[논문리뷰] MVEB: Massive Video Embedding Benchmark
링크: 논문 PDF로 바로 열기
저자: Adnan El Assadi, Roman Solomatin, Isaac Chung, Chenghao Xiao, Deep Shah, Manan Dey, Shriya Sudhakar, Zacharie Bugaud, Wissam Siblini, Ayush Sunil Munot, Yashwanth Devavarapu, Rakshitha Ireddi, Michelle Yang, Márton Kardos, Niklas Muennighoff, Kenneth Enevoldsen
1. Key Terms & Definitions (핵심 용어 및 정의)
- MVEB (Massive Video Embedding Benchmark): 비디오 임베딩 모델의 일반 목적 성능을 평가하기 위해 제안된 23개 Task로 구성된 Benchmark입니다. Classification, Zero-Shot Classification, Clustering, Pair Classification, Retrieval, Video-Centric Question Answering을 포함합니다.
- MTEB (Massive Text Embedding Benchmark): 텍스트 임베딩을 위한 기존 Benchmark Ecosystem으로, MVEB는 이 Ecosystem의 비디오 확장판입니다.
- MLLM (Multimodal Large Language Model): Text, Image, Audio, Video 등 다양한 Modality의 입력을 처리하고 이해할 수 있는 Large Language Model입니다.
- AV-grounded datasets: Label이 Audio 및 Visual Content(예: Audio-Visual event labels, Dialogue-Emotion labels) 모두에서 생성된 Dataset을 의미합니다.
- V-grounded datasets: Label이 Visuals alone(예: Action-Recognition splits, Frame-conditioned captioning)에서 생성된 Dataset을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 비디오 벤치마크는 단일 Task에 초점을 맞추어 모델의 일반 목적 비디오 표현 품질을 평가하기 어렵게 만들며, 이는 fragmented landscape를 초래합니다. 기존의 비디오 벤치마크들은 대부분 특정 기능(예: action recognition, retrieval)에 집중하거나, Visual-only, Retrieval-only, 또는 단일 long-video retrieval Task에 국한되어 있습니다. 특히, 이전 벤치마크들은 Audio와 Video의 Joint Input을 평가하는 표준화된 프로토콜이 부족하여, Audio가 Video 이해에 어떻게 기여하는지 직접적으로 측정할 수 없었습니다. 이러한 한계점으로 인해 모델이 특정 Task에 과적합되었는지, 아니면 General-Purpose 비디오 표현 능력이 우수한지 판단하기 어려운 문제가 있습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 이러한 문제를 해결하기 위해 MVEB를 도입합니다. MVEB는 **MVEB+**라는 184개 Task Pool에서 선별된 23개 Task로 구성되며, Task Diversity를 유지하면서 평가 비용을 줄이도록 설계되었습니다. MVEB는 Classification, Zero-Shot Classification, Clustering, Pair Classification, Retrieval(8가지 Modality Direction), Video-Centric Question Answering의 6가지 Task Family로 Task를 분류합니다. 특히, MVEB는 모든 Audio-bearing Dataset을 Video-only 및 Video+Audio Variants와 Pair로 구성하여, Audio가 Video 이해를 어떻게 개선하는지 직접 측정할 수 있도록 합니다. 이는 MTEB ecosystem에 통합되어 Text, Image, Audio, Video 전반에 걸친 통합 평가를 가능하게 합니다.
33개 모델을 6가지 임베딩 Paradigm에 걸쳐 평가한 결과, 다음과 같은 핵심 결과를 도출했습니다:
- No single model dominates: 단일 모델이 모든 Task에서 지배적인 성능을 보이지 않았습니다. [Table 3], [Figure 2]
- MLLM-based embedding 모델(예: LCO-Embedding-Omni-7B)은 Classification, Clustering, Pair Classification, QA Task에서 가장 우수한 성능을 보였습니다. 특히, LCO-Embedding-Omni-7B는 57.6의 Mean Score로 Overall Rank 1위를 차지했으며, QA 및 Clustering에서 가장 강력한 모델입니다.
- Multimodal binding 모델(예: eBind)은 Retrieval 및 Zero-Shot Classification에서 강점을 보였습니다. eBind는 Retrieval에서 62.3, Zero-Shot Classification에서 61.1의 높은 점수를 기록하며 이 두 Category에서 선두를 차지했습니다.
