[논문리뷰] Towards Truly Multilingual ASR: Generalizing Code-Switching ASR to Unseen Language Pairs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Gio Paik, Hyunseo Shin, Soungmin Lee
1. Key Terms & Definitions (핵심 용어 및 정의)
- Code-Switching (CS) ASR: 하나의 발화 내에서 두 개 이상의 언어가 혼용되는 음성 데이터를 인식하는 기술입니다.
- Mixed Error Rate (MER): 다국어 및 코드 스위칭 음성 인식 성능을 평가하기 위해 언어별 전사 특성을 고려하여 계산하는 지표입니다.
- Model Merging: 서로 다른 데이터셋으로 학습된 모델의 가중치를 결합하여 새로운 태스크에 대한 성능을 향상시키는 기법입니다.
- Domain Generalization (DG): 학습 과정에서 보지 못한 새로운 데이터셋(도메인)에 대해서도 모델이 강건한 성능을 발휘하도록 하는 학습 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 코드 스위칭 ASR 시스템이 소수의 학습된 언어 쌍을 넘어 보지 못한 언어 쌍으로 범용성을 확장할 수 있는지 검증합니다. 현재 대다수의 CS-ASR 연구는 특정 언어 쌍에 국한된 데이터셋을 사용하는데, 지원하는 언어의 수가 증가할수록 조합 가능한 언어 쌍이 기하급수적으로 늘어나기 때문에 모든 쌍에 대해 데이터를 수집하는 것은 비효율적입니다. 기존의 Pair-specific Fine-tuning이나 합성 데이터 생성 방식은 확장성에 한계가 있으며, 새로운 언어 쌍에 대한 CS 성능을 일반화하는 기술적 돌파구가 필요합니다 [Table 1].
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Whisper-medium을 백본 모델로 활용하여, ko-en, ja-en, de-en 등 비교적 접근이 쉬운 언어 쌍에서 학습된 CS 능력을 ko-ja 및 ko-de와 같은 보지 못한 언어 쌍으로 전이시키는 실험을 수행합니다. 구체적으로는 Task Arithmetic, TIES, DARE와 같은 모델 머징 기법과 Fish, Fishr, GGA-L 등 도메인 일반화 기법을 적용하여 성능을 분석합니다. 실험 결과, 단순 Fine-tuning만으로는 unseen 언어 쌍에 대한 성능 개선이 미미했으나, TIES 기반의 모델 머징은 간섭을 최소화하며 언어 쌍 간의 CS 능력을 안정적으로 결합함을 확인하였습니다. 특히 TIES를 통해 결합된 모델은 평균 MER을 낮추며 경쟁력 있는 성능을 보여주었으나, 전반적인 수치는 여전히 Practical deployment를 위한 기준에는 미치지 못함을 확인하였습니다. 또한, Layer-wise MAV 분석을 통해 CS 적응이 저수준 음성 처리보다는 높은 계층의 언어적 표현(Higher layers)에서 주로 발생함을 밝혔습니다 [Figure 1].
