[논문리뷰] Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
링크: 논문 PDF로 바로 열기
저자: Chuan Xiao, Zhengbo Jiao, Shaobo Wang, Wei Wang, Bing Zhao, HU WEI, Linfeng Zhang, Lin Qu
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Socratic-SWE: 소프트웨어 엔지니어링 에이전트를 위한 폐쇄 루프(Closed-loop) 자기 진화 프레임워크로, 과거의 solving trace로부터 기술을 추출하여 다음 학습 주기를 개선합니다.
- Agent Skill Registry: 해결된 trace와 실패한 trace를 증류하여 생성된 구조화된 스킬 저장소로, 에이전트의 능력 경계를 정의하고 타겟팅된 작업 생성을 안내합니다.
- Solver-Gradient Alignment Reward: 생성된 후보 작업이 검증된 held-out 태스크셋의 정책 업데이트 방향과 일치할 때 높은 보상을 부여하는 정렬 지표입니다.
- GDPO (Group Reward-Decoupled Normalization Policy Optimization): 다중 보상 컴포넌트를 그룹 단위로 정규화하여 학습 안정성을 높이는 정책 최적화 기법입니다.
- SWE-bench Verified: 소프트웨어 엔지니어링 에이전트의 성능을 측정하는 표준 벤치마크 데이터셋 중 하나입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 LLM 기반 소프트웨어 엔지니어링 에이전트가 고품질 태스크 데이터 부족으로 인해 학습 및 일반화 성능이 제한되는 문제를 해결하고자 합니다. 