[논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Maxime Griot, Paul Steven Scotti, Tanishq Mathew Abraham
1. Key Terms & Definitions (핵심 용어 및 정의)
- Chain-of-Thought (CoT) Trace: LLM이 최종 답변에 도달하기까지 생성하는 단계별 추론 과정으로, 본 논문에서는
<think>…</think>블록으로 지칭함. - Trace Compression: 모델을 사용하여 긴 CoT 추론 과정을 논리적 핵심과 주요 통찰을 유지하면서 더 짧은 분량으로 재작성하는 기법.
- Knowledge Distillation (KD): 더 큰 Teacher 모델이 생성한 추론 데이터를 기반으로 작은 Student 모델을 학습시켜 추론 능력을 전수하는 과정.
- Inference-time Efficiency: 모델이 추론 시 출력하는 토큰의 길이를 줄여 연산량과 레이턴시를 최적화하는 성능 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Reasoning 모델들이 생성하는 긴 Chain-of-Thought 추론 과정이 Distillation 시 비용을 크게 증가시키고, Student 모델이 지나치게 장황한 답변을 생성하도록 유도한다는 점에 주목합니다. 기존 연구들은 추론 능력을 전수하기 위해 Teacher의 원본 추론을 그대로 활용했으나, 이는 훈련 데이터 생성 및 학습 시간을 불필요하게 늘리는 결과를 초래했습니다 [Figure 2]. 저자들은 Teacher의 추론을 사전에 압축(Compress)하는 것이 Distillation의 효율성을 높일 수 있는지, 그리고 이로 인해 발생하는 정확도와 효율성 사이의 Trade-off는 무엇인지 규명하고자 합니다.
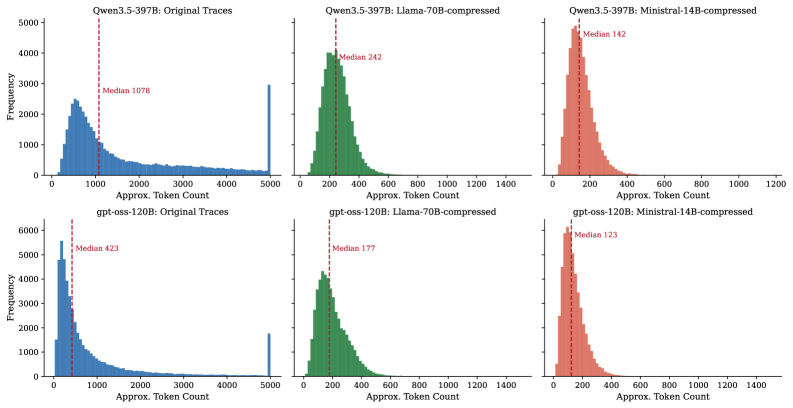
Figure 2 — 추론 토큰 분포 변화
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문이 제안하는 Compress-Distill은 3단계 파이프라인으로 구성됩니다: (1) Teacher 모델을 통해 검증된 correct trace를 생성하는 Stage 1, (2) 강력한 instruction-tuned 모델을 활용하여 해당 trace를 간결하게 압축하는 Stage 2, (3) 압축된 추론 데이터를 사용하여 Student 모델을 Fine-tuning하는 Stage 3입니다 [Figure 1]. 저자들은 Qwen3.5-397B와 gpt-oss-120B 두 종류의 Teacher를 사용하여 48개의 메인 학습 조합을 실험했습니다. 주요 실험 결과, 압축된 추론 데이터는 학습 토큰 수를 원본의 1230% 수준으로 절감하고, 학습 시간을 2.07.6배 가속화하며, 추론 길이를 최대 19배 단축시키는 효과를 보였습니다 [Figure 3]. 다만, 모든 모델 규모에서 정확도 면에서는 원본 추론 데이터(Raw)가 가장 우수했으며, 압축 데이터는 정확도를 최대 96% 유지하면서 높은 효율성을 확보하는 Trade-off를 제공함을 입증했습니다 [Table 3]. 또한, naive한 truncation 방식보다 모델 기반 압축이 추론 성능을 훨씬 잘 보존한다는 점을 확인했습니다 [Figure 4].
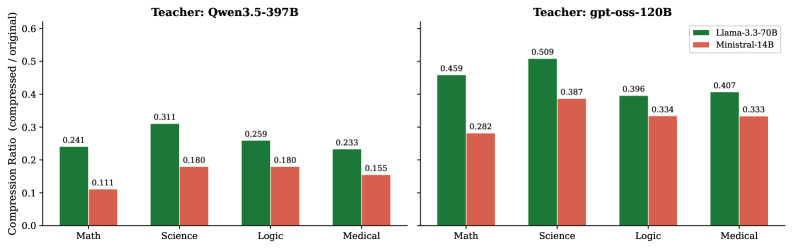
Figure 1 — 도메인별 평균 압축률
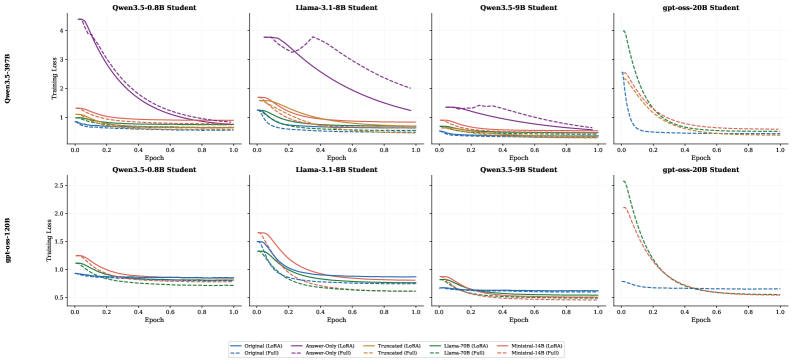
Figure 3 — 학습 손실 곡선
4. Conclusion & Impact (결론 및 시사점)
본 연구는 reasoning-trace 압축이 단순한 성능 향상이 아닌, 정확도와 효율성 사이의 실질적인 선택지를 제공하는 기법임을 실증적으로 입증했습니다. 압축된 데이터는 추론 시 발생하는 오버헤드를 줄이는 데 매우 효과적이며, 특히 LoRA fine-tuning 환경에서 효율성이 극대화됩니다. 이 연구는 제한된 연산 자원을 가진 환경에서 reasoning 능력을 갖춘 LLM을 배포하고자 하는 산업계에 중요한 가이드라인을 제시하며, 향후 도메인 특화 압축 프롬프트 및 정밀한 Answer-preservation 검증 기술의 발전 토대가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Search-R3: Unifying Reasoning and Embedding Generation in Large Language Models
- [논문리뷰] Mol-R1: Towards Explicit Long-CoT Reasoning in Molecule Discovery
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It
Review 의 다른글
- 이전글 [논문리뷰] Augmenting Attention with Exponentially Decaying Memory Improves Query-Aware KV Sparsity
- 현재글 : [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
- 다음글 [논문리뷰] Critic-R: Improving Agentic Search using Instruction-tuned Retrievers with Natural Language Introspective Feedback
댓글