[논문리뷰] Reasoning Arena: Trace Tournaments When Verifiable Rewards Fall Short
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
메타데이터
저자: Han Zhou, Adam X. Yang, Laurence Aitchison, Anna Korhonen, Albert Q. Jiang
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): Rule-based verifier가 제공하는 결과 기반 보상을 사용하여 LLM의 추론 능력을 향상시키는 강화학습 패러다임입니다.
- Non-diverse Reward Group: 샘플링된 그룹 내 모든 Trace가 verifier로부터 동일한 보상(전부 성공 또는 전부 실패)을 받아, 그룹 내 상대적 이점(Advantage)이 0이 되어 학습 신호를 제공하지 못하는 현상을 의미합니다.
- Trace Tournament: Non-diverse reward group 내의 Trace들을 Head-to-Head로 비교하여, 추론 품질의 세부 차이를 상대적인 보상 신호로 변환하는 메커니즘입니다.
- Bradley-Terry Model: 불완전한 비교 그래프로부터 객체 간의 상대적 강도(Latent log-strength)를 추정하기 위한 확률적 통계 모델입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 RLVR의 고질적인 문제인 Non-diverse reward group으로 인한 학습 신호 소실과 컴퓨팅 자원 낭비를 해결하는 것을 목표로 합니다. 기존의 GRPO와 같은 Group-relative policy optimization 방식은 그룹 내 보상 분산(Variance)에 의존하는데, 모델의 성능이 데이터 난이도와 맞지 않을 경우 대다수의 그룹이 All-correct 또는 All-incorrect 상태가 되어 경사 하강법에 필요한 Gradient 신호를 전혀 생성하지 못합니다 [Figure 1]. 이러한 그룹들은 학습 과정에서 완전히 폐기되며, 해당 Trace를 생성하는 데 투입된 막대한 컴퓨팅 비용이 낭비되는 비효율적인 상황이 발생합니다. 기존 연구들은 단순히 이러한 그룹을 필터링하거나 데이터 큐레이션을 통해 회피하려고 했으나, 이는 근본적인 해결책이 아니며 유용한 학습 잠재력을 포기하는 것과 같습니다.
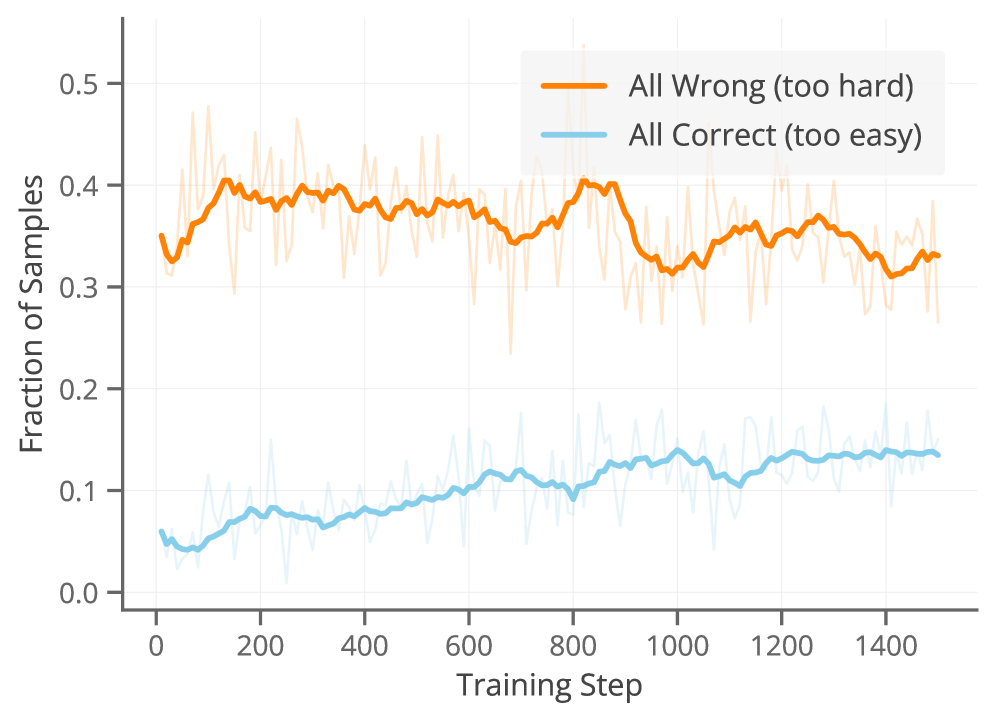
Figure 1 — Non-diverse reward group 발생 현황
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Non-diverse reward group을 실시간으로 감지하고 이를 Trace Tournament 시스템으로 동적으로 라우팅하는 Reasoning Arena 프레임워크를 제안합니다 [Figure 2]. 제안 방법론은 보상 다양성이 존재하는 그룹에는 기존의 RLVR을 그대로 적용하여 Verifier의 정확성을 보존하는 한편, Non-diverse 그룹에 대해서만 LLM Judge를 활용하여 Trace 간 비교를 수행합니다. 비교 효율성을 극대화하기 위해, 새로운 Trace를 전체와 비교하는 대신 실시간으로 업데이트되는 Anchor Trace(최상, 최악, 중간) 그룹과 비교하는 Live Tournament 전략을 도입하였습니다. 또한, 이 과정에서 발생하는 불완전한 비교 그래프를 Bradley-Terry 모델로 피팅하여 추론의 잠재적 강도(Latent log-strength)를 산출함으로써 O(N^2) 규모의 계산 복잡도를 O(N)으로 최적화하였습니다.
