[논문리뷰] Augmenting Attention with Exponentially Decaying Memory Improves Query-Aware KV Sparsity
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xiuying Wei, Caglar Gulcehre, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RAT+:
Recurrence-augmented attention을 기반으로Exponentially Decaying Memory를 도입한 아키텍처로,Dilated attention및 효율적인Sparse inference를 지원한다. - Exponentially Decaying Memory: 이전의 KV 상태를 재귀적으로 결합하여 현재 상태를 업데이트하는 메커니즘으로, 모델이 긴 문맥 정보를 효율적으로 압축하고 보존하게 한다.
- Query-Aware Sparsity: 입력
Query에 따라 동적으로 중요한 KV 블록이나 토큰을 선택하여 계산 비용과KV-cache사용량을 줄이는 추론 기법이다. - NIAH (Needle-in-a-Haystack): 긴 문맥에서 특정 정보(Needle)를 검색해야 하는 태스크로, 모델의 문맥 이해도와
Sparse inference기법의 성능을 평가하는 표준 지표이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Long-context LLM의 추론 효율성을 높이기 위한 기존 Query-aware sparse inference 기법들의 성능 한계를 극복하는 것을 목표로 한다. 기존 연구들은 Quest, MoBA, SnapKV와 같은 방식을 통해 계산 비용과 KV-cache 사용량을 줄이고 있으나, 높은 수준의 Sparsity(예: 98% sparsity)가 요구되는 상황에서는 상당한 정확도 저하가 발생한다. 저자들은 이러한 성능 저하가 Standard attention 백본의 구조적 한계에서 기인한다고 보고, RAT+의 Exponentially decaying memory를 결합할 경우 정보 보존력을 높여 이러한 한계를 개선할 수 있을 것이라고 가정한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 RAT+ 백본의 Exponentially decaying memory를 활용하여 Quest, MoBA, SnapKV 등 주요 Query-aware sparse inference 기법들을 강화하는 프레임워크를 제안한다. 핵심 방법론은 기존 Standard attention의 KV 상태 대신 Memory-augmented 상태를 sparse inference의 입력으로 사용하여 더욱 정확한 후보군 선정과 정보 전달을 수행하는 것이다. 실험 결과, RAT+ 백본은 모든 sparse inference 방법과 다양한 KV budget 조건에서 Standard attention 대비 일관된 정확도 향상을 보였다. 구체적으로 SnapKV는 1/4 및 1/8 budget에서 8개 태스크 평균 기준 각각 34.11점, 40.03점 향상되었으며, OLMo2-7B 모델 기반 실험에서도 Quest(MK-2 태스크: 68.0 → 98.6) 및 MoBA(MK-3 태스크: 53.6 → 94.8) 모두에서 극적인 성능 개선을 입증했다. 또한, 저자들은 Memory-augmented 상태가 정밀한 후보 선정(H1) 및 추가적인 정보 경로 제공(H2)을 통해 성능 향상을 이끈다는 가설을 검증하였다. [Figure 1]
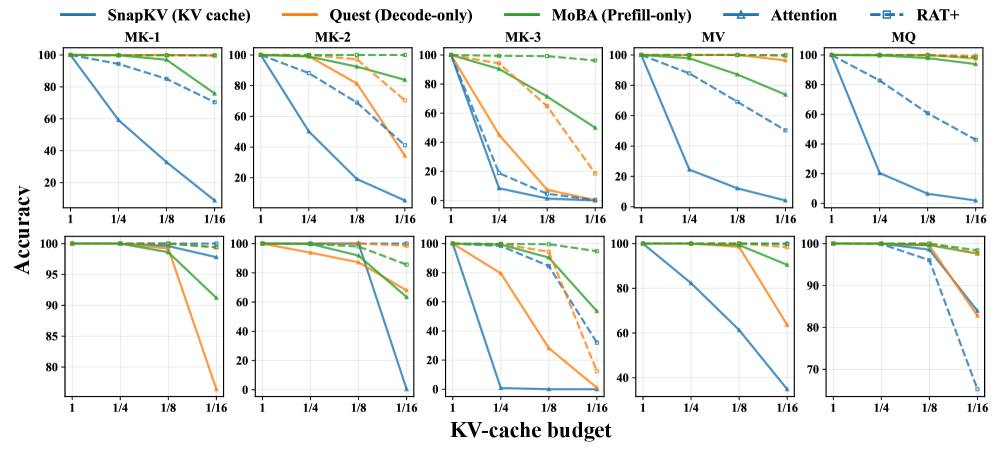
Figure 1 — 백본별 NIAH 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Exponentially decaying memory를 활용한 Upstream 아키텍처 개선이 기존의 Query-aware sparse inference 기법들의 효율성과 정확도를 동시에 극대화할 수 있음을 입증했다. 이 연구는 효율적인 추론을 위해 단순히 하위 레벨의 sparse 기법만 최적화하는 기존 접근 방식에서 벗어나, 아키텍처 설계를 통한 구조적 해결책이 필요함을 시사한다. 학계와 산업계는 본 결과를 통해 대규모 모델의 Long-context 추론 성능을 유지하면서 비용을 대폭 절감할 수 있는 새로운 경로를 확보하게 되었다.
