[논문리뷰] From 2D Grids to 1D Tokens: Reforming Shared Representations for Multimodal Image Fusion
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuchen Xian, Yunqiu Xu, Yang He, Yi Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- 1D Token Interface: 기존의 2D feature grid 대신 사용되는 compact 1D sequence로, 조도, 대비, perceptual tone과 같은 전역적(global) base factor를 모델링하는 핵심 제어 인터페이스입니다.
- STE (Selective Token Editing): 특정 appearance-sensitive token 위치를 식별하여 learnable offset을 적용함으로써, 전체적인 글로벌 외관(global appearance)을 효율적으로 제어하는 기법입니다.
- Token-to-Map Interface: compact 1D token 정보를 2D fusion backbone이 활용할 수 있는 공간적 feature map으로 재구성하는 연결 브리지 역할을 합니다.
- Base/Detail Factorization: 이미지의 정보 구성을 전역적 특성인 base와 국소적 특성인 detail로 분리하여, 각각 적합한 공간(token 또는 grid)에서 처리하도록 하는 프레임워크 설계 원칙입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Multimodal Image Fusion (MMIF) 기법들이 공유 표현(shared representation)으로 dense 2D feature grid를 사용함으로써 발생하는 구조적 한계를 해결합니다. 기존 방식은 전역적 base factor(예: 조도, 대비)를 spatial coordinate 전반에 걸쳐 암묵적으로 broadcast하기 때문에, 국소적 detail 및 노이즈와 표현이 뒤섞이는(entangled) 문제가 존재합니다 [Figure 1]. 이러한 2D 중심의 접근은 글로벌한 외관을 명시적으로 제어하기 어렵게 만들며, 분포 변화(distribution shift)에 따른 최적화 불안정성을 야기합니다. 따라서 저자들은 전역적 제어와 국소적 복원을 명확히 분리할 수 있는 새로운 표현 체계가 필요하다고 주장합니다.
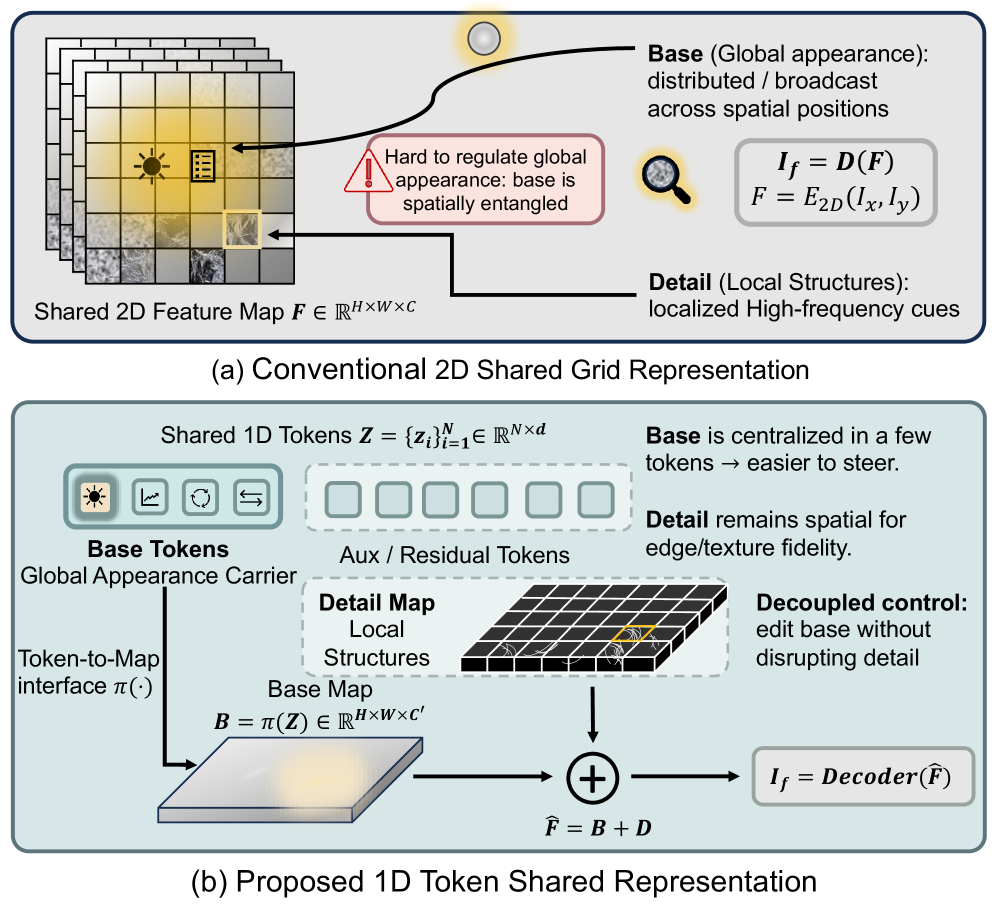