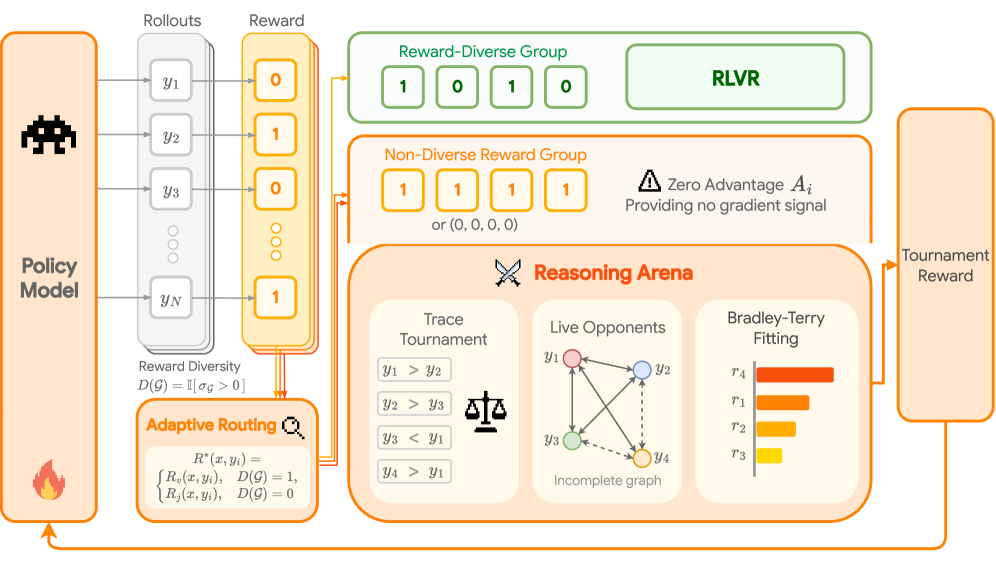
Figure 2 — Reasoning Arena 아키텍처
실험 결과, Reasoning Arena는 경쟁 수학 및 코드 벤치마크에서 RLVR 베이스라인 대비 평균 7.6% 성능 향상을 달성하였습니다 [Table 1]. 특히, 학습 효율성 측면에서 기존 대비 27%에서 41% 더 빠른 학습 속도를 보였으며, 불필요한 재샘플링 과정을 줄여 생성 단계의 컴퓨팅 자원을 약 50% 절감하는 성과를 거두었습니다 [Table 2, Figure 4]. 이러한 결과는 학습 중 버려지던 Non-diverse 샘플들이 Reasoning Arena를 통해 풍부한 Gradient 신호로 전환될 수 있음을 입증합니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Non-diverse reward group 문제에 대한 해법으로 적응형 라우팅과 Trace Tournament를 결합한 Reasoning Arena를 성공적으로 제시하였습니다. 이 연구는 Verifiable reward의 정확성과 LLM Judge의 유연성을 효과적으로 결합하여, 강화학습의 샘플 효율성과 학습 성능을 동시에 극대화했습니다. 향후 LLM의 고도화된 추론 능력 함양을 위한 RL 기반 학습 프레임워크 설계에 있어, 계산 비용을 최적화하면서도 정교한 학습 신호를 추출하는 핵심적인 방법론으로 자리매김할 것으로 기대됩니다.
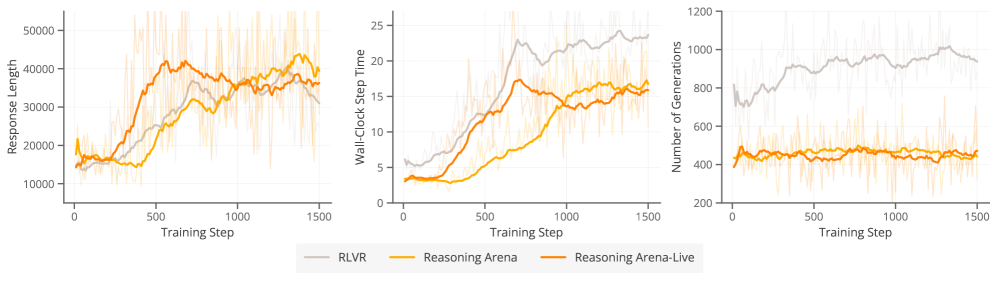
Figure 4 — 학습 효율성 및 생성 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] On the Geometry of On-Policy Distillation
- [논문리뷰] Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
- [논문리뷰] Rethinking Muon Beyond Pretraining: Spectral Failures and High-Pass Remedies for VLA and RLVR
- [논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
- [논문리뷰] DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
Review 의 다른글
- 이전글 [논문리뷰] Pruning and Distilling Mixture-of-Experts into Dense Language Models
- 현재글 : [논문리뷰] Reasoning Arena: Trace Tournaments When Verifiable Rewards Fall Short
- 다음글 [논문리뷰] Reasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
댓글