[논문리뷰] Risk Under Pressure: Compute-Aware Evaluation of Adversarial Robustness in Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Malikeh Ehghaghi, Boglárka Ecsedi, Marsha Chechik, Colin Raffel
1. Key Terms & Definitions (핵심 용어 및 정의)
- Computational Pressure: 공격자가 모델을 우회(jailbreak)하기 위해 소비하는 누적 FLOPs(floating-point operations)를 의미하며, 공격의 실질적인 비용을 나타내는 지표입니다.
- Risk-Compute Curves: 고정된 쿼리 예산 대신, 누적 계산량(FLOPs)에 따른 공격 성공 확률(Risk)의 변화를 시각화한 곡선입니다.
- C@τ (Compute to τ%-risk): 공격자가 특정 비율(τ)의 위험 수준에 도달하는 데 필요한 평균적인 누적 FLOPs입니다.
- AE (Average Efficiency): 누적 FLOPs당 얻어지는 평균 위험(risk)으로, 공격의 효율성을 측정합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 언어 모델(LLM)의 안전성 평가가 고정된 쿼리 예산(fixed query budget)에 의존함에 따라 발생하는 심각한 정보 왜곡 문제를 해결하고자 합니다. 기존 연구들은 다양한 공격 방식의 계산 비용 차이를 무시하고 오직 공격 성공률(ASR)만을 보고하기 때문에, 공격자가 실제 모델을 뚫기 위해 투입해야 하는 '노력의 총량'을 과소평가하거나 왜곡합니다 [Figure 1]. 이러한 방식은 방어자 입장에서 실제 위협 수준을 판단하기 어렵게 만들며, 비용 효율적인 공격 전략의 위험성을 은폐합니다. 따라서 본 연구는 모델의 안전성을 정량적인 '작업 요소(work factor)'인 계산량 기반으로 재평가해야 한다고 주장합니다.
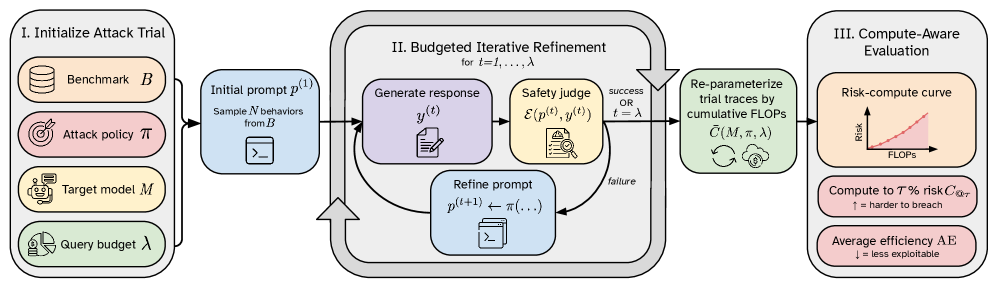
Figure 1 — 계산 기반 평가 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 다양한 공격 전략(GCG, PAIR, JailBroken)을 동일한 계산 축인 FLOPs상에서 비교할 수 있는 Risk-Compute 평가 프레임워크를 제안합니다 [Figure 1]. 실험 결과, 모델의 Alignment 과정이 계산 공간에서의 견고성에 비단조적인(non-monotonic) 영향을 미침을 확인했습니다. Tulu3 모델 분석 결과, SFT 단계에서 가장 높은 견고성을 보였으나 이후 DPO나 RLVR 단계를 거치며 오히려 Computational Pressure가 낮아지는 퇴보 현상이 발생했습니다 [Figure 2]. 또한 모델 규모(model size)가 커질수록 GCG와 같은 고비용 공격에는 효과적으로 대응하지만, JailBroken과 같은 저비용 템플릿 공격에는 성능 향상이 제한적임을 입증했습니다 [Figure 3]. Safety-RL은 전체적인 공격 비용을 상승시키나, 특정 범죄 카테고리에서는 오히려 효율성을 높이는 역효과를 초래할 수 있음을 정량적 수치로 확인했습니다 [Figure 5, Figure 6].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 FLOPs 기반의 Compute-Aware 평가 방식이 기존 ASR 중심의 평가 체계가 놓치고 있는 모델의 실질적인 취약점과 공격 비용의 비대칭성을 명확히 드러낸다고 결론짓습니다. 본 연구는 학계의 안전성 평가를 단순한 '성공 여부' 중심에서 '공격 비용(work factor)' 중심의 현실적인 보안 관점으로 전환할 것을 제안합니다. 제안된 프레임워크는 향후 더 견고한 모델 설계와 효과적인 안전성 튜닝을 위한 표준 지표로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Emergent Misalignment Can Be Induced by Sycophancy and Reversed via Alignment Gating
- [논문리뷰] Hardening Agent Benchmarks with Adversarial Hacker-Fixer Loops
- [논문리뷰] Safety Alignment as Continual Learning: Mitigating the Alignment Tax via Orthogonal Gradient Projection
- [논문리뷰] SafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
- [논문리뷰] Empirical Evidence for Simply Connected Decision Regions in Image Classifiers
Review 의 다른글
- 이전글 [논문리뷰] Revisiting Articulated Parts Perception in Robot Manipulation
- 현재글 : [논문리뷰] Risk Under Pressure: Compute-Aware Evaluation of Adversarial Robustness in Language Models
- 다음글 [논문리뷰] Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?
댓글