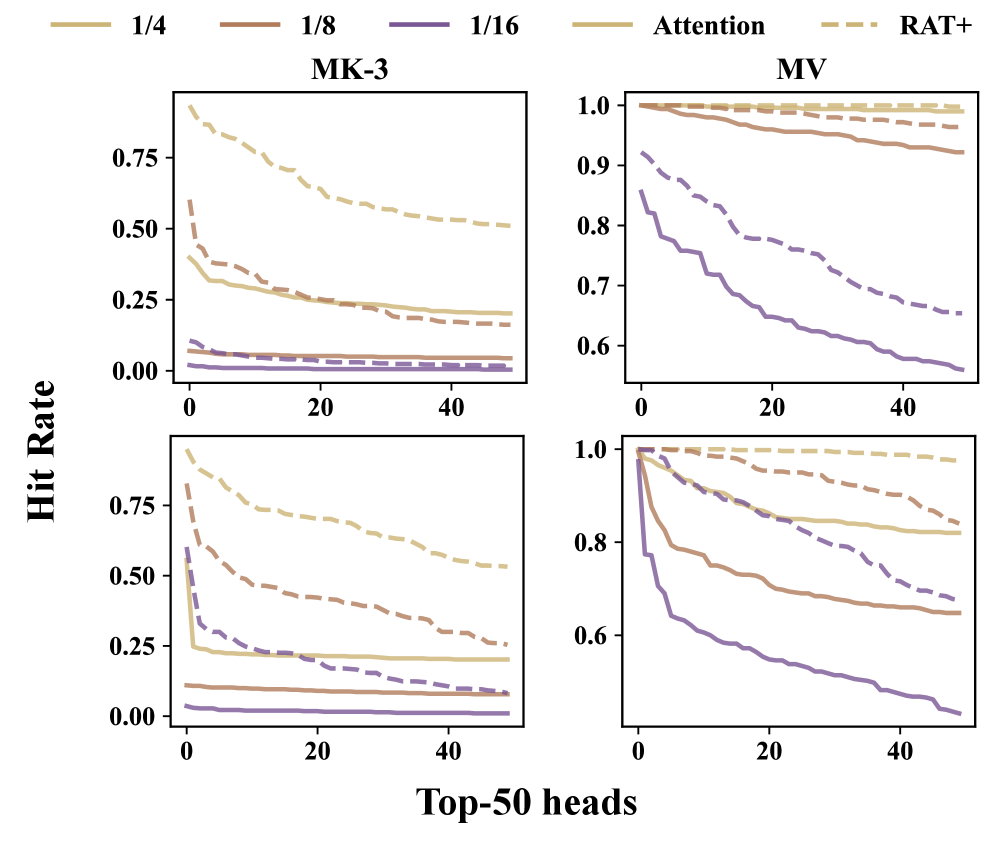
Figure 2 — 헤드별 Hit-rate 분포
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Light-WAM: Efficient World Action Models with State-Fusion Action Decoding
- [논문리뷰] Echo-Infinity: Learning Evolving Memory for Real-Time Infinite Video Generation
- [논문리뷰] When Cloud Agents Meet Device Agents: Lessons from Hybrid Multi-Agent Systems
- [논문리뷰] Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
- [논문리뷰] CompactAttention: Accelerating Chunked Prefill with Block-Union KV Selection
Review 의 다른글
- 이전글 [논문리뷰] AnchorWorld: Embodied Egocentric World Simulation with View-based Evolution Customization
- 현재글 : [논문리뷰] Augmenting Attention with Exponentially Decaying Memory Improves Query-Aware KV Sparsity
- 다음글 [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
댓글