[논문리뷰] Flash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
링크: 논문 PDF로 바로 열기
메타데이터
저자: Gal Bloch, Ariel Gera, Matan Orbach, Ohad Eytan, Assaf Toledo
1. Key Terms & Definitions (핵심 용어 및 정의)
- Flash-GMM: HBM(High Bandwidth Memory) 사용을 최소화하고 GPU 내 레지스터를 활용하는, Triton 기반의 메모리 효율적인 GMM(Gaussian Mixture Models) 추정 커널입니다.
- Responsibility Matrix: 데이터 포인트가 각 클러스터(Gaussian 성분)에 속할 확률을 담은 $N \times K$ 크기의 행렬로, 기존 구현체에서는 메모리 병목의 주원인입니다.
- IVF(Inverted File) Index: 데이터를 $K$개의 클러스터로 나누어 검색 범위를 제한하는 ANN(Approximate Nearest Neighbor) 검색 인덱스 구조입니다.
- DCO(Distance Computation Operations): 쿼리당 수행되는 거리 계산 횟수로, 검색 작업의 실제 연산 비용을 측정하는 핵심 지표입니다.
- IO-aware Tiling: 데이터 처리를 작은 타일 단위로 나누어 HBM 접근을 최소화하고 캐시 효율을 극대화하는 설계 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 데이터셋에 대한 GMM 훈련 시 발생하는 메모리 부족(OOM) 문제와 과도한 HBM 대역폭 요구 사항을 해결합니다. 기존의 GMM 구현체들은 모든 데이터 포인트에 대한 소속 확률을 나타내는 $N \times K$ 크기의 Responsibility Matrix를 메모리에 실체화(Materialize)해야 하므로, 데이터셋 규모가 커질수록 GPU 메모리 한계를 빠르게 초과합니다 [Table 1]. 이러한 메모리 병목 현상은 고성능 GPU의 연산 처리 능력을 온전히 활용하지 못하게 하며, 대규모 데이터셋을 위한 실제 산업 환경에서 GMM의 도입을 저해하는 핵심 요인입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Flash-GMM이라는 Triton 기반의 융합 커널을 제안하여, $N \times K$ 행렬을 메모리에 실체화하지 않고도 GMM 훈련을 수행합니다 [Table 2]. 저자들은 FlashAttention과 유사한 IO-aware 타일링 전략을 EM(Expectation-Maximization) 알고리즘에 적용하여, 데이터 타일마다 통계량을 계산하고 전역적으로 누적하는 방식을 채택했습니다. 이 접근법은 메모리 사용량을 데이터셋 규모($N$)와 무관한 $\mathcal{O}(KD)$ 수준으로 유지하며, GPU HBM 접근을 최소화하여 성능을 최적화합니다 [Figure 1].
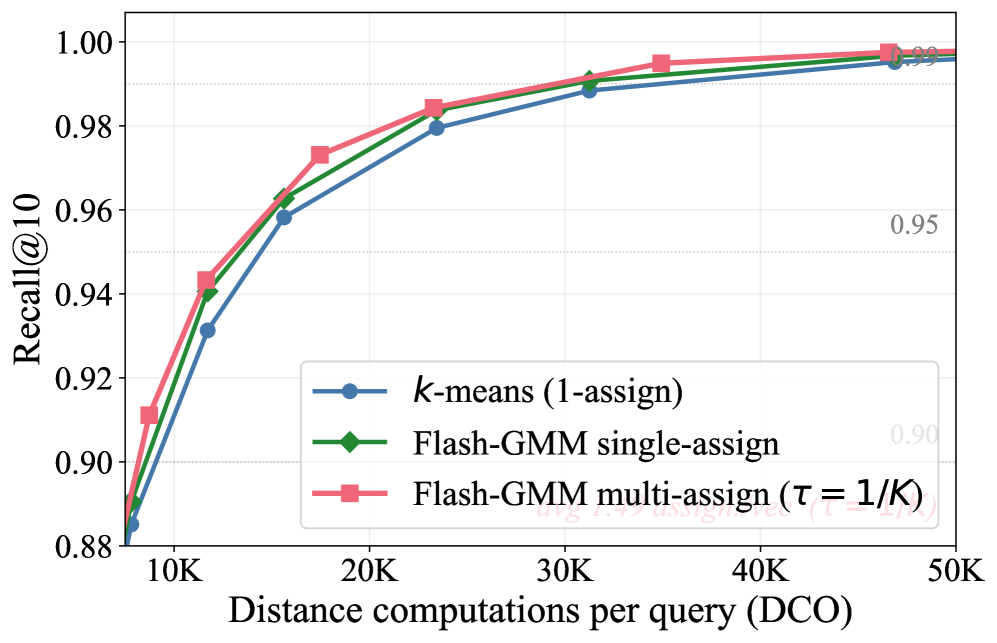
Figure 1 — 데이터셋별 Recall-DCO 파레토 곡선
성능 평가 결과, Flash-GMM은 기존 GPU 구현체인 TorchGMM 대비 최대 32배, CPU 기반 SciPy 구현체 대비 최대 1,740배의 속도 향상을 달성했습니다 [Table 1]. 또한, IVF coarse quantizer에 이를 적용하여, 고정된 Recall@10 타겟 기준 기존 K-Means 대비 최대 1.7배 적은 거리 계산(DCO)으로 동일 성능을 달성하거나, 동일 연산 비용 하에서 +2~12%의 Recall 개선을 확인했습니다 [Figure 1].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 메모리 효율적인 Flash-GMM 커널을 통해 그동안 대규모 데이터셋에서 불가능했던 GMM 기반의 소프트 클러스터링을 실현했습니다. 특히 IVF 인덱싱에 적용하여 검색의 품질과 효율성을 동시에 높일 수 있음을 입증했으며, 이는 ANN 검색 엔진의 성능을 한 단계 도약시키는 중요한 기여를 합니다. 향후 Flash-GMM은 확률적 모델링이 필요한 다양한 도메인과 대규모 인덱싱 시스템 전반에서 유연하고 강력한 대체 솔루션으로 자리매김할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AgentKernelArena: Generalization-Aware Benchmarking of GPU Kernel Optimization Agents
- [논문리뷰] Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
- [논문리뷰] Scaling DoRA: High-Rank Adaptation via Factored Norms and Fused Kernels
- [논문리뷰] Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
Review 의 다른글
- 이전글 [논문리뷰] FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
- 현재글 : [논문리뷰] Flash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
- 다음글 [논문리뷰] From 2D Grids to 1D Tokens: Reforming Shared Representations for Multimodal Image Fusion
댓글