- Generative MLLM을 Embedder로 사용하고 Contrastive Adaptation이 없는 경우, Cross-Modal Task에서 성능이 현저히 저하되었습니다. 예를 들어, Qwen2.5-Omni-7B는 MVEB에서 12.8의 Mean Score를 기록하여 동급 MLLM-embed 모델 대비 한 자릿수 이상 낮은 성능을 보였습니다. [Table 3]
- Audio의 기여는 Dataset Annotation provenance에 따라 달라집니다. AV-grounded datasets(Label이 Audio 및 Visual Modality 모두에서 생성됨)에서는 Audio가 도움이 되지만, V-grounded datasets(Label이 Visuals alone에서 생성됨)에서는 Audio가 성능을 저해하여 6점 차이의 일관된 격차를 보였습니다.
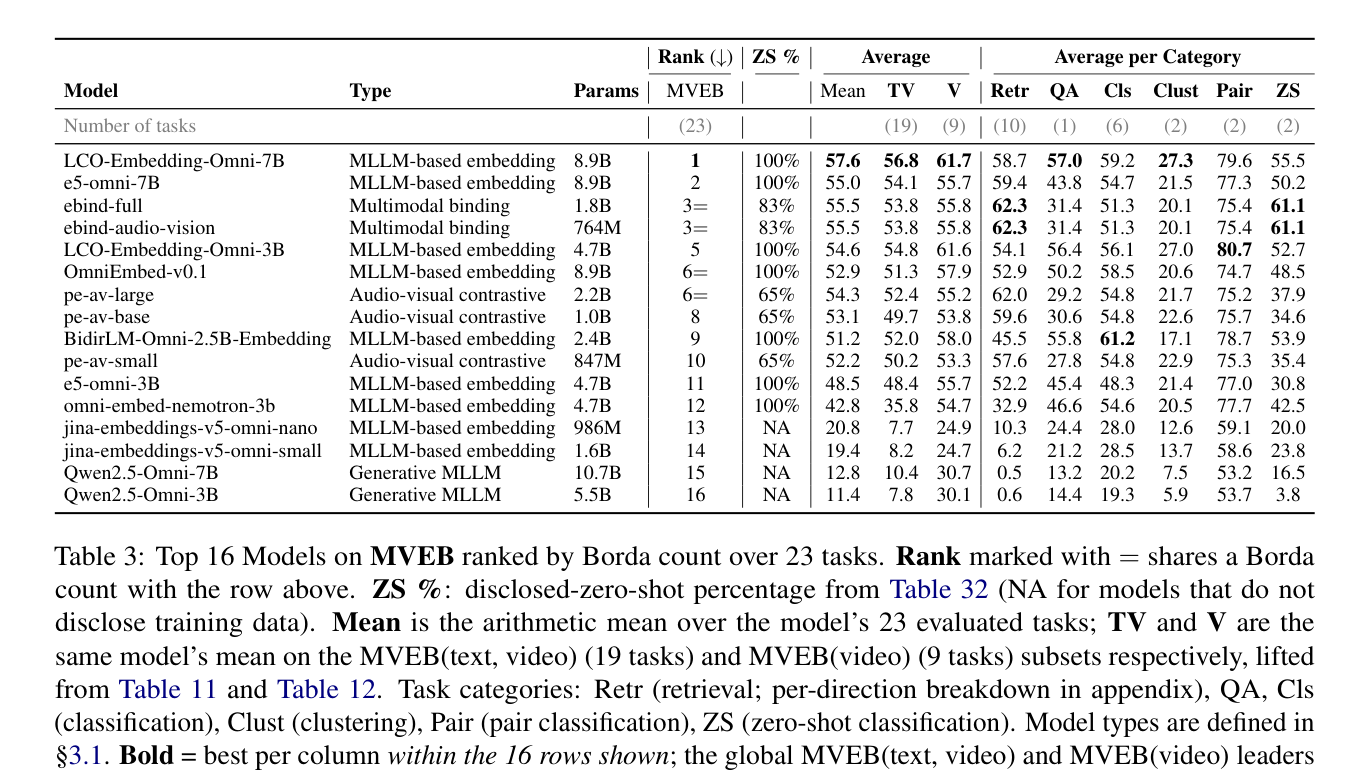
Table 3 — MVEB 벤치마크의 주요 Leaderboard로, 각 모델의 Mean 성능과 Category별 성능을 정량적으로 비교하는 핵심 결과 테이블
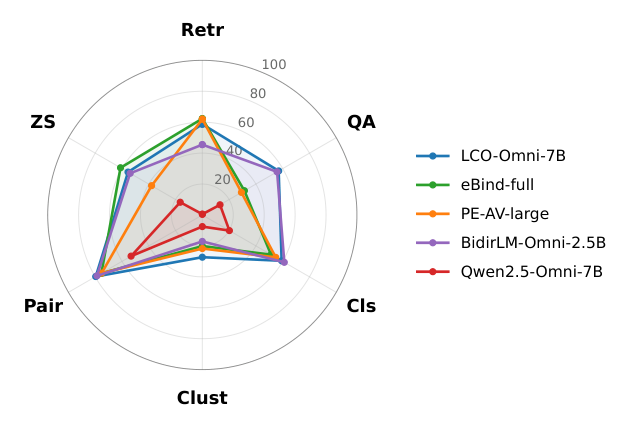
Figure 2 — 대표 모델들의 Category별 Mean Score를 시각적으로 보여주며, 각 모델의 강점과 약점, 특히 Generative MLLM의 성능 저하를 명확히 보여주는 그래프
4. Conclusion & Impact (결론 및 시사점)
