[논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haoran Xu, Hongyu Wang, Yifei Gao, Jiaze Li, Zizhao Tong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual Para-Thinker++: 단일 MLLM(Multimodal Large Language Model) 정책을 Main, Worker, Summary Agent라는 세 가지 역할로 세분화하여 병렬적 시각 추론을 수행하는 프레임워크입니다.
- Role-Decoupled Multi-Agent Optimization: 각 에이전트의 역할별 보상(Reward)과 이점(Advantage)을 분리하여 토큰 세그먼트별로 최적화함으로써, 다중 에이전트 협업 시 발생하는 그래디언트 충돌을 방지하는 학습 기법입니다.
- Native Multi-Agent Inference Engine:
vLLM기반의 추론 엔진으로, 시각적 프리픽스(Visual Prefix)와 KV Cache를 공유하여 다중 에이전트 환경에서도 효율적인 롤아웃을 가능하게 합니다. - Context-Isolation Mask: Worker Agent들이 상호 간의 추론 과정에 영향을 받지 않도록 독립성을 보장하는 마스크 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 단일 체인 추론(Single-chain Reasoning) 방식이 시각적 추론 과정에서 범하는 조기 지각적 확신(Early Perceptual Commitment)과 환각(Hallucination) 문제를 해결하기 위해 고안되었습니다. 기존의 MLLM들은 단일 궤적 안에서 정답을 도출하려 하므로, 초기 단계의 오류가 전체 추론의 오류로 직결되는 한계가 있습니다. 또한, 독립적인 여러 모델을 사용하는 멀티 에이전트 방식은 연산 비용이 막대하다는 단점이 있습니다. 본 연구는 이를 극복하기 위해 단일 정책 기반의 효율적인 멀티 에이전트 협업 시스템을 구축하고자 합니다 [Figure 1].
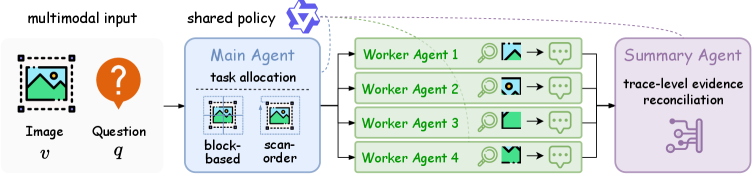
Figure 1 — Visual Para-Thinker++ 전체 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 공유된 단일 MLLM 정책을 역할 토큰(Role Tokens)을 통해 Main, Worker, Summary Agent로 인스턴스화하는 단일 정책 멀티 에이전트 프레임워크를 제안합니다. Main Agent는 Block-based 또는 Scan-order 패턴을 통해 시각적 작업을 할당하고, 여러 Worker Agent는 고립된 컨텍스트 내에서 독립적으로 추론을 수행하며, 마지막으로 Summary Agent가 이들을 종합하여 최종 답변을 생성합니다 [Figure 1], [Figure 2]. 학습 과정에서는 Multi-Agent Capability Injection을 통해 역할을 부여하고, Role-Decoupled Multi-Agent Optimization을 사용하여 각 에이전트의 세그먼트에 맞는 보상을 차등 적용함으로써 그래디언트 최적화를 수행합니다 [Figure 3].
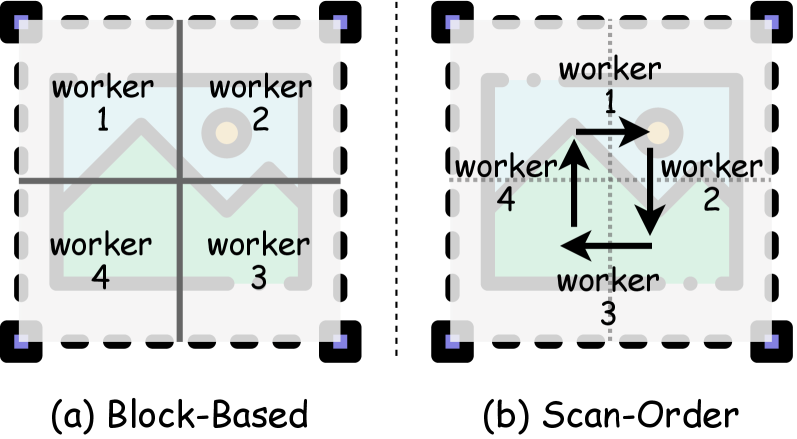
Figure 2 — Main Agent의 두 가지 작업 할당 패턴
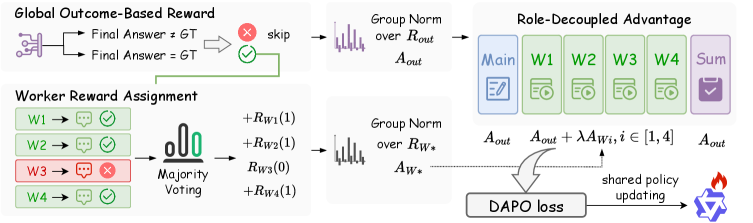
Figure 3 — Role-Decoupled 학습 파이프라인
실험 결과, 제안 모델인 **Visual Para-Thinker++*는 다양한 시각적 벤치마크에서 기존의 Single-trajectory 및 병렬 추론 베이스라인을 압도하는 성능을 보였습니다. 3B 모델 스케일에서, 시각적 인식 및 환각 방지 지표의 평균 정확도를 기존 베이스라인 대비 약 13.5% 향상시켰습니다 [Table 1]. 특히, 조기 오류가 치명적인 Pixmo-test 및 V 벤치마크에서 각각 +17.9%, +16.7%의 유의미한 성능 개선을 달성했습니다 [Table 1]. 또한, 추론 엔진의 KV Cache 재사용 기술을 통해 효율성을 극대화하여, 처리량(Throughput)을 기존 방식 대비 크게 향상시켰습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 단일 정책 기반의 멀티 에이전트 프레임워크를 통해 시각적 추론의 신뢰성을 크게 향상시켰습니다. 이 연구는 복잡한 시각적 근거 통합이 필요한 작업에서 멀티 에이전트 협업이 단일 모델의 한계를 극복하는 핵심 동력임을 입증하였습니다. 특히, 역할 분담과 최적화의 decoupling 전략은 대규모 모델의 연산 비용을 효율적으로 유지하면서도 추론 능력을 극대화할 수 있는 새로운 이정표를 제시하였습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Optical Reasoning: Rethinking Images as an Expressive Reasoning Medium Beyond Text
- [논문리뷰] TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- [논문리뷰] Visual Reasoning through Tool-supervised Reinforcement Learning
- [논문리뷰] OpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks
Review 의 다른글
- 이전글 [논문리뷰] VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
- 현재글 : [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
- 다음글 [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
댓글