Figure 1 — 2D 그리드와 1D 토큰 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 frozen TiTok 기반의 1D token interface와 기존의 2D fusion backbone을 결합한 하이브리드 프레임워크를 제안합니다. 우선, 저자들은 입력 이미지를 1D token으로 변환하여 compact한 appearance carrier를 구성하고, Token-to-Map Interface를 통해 이를 2D 공간으로 투영하여 detail 처리용 2D 경로와 결합합니다 [Figure 2]. 특히 STE 기법을 적용하여 appearance에 민감한 특정 token 슬롯만을 선별적으로 편집함으로써, 복잡한 loss 설계 없이도 최적의 외관 정렬을 달성합니다. 두 단계(Reconstruction Warm-up 및 Fusion Training)에 걸친 학습 전략을 통해 모델의 안정적인 수렴을 유도합니다. 실험 결과, 본 방법론은 M3FD, RoadScene, TNO, Harvard 데이터셋에서 기존의 CDDFuse, DDFM 등의 모델 대비 EN, SD, SCD, SSIM 등 모든 주요 지표에서 가장 우수한 성능을 기록했습니다 [Table 1]. 또한, 객체 탐지 및 의미론적 분할과 같은 하위 태스크에서도 가장 높은 mAP와 mIoU를 달성하여 실제 시각적 정보 보존 능력을 입증했습니다 [Table 2], [Figure 3].
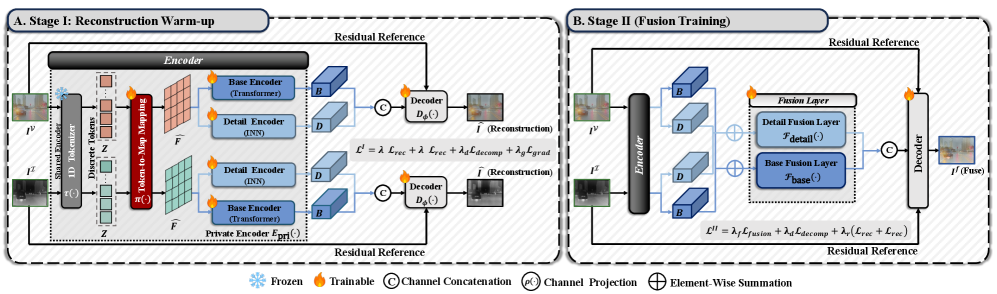
Figure 2 — 제안 모델의 2단계 학습 구조

Figure 3 — 데이터셋별 정성적 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 고차원 2D 그리드 중심의 공유 표현 패러다임에서 벗어나, compact한 1D token interface를 도입함으로써 MMIF의 효율적인 전역-국소 표현 분리를 실현했습니다. 제안된 STE 기법과 하이브리드 구조는 모델의 경량성을 유지하면서도, 조도 일관성과 상세 구조 보존 측면에서 SOTA 성능을 달성하였습니다. 이 연구는 저전력 센서 융합부터 의료 영상 처리에 이르기까지 전역적 문맥과 국소적 디테일이 동시에 요구되는 다양한 컴퓨터 비전 분야에 중요한 방법론적 토대를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Flash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
- 현재글 : [논문리뷰] From 2D Grids to 1D Tokens: Reforming Shared Representations for Multimodal Image Fusion
- 다음글 [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
댓글