[논문리뷰] Pruning and Distilling Mixture-of-Experts into Dense Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Junhyuck Kim, Jihun Yun, Haechan Kim, Gyeongman Kim, Joonghyun Bae, Jaewoong Cho, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MoE (Mixture-of-Experts): 다수의 전문가(Expert) 모델 중 일부만을 활성화하여 연산 효율과 파라미터 확장성을 극대화하는 모델 아키텍처.
- MoE-to-Dense Conversion: 사전 학습된 MoE 모델의 전문가를 선택, 그룹화 및 결합하여 표준 Dense FFN(Feed-Forward Network) 구조로 변환하는 기법.
- D-Optimal Selection: Expert 선택 과정에서 중요도와 다양성을 동시에 고려하여, 중요도 가중치가 적용된 Gram Matrix의 로그 행렬식(log-determinant)을 최대화하는 선택 알고리즘.
- Knowledge Distillation (KD): MoE Teacher 모델의 출력을 학생 모델(Student)이 모방하도록 하여 압축 과정에서 손실된 성능을 복구하는 기법.
- Effective Rank: 선택된 전문가 세트가 생성하는 출력 공간의 독립적인 차원 수를 의미하며, 선택된 전문가들의 다양성을 정량화하는 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 MoE 모델의 높은 메모리 요구량으로 인해 발생하는 배포 제약 문제를 해결하기 위해, 전문가 기반 구조를 효율적인 Dense 모델로 변환하는 체계적인 프레임워크를 제안한다. 기존의 MoE 압축 연구들은 모델을 더 작은 MoE 형태로 만드는 데 그쳐, 추론 시 여전히 모든 전문가 파라미터를 메모리에 로드해야 한다는 근본적인 한계를 지닌다. 또한, 기존 Dense 모델 압축 방식인 Dense-to-Dense pruning은 MoE 모델이 보유한 풍부한 표현력을 충분히 활용하지 못한다는 단점이 있다. 저자들은 전문가들을 적절히 선택하고 병합한 뒤 Knowledge Distillation을 수행함으로써, 기존 Dense-to-Dense 방식보다 높은 정확도와 학습 효율을 달성하는 것을 목표로 한다 [Figure 1].
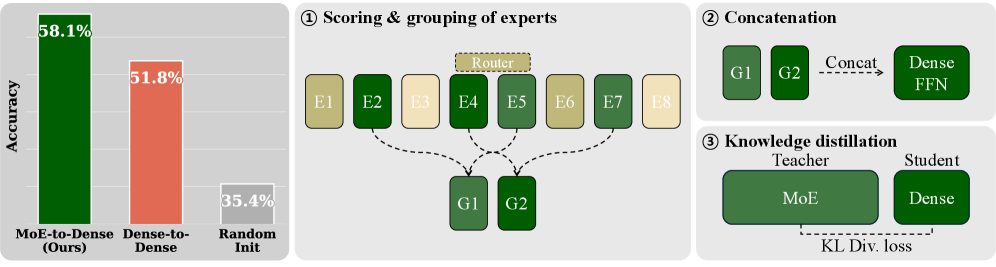