기존 합성 데이터 생성 방식은 고정된 규칙이나 무작위 버그 주입에 의존하여 에이전트의 실제 취약점이나 학습 진행 상황을 반영하지 못한다는 한계가 있습니다. [Figure 1]에서 제시하는 바와 같이, 기존 패러다임은 평가용 trace를 단순히 사후 보상 계산에만 활용하고 폐기하는 비적응적(Non-adaptive) 구조를 가지고 있습니다. 따라서 저자들은 에이전트가 생성한 trace 자체가 에이전트의 capability gap을 직접적으로 보여준다는 점에 착안하여, 이를 재활용하는 자기 진화형 학습 루프를 설계하였습니다.
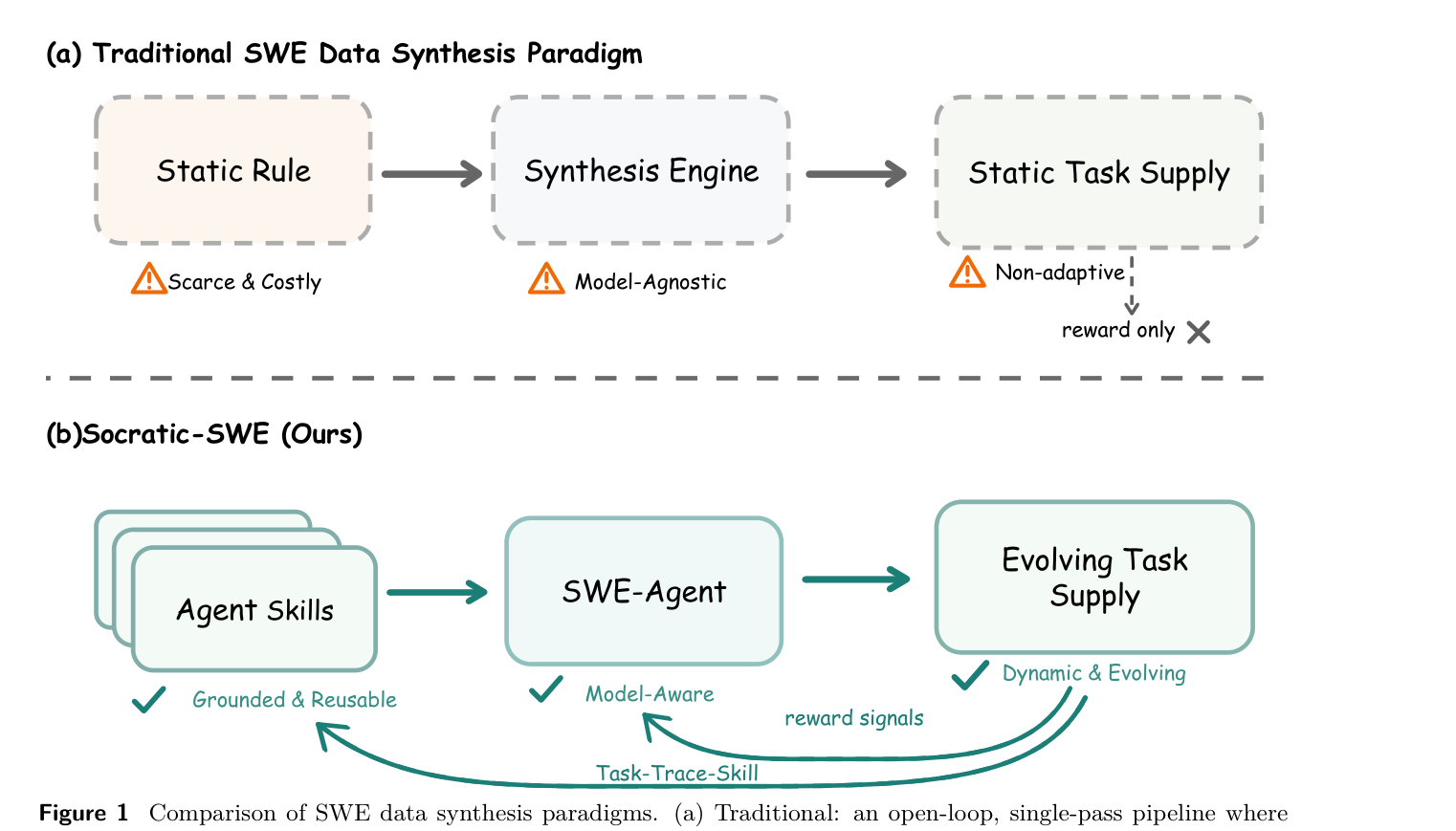
Figure 1 — 기존의 정적인 데이터 합성 방식과 제안하는 자기 진화형 폐쇄 루프 방식의 차이를 한눈에 보여주는 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) Socratic-SWE는 Solving trace를 기술(Skill)로 증류하고 이를 기반으로 새로운 태스크를 생성하는 3단계 순환 구조를 통해 에이전트를 자가 학습시킵니다. 먼저 [Figure 3]의 Overview에서 확인할 수 있듯, 수집된 trace로부터 반복적인 실패 패턴과 성공 전략을 추출하여 Agent Skill Registry를 구축하고, 이를 Generator가 참조하여 현실적인 리포지토리 환경에서 고난도 버그를 타겟팅한 태스크를 생성합니다. 생성된 후보 태스크는 실행 기반 검증 및 정책 경사 정렬 보상(Gradient alignment reward)을 통해 필터링되어 학습 효율을 극대화합니다. [Table 1]에 따르면, Socratic-SWE는 SWE-bench Verified에서 3번의 반복 학습 후 50.40%의 정확도를 달성하여, 동등한 컴퓨팅 자원을 사용한 다른 자기 진화 베이스라인들을 크게 앞질렀습니다. 특히 Terminal-Bench 2.0에서도 14.61%의 성능을 기록하며 일반화 성능의 우수성을 입증하였습니다. [Figure 4]는 Socratic-SWE가 기존 베이스라인(SSR)보다 더 높은 성능 정점(Ceiling)에 도달하며 안정적으로 확장됨을 보여줍니다.