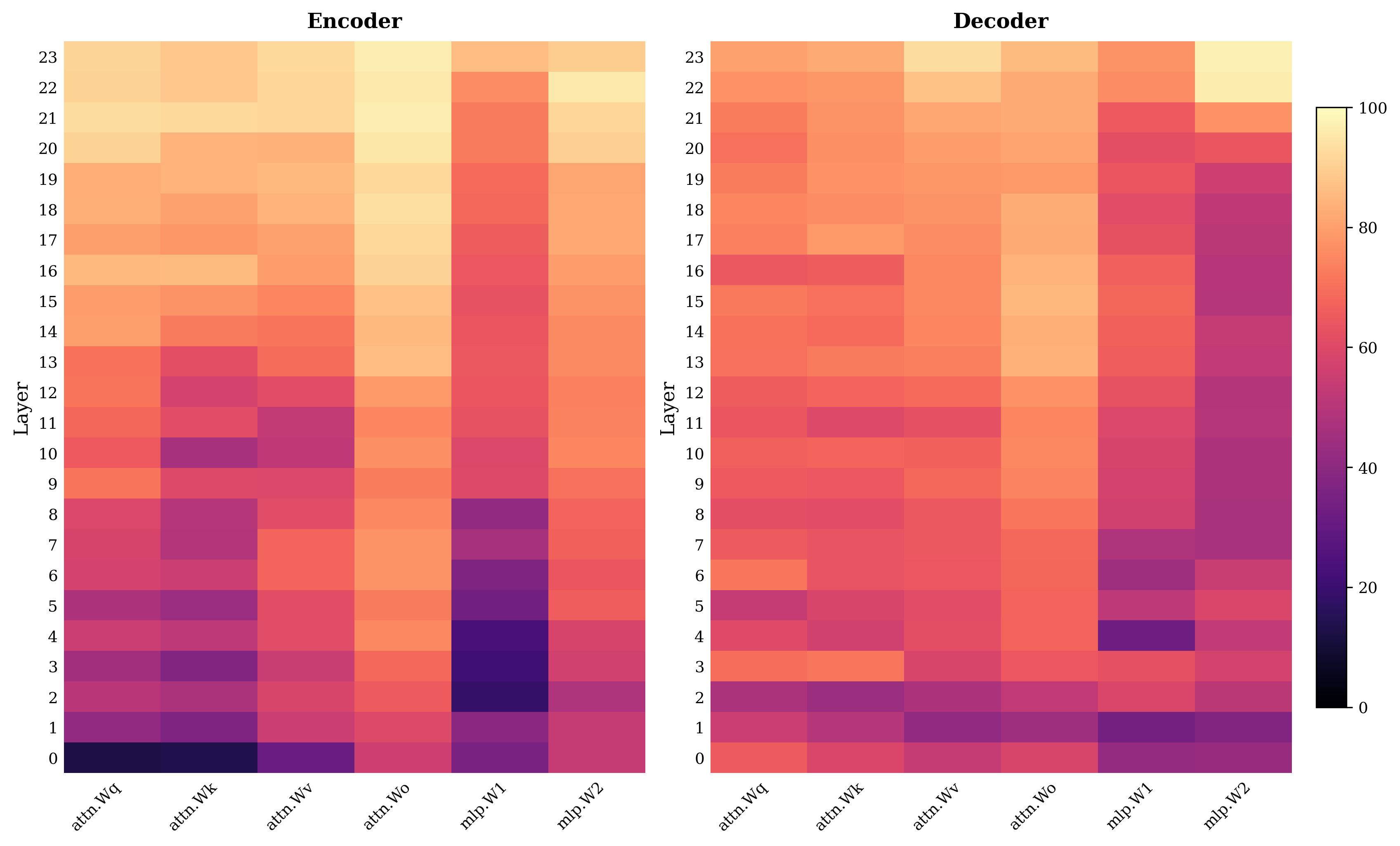
Figure 1 — ko-en 모델의 계층별 매개변수 변화량
4. Conclusion & Impact (결론 및 시사점)
본 논문은 기존의 일반적인 모델 머징이나 DG 기법을 CS-ASR에 직접 적용할 경우, 언어 쌍 간의 분포 차이로 인해 일반화 성능에 한계가 있음을 실증적으로 증명하였습니다. 연구진은 한국어-일본어 및 한국어-독일어 CS 평가 데이터셋을 신규 구축하여 공개하였으며, 이는 저자원 언어 쌍에 대한 CS 연구의 발판을 마련했습니다. 본 연구의 결과는 향후 다국어 CS-ASR 발전을 위해 단순 도메인 적응을 넘어선, 언어 쌍 전환을 명시적으로 학습할 수 있는 특화된 아키텍처 및 적응 전략의 필요성을 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MedSAMix: A Training-Free Model Merging Approach for Medical Image Segmentation
- [논문리뷰] WorldOlympiad: Can Your World Model Survive a Triathlon?
- [논문리뷰] U-TTT: Towards Generalizable PET Image Denoising via Test-Time Training
- [논문리뷰] OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
- [논문리뷰] Access Sets Matter: Budgeting Expert Reads for Scalable Weight-Space Model Merging
Review 의 다른글
- 이전글 [논문리뷰] Towards One-to-Many Temporal Grounding
- 현재글 : [논문리뷰] Towards Truly Multilingual ASR: Generalizing Code-Switching ASR to Unseen Language Pairs
- 다음글 [논문리뷰] Unsupervised Skill Discovery for Agentic Data Analysis
댓글