Figure 1 — 제안하는 MoE-to-Dense 변환 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구가 제안하는 MoE-to-Dense 프레임워크는 전문가 중요도 기반 스코어링, 선택, 그룹화 및 병합, 그리고 Knowledge Distillation의 3단계 과정을 거친다. 저자들은 7가지 스코어링 기법과 5가지 그룹화 전략을 실험하여 최적의 조합을 탐색하였다. 핵심적인 방법론인 DO-ACP는 D-Optimal 선택 기준과 활성화 가중치를 결합하여, 단순히 자주 선택되는 전문가가 아닌 정보량이 많고 상호 보완적인(diverse) 전문가들을 효과적으로 선택한다 [Figure 2], [Figure 3].
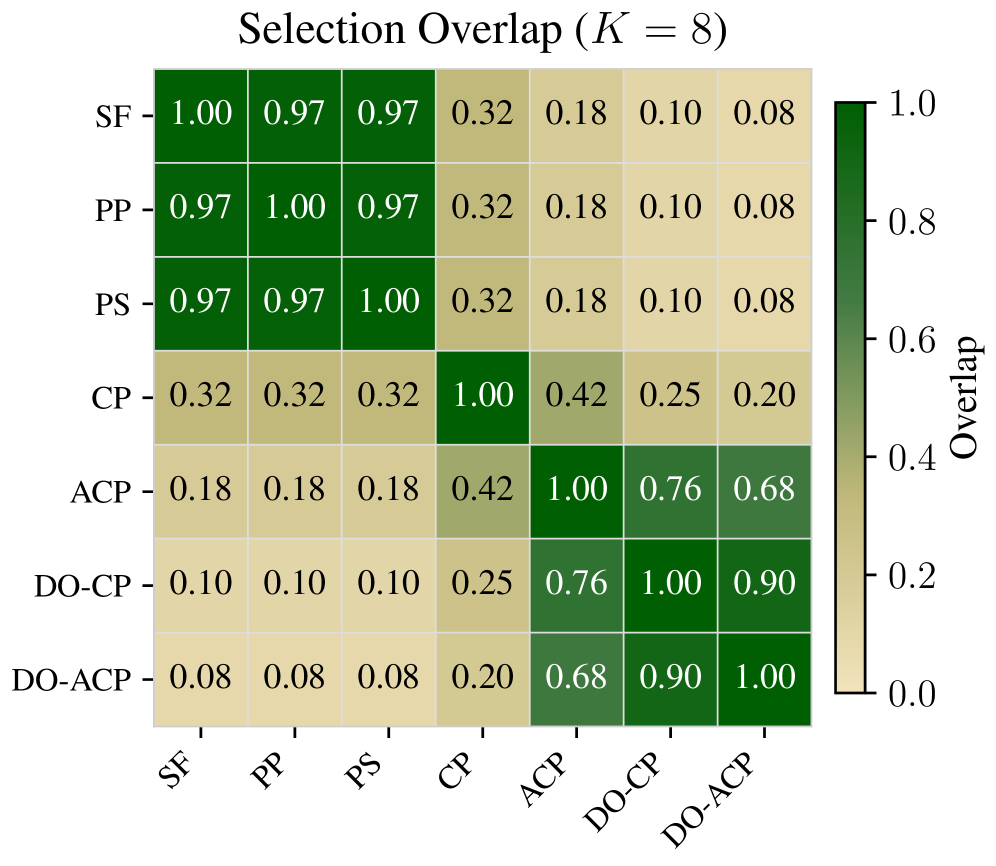
Figure 2 — 스코어링 기법별 전문가 선택 중첩도
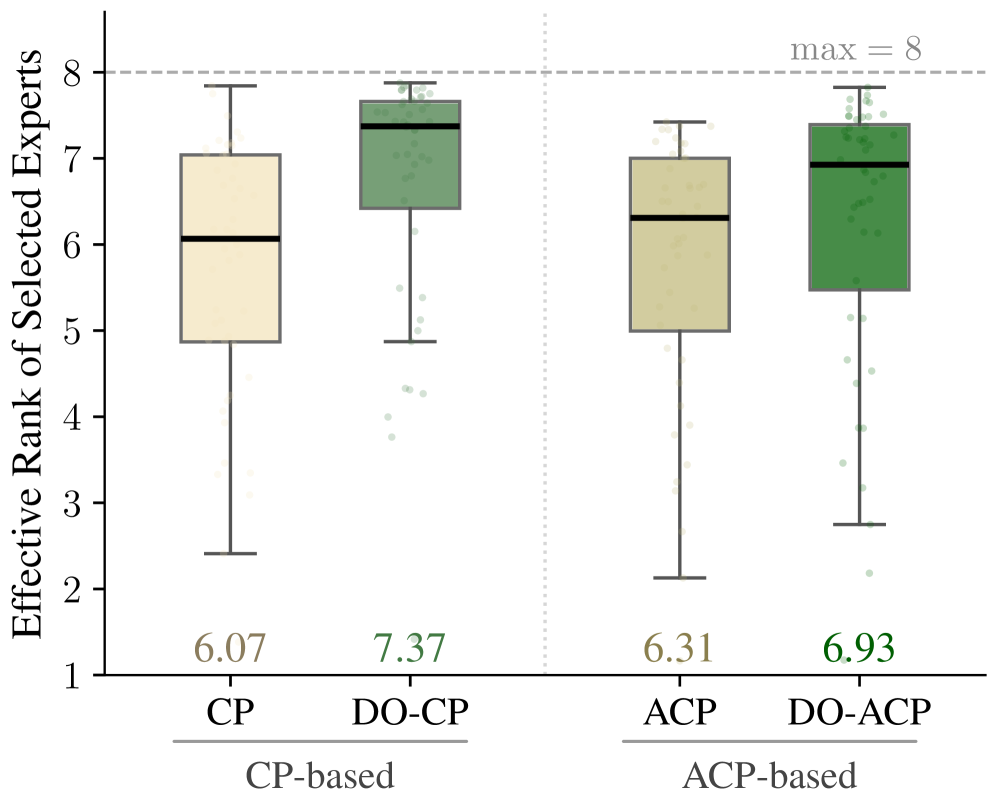
Figure 3 — 선택된 전문가 커널의 유효 랭크
정량적 실험 결과, DO-ACP 기반의 MoE-to-Dense 모델은 Qwen3-30B-A3B 모델에서 Dense-to-Dense pruning 기법 대비 평균 다운스트림 정확도에서 +6.3 pp 향상된 성능을 기록하였다. 또한, 약 4B-token distillation 과정에서 Dense-to-Dense 대비 1.6x 빠른 학습 속도를 보였다. 다양한 스코어링 기법 간 성능 차이는 최대 5.7 pp까지 나타나, 전문가 선택 전략이 전체 아키텍처 변환 품질을 결정짓는 핵심 요소임을 입증하였다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 최초로 MoE 모델을 Dense 모델로 효과적으로 변환하는 시스템적 프레임워크를 정립하였다. 제안된 D-Optimal 전문가 선택 기법은 모델 압축 분야에서 새로운 기준을 제시하며, DeepSeek-V2-Lite, GPT-OSS-20B 등 다양한 아키텍처에 걸쳐 그 범용성을 입증하였다. 이 연구는 메모리 제약이 심한 온디바이스 환경이나 실시간 배포 환경에서 최신 거대 MoE 모델의 성능을 유지하면서도 가벼운 Dense 모델을 사용할 수 있게 하는 중요한 가교 역할을 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] A Stationary (and Therefore Compatible) Representation is All You Need
- [논문리뷰] The Role of Feedback Alignment in Self-Distillation
Review 의 다른글
- 이전글 [논문리뷰] Phase Marginalization for Patch-Grid Instability in Vision Transformers
- 현재글 : [논문리뷰] Pruning and Distilling Mixture-of-Experts into Dense Language Models
- 다음글 [논문리뷰] Reasoning Arena: Trace Tournaments When Verifiable Rewards Fall Short
댓글