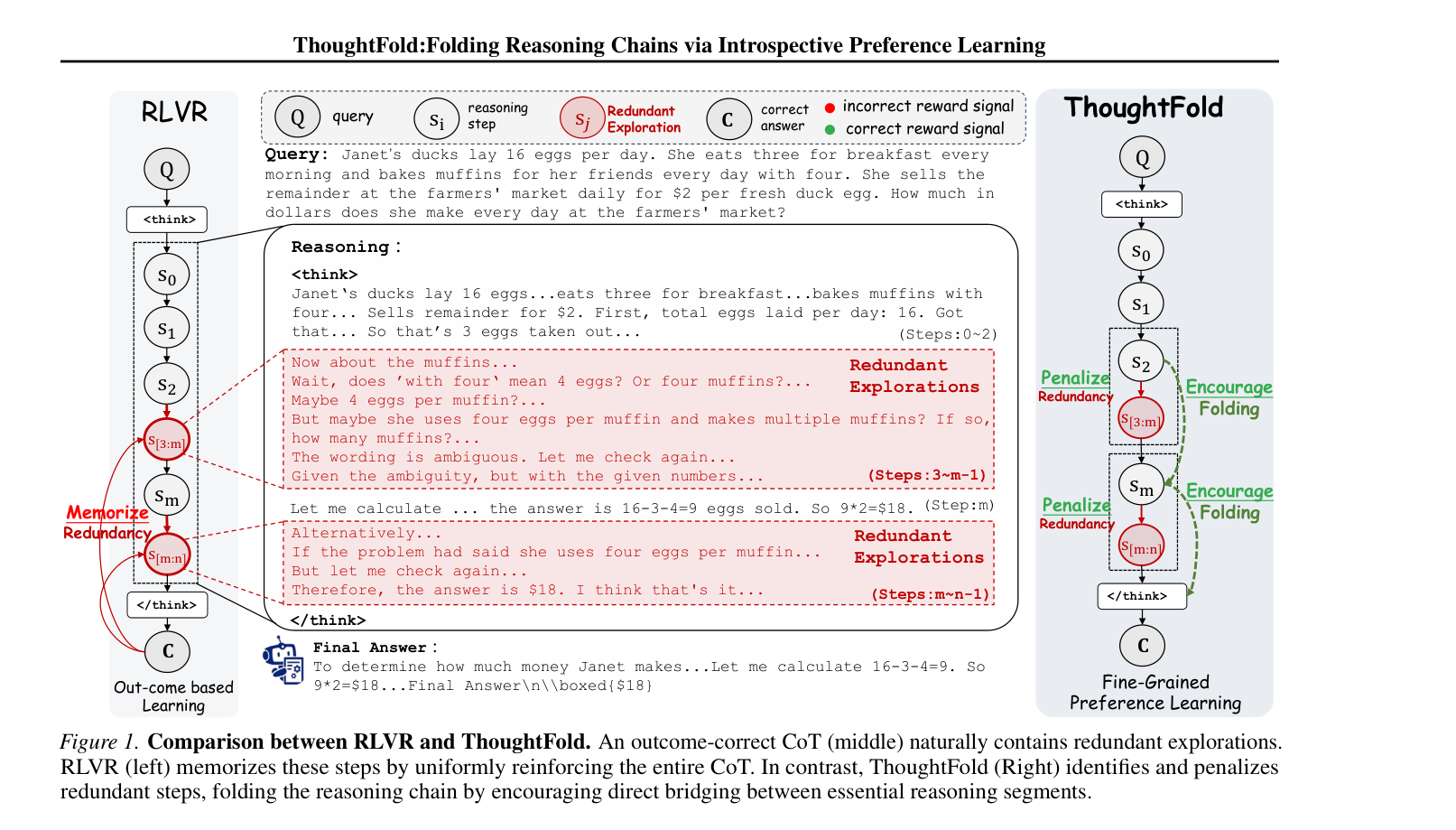
Figure 1 — RLVR의 과잉 사고 문제와 ThoughtFold의 구조적 해결책을 보여주는 핵심 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
ThoughtFold는 내성적 탐색(Introspective Strategy)과 세밀한 Preference Learning을 결합하여 추론 체인을 효과적으로 "접는(folding)" 새로운 프레임워크를 제안합니다. 이 방법론은 크게 추론 경로 내의 중복 단계를 식별하는 단계와, 이를 Masked Preference OptimizationObjective를 통해 학습하는 단계로 구성됩니다. 제안된 방법은 [Figure 2]와 같이 Fold Anchor 개념을 도입하여 필수적인 논리 단계들을 직접 연결하도록 모델을 유도합니다. 실험 결과, DeepSeek-R1-Distill-Qwen-7B 모델을 사용했을 때 GSM8K, AIME, MATH-500 등 다양한 벤치마크에서 정확도를 유지하면서도 평균 토큰 소비량을 약 56%까지 대폭 감소시키는 성과를 거두었습니다. [Table 1]에 명시된 성능 수치를 통해 확인할 수 있듯이, 기존의 S-GRPO나 단순 길이 페널티 기법 대비 정확도와 효율성 지표 모두에서 우위를 점하며 더욱 견고한 추론 성능을 보였습니다.