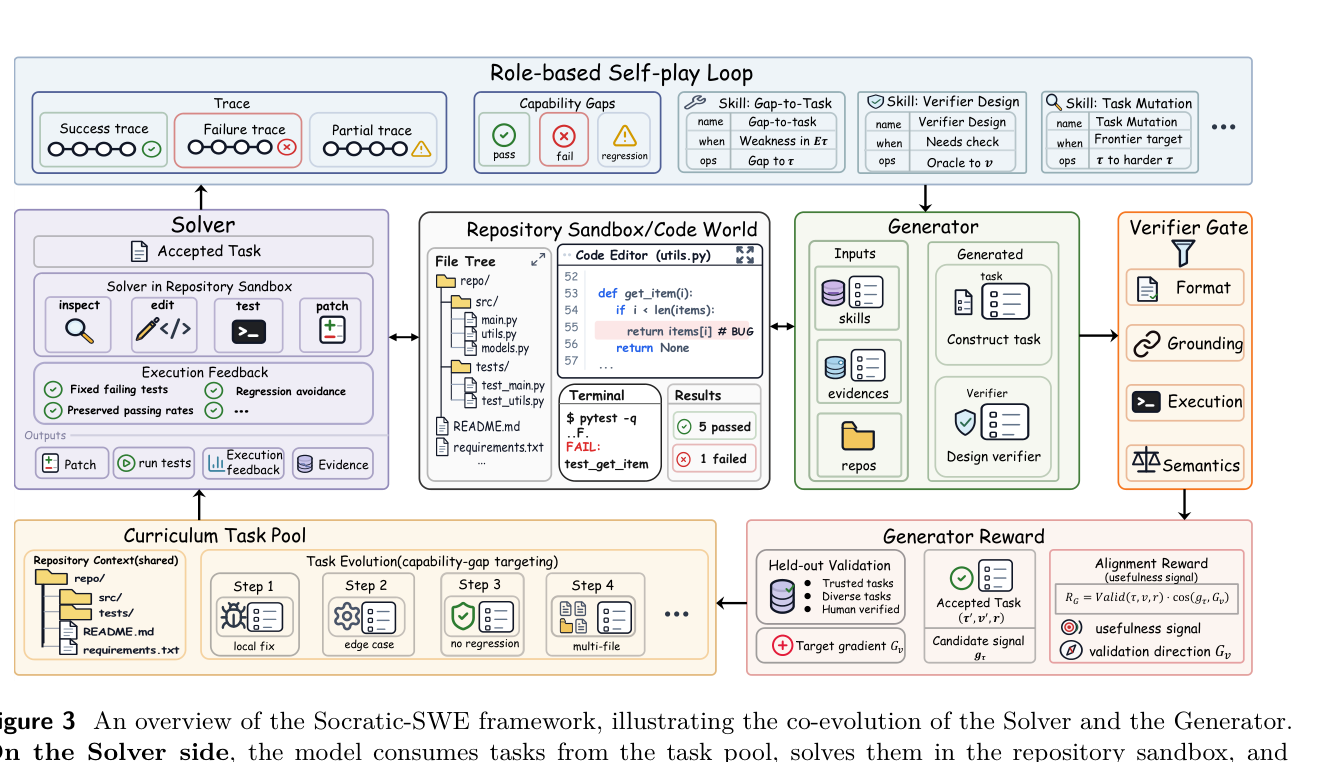
Figure 3 — 에이전트의 Solver와 Generator 간의 상호작용 및 스킬 추출, 검증 과정을 통합한 전체 아키텍처
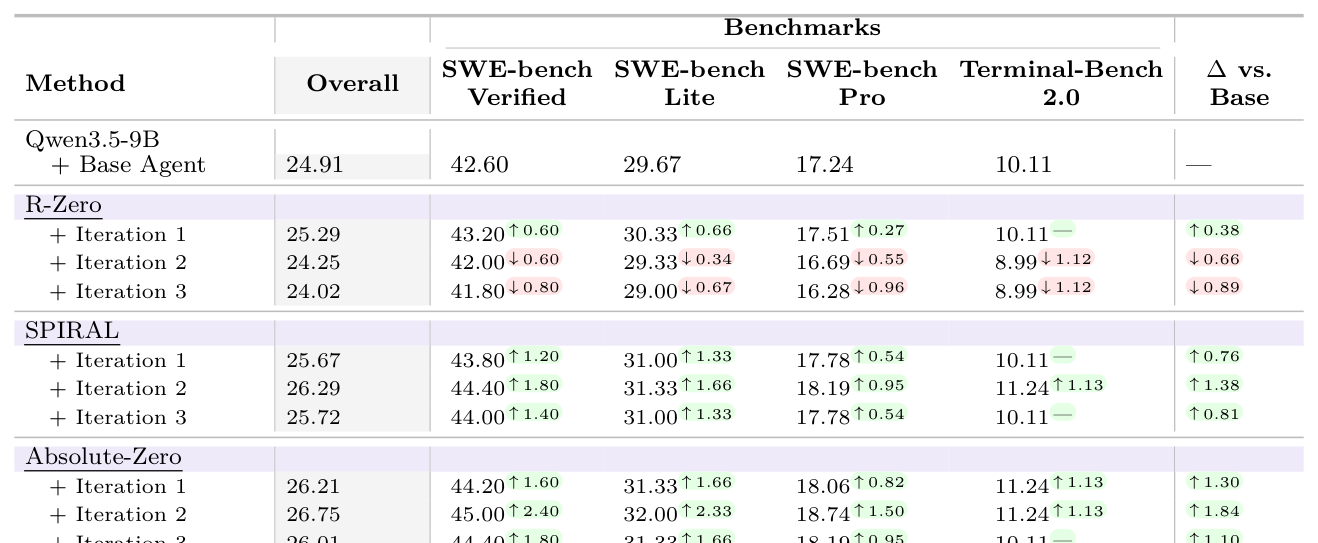
Table 1 — 제안 모델과 기존 베이스라인 모델들의 벤치마크 성능을 정량적으로 비교한 핵심 결과 테이블
## 4. Conclusion & Impact (결론 및 시사점) Socratic-SWE는 solving trace를 단순히 소비하는 자원이 아닌, 자기 진화를 위한 확장 가능한 기질(Scalable substrate)로 변환함으로써 SWE 에이전트 학습의 새로운 패러다임을 제시하였습니다. 본 연구는 정교한 스킬 증류와 gradient 정렬 기법을 결합하여, 데이터가 부족한 환경에서도 에이전트가 지속적으로 능력을 향상할 수 있음을 실험적으로 증명하였습니다. 이 프레임워크는 향후 소프트웨어 개발 환경에서의 자동화된 에이전트 설계 및 고도화 연구에 중대한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Training Long-Context, Multi-Turn Software Engineering Agents with Reinforcement Learning
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
Review 의 다른글
- 이전글 [논문리뷰] SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
- 현재글 : [논문리뷰] Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
- 다음글 [논문리뷰] Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors
댓글