[논문리뷰] Honest Lying: Understanding Memory Confabulation in Reflexive Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Prakhar Dixit, Sadia Kamal, Tim Oates
1. Key Terms & Definitions (핵심 용어 및 정의)
- Reflexion: 실패한 작업의 흔적(trajectory)을 바탕으로 LLM이 자연어로 자기 비평(self-critique)을 생성하고, 이를 향후 시도에 메모리로 활용하여 학습하는 프레임워크입니다.
- Memory Confabulation: 에이전트가 환경으로부터의 관찰 데이터와 모순되는 잘못된 내용을 자기 비평으로 생성하고, 이를 메모리로 저장하여 이후 시도에서도 지속적으로 실수를 반복하는 현상을 의미합니다.
- Reflection Repetition Rate (RRR): 메모리에 저장된 reflection들이 시간 경과에 따라 얼마나 유사하게 반복되는지를 측정하는 지표로, 수치가 높을수록 'Frozen Memory' 상태임을 나타냅니다.
- Frozen Environment: RRR 수치가 0.5 이상인 환경으로, 에이전트가 자기 비평의 내용을 수정하지 못하고 동일한 오류를 지속하는 상태를 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Reflexion과 같은 에이전트가 자가 생성한 피드백에 의존할 때 발생하는 'Memory Confabulation' 문제를 해결하고자 합니다. 기존 연구는 에이전트가 스스로 자신의 실패를 정확히 진단할 수 있다고 가정하지만, 저자들은 이 가정이 체계적으로 실패할 수 있음을 입증합니다. 특히 에이전트가 잘못된 정보를 자신 있게 저장하고 이를 반복적으로 실행함으로써, 환경이 올바른 정보를 제시함에도 불구하고 오류를 수정하지 못하는 현상을 발견했습니다. 이는 메모리가 오히려 학습을 저해하는 요인으로 작용할 수 있음을 시사합니다 [Figure 1].
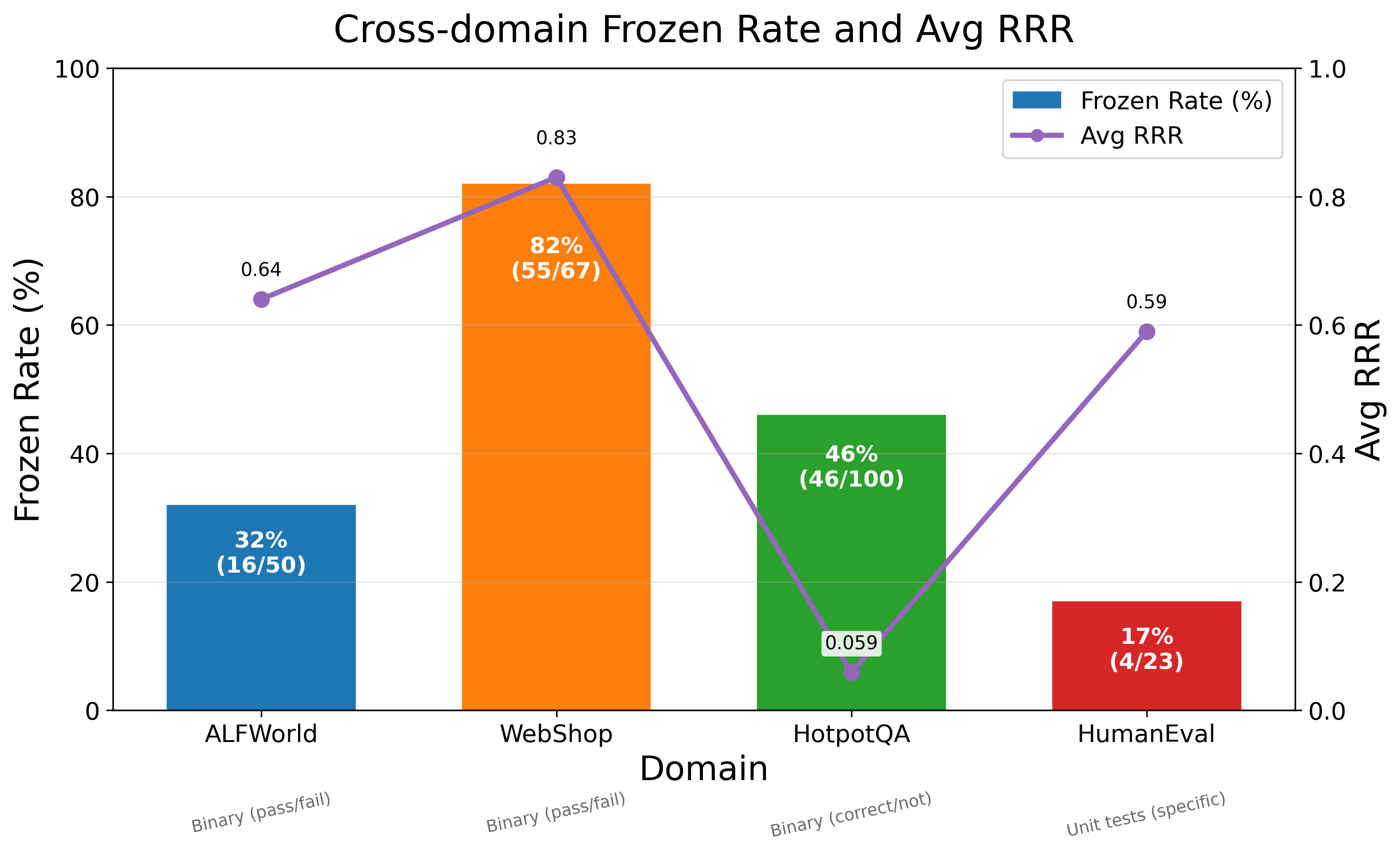
Figure 1 — 피드백 유형별 Frozen Rate