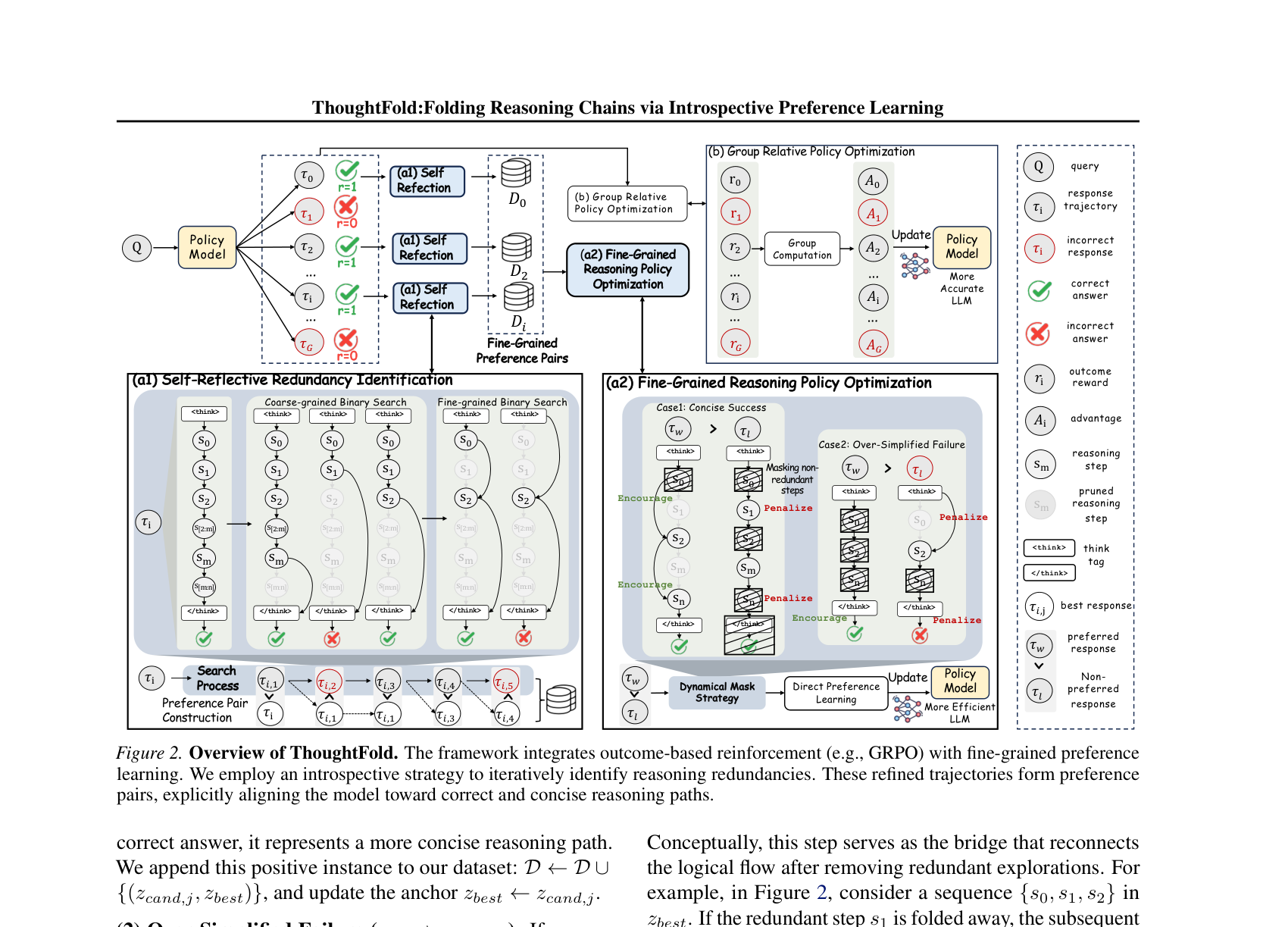
Figure 2 — 프레임워크의 전체 학습 파이프라인 및 방법론을 설명하는 아키텍처 다이어그램

Table 1 — 제안 모델과 기존 베이스라인 간의 정확도 및 효율성 정량적 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 추론 과정의 중복성을 능동적으로 식별하고 제거하는 ThoughtFold를 통해 모델의 추론 효율성을 극대화하는 새로운 패러다임을 확립했습니다. 이 연구는 단순히 출력 길이를 줄이는 것이 아니라, 모델의 내재적 추론 구조를 더 간결하고 직접적인 경로로 재구성함으로써 효율성과 성능의 균형을 맞추는 데 기여했습니다. 향후 대규모 언어 모델의 추론 최적화 분야에서 정교한 Preference Learning을 활용한 효율성 제고 연구에 중요한 이정표가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TEMPO: Scaling Test-time Training for Large Reasoning Models
- [논문리뷰] Enhancing Spatial Understanding in Image Generation via Reward Modeling
- [논문리뷰] Does Your Reasoning Model Implicitly Know When to Stop Thinking?
- [논문리뷰] THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
- [논문리뷰] DLER: Doing Length pEnalty Right - Incentivizing More Intelligence per Token via Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] Streaming Communication in Multi-Agent Reasoning
- 현재글 : [논문리뷰] ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
- 다음글 [논문리뷰] Training-Free Multi-Concept LoRA Composition with Prompt-Aware Weighting
댓글