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 에이전트의 자기 진단을 대체하는 Programmatic Feedback Extraction 기법을 제안합니다. 이 방법은 에이전트가 모호한 자연어로 자가 비평을 생성하는 대신, trajectory를 파싱하여 구체적인 실패 단계(예: "Nothing happens" 응답 등)를 프로그래밍 방식으로 추출하여 프롬프트에 주입합니다. 이를 통해 ALFWorld 환경에서 올바른 타겟 객체 언급률을 0%에서 86%로 향상시켰으며, RRR을 0.64에서 0.10으로 대폭 낮추는 데 성공했습니다 [Figure 2]. 또한, HumanEval 도메인에서도 기존의 모호한 진단 대신 구체적인 오류 유형을 피드백으로 제공함으로써 Frozen Memory 현상을 개선함을 보였습니다. 결과적으로, 프로그램 기반 피드백은 모델의 capability gap과는 무관하게 confabulation을 방지하는 효과적인 기법임이 확인되었습니다.
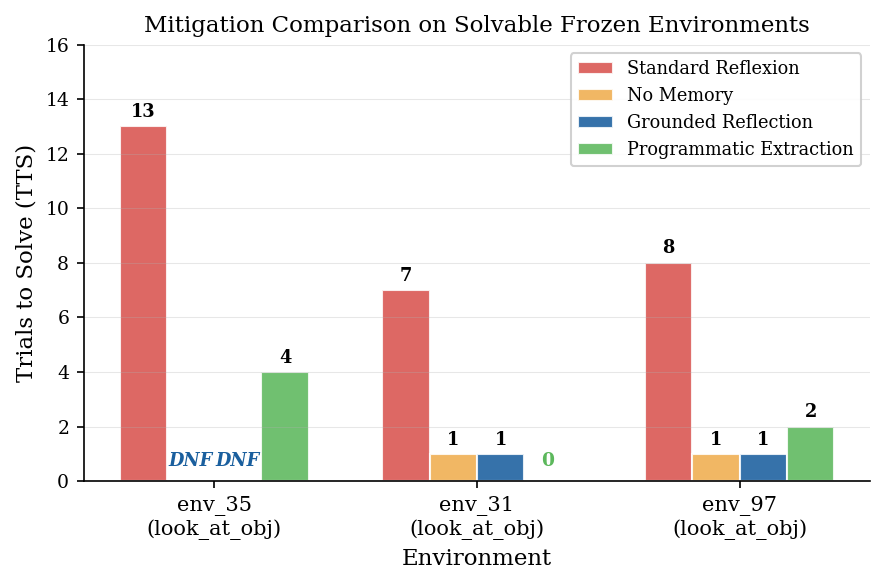
Figure 2 — 완화 기법별 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Reflexion 기반 에이전트가 잘못된 믿음을 메모리에 고착시키는 Memory Confabulation의 위험성을 증명하고, 이를 완화하기 위한 구조적 설계를 제안합니다. 연구 결과는 단순히 메모리 검색 품질을 높이는 것보다, 메모리에 무엇을(write-path validation) 저장할지 결정하는 과정이 에이전트의 신뢰성과 성능에 매우 중요함을 시사합니다. 향후 에이전트 메모리 설계 시, 무분별한 자가 생성 메모리보다는 신뢰성 있는 환경 피드백과 통합된 구조적 검증 기법을 도입해야 함을 강조합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
- [논문리뷰] EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
- [논문리뷰] Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Hardening Agent Benchmarks with Adversarial Hacker-Fixer Loops
- 현재글 : [논문리뷰] Honest Lying: Understanding Memory Confabulation in Reflexive Agents
- 다음글 [논문리뷰] Human Psychometric Questionnaires Mischaracterize LLM Behavior
댓글