MVEB는 Classification, Zero-Shot Classification, Clustering, Pair Classification, Retrieval, Video-Centric Question Answering을 아우르는 23개 Task의 통합 비디오 임베딩 Benchmark를 제공합니다. 이 Benchmark는 Multimodal Large Language Model(MLLM) 기반 임베딩 모델, Multimodal Binding 모델, Audio-Visual Contrastive 모델 등 주요 임베딩 Paradigm에 걸쳐 33개 모델을 평가합니다. 연구 결과, 단일 모델이 모든 Task를 지배하지 않으며, Audio의 기여가 Dataset Annotation provenance에 따라 달라진다는 점(AV-grounded vs. V-grounded datasets에서 6점 차이)을 밝혀냈습니다. 또한, Contrastive Embedding Stage가 Cross-Modal Performance의 거의 필수적인 전제 조건이며, Backbone Scale보다 Training Data Alignment가 Cross-Modal Task에 더 중요하다는 점을 시사합니다.
MVEB는 MTEB ecosystem에 통합되어 Task 및 Model Versioning, Community-driven Contribution 및 Long-term Maintenance를 지원함으로써, 비디오 임베딩 분야의 지속적인 발전과 연구의 재현성을 위한 표준 플랫폼을 제공할 것으로 기대됩니다. 이는 연구자들이 General-Purpose 비디오 임베더를 개발하고 평가하는 데 필요한 Actionable Findings를 제공하여, 미래 비디오 이해 기술의 발전에 중요한 이정표가 될 것입니다.
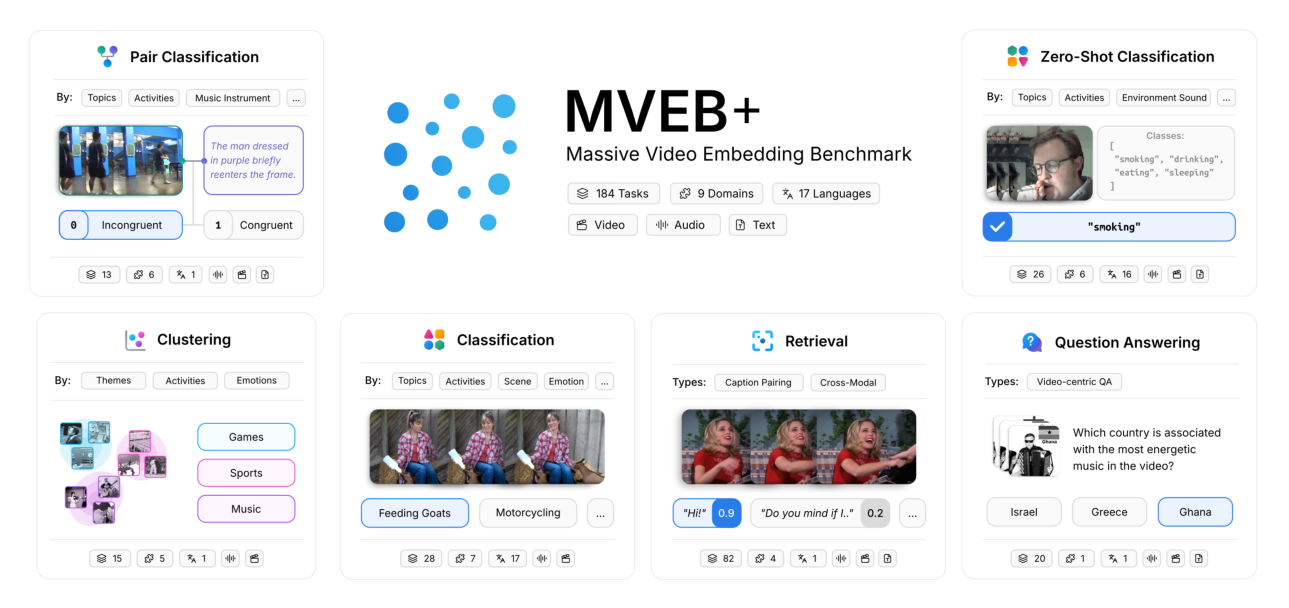
Figure 1 — MVEB 벤치마크가 포함하는 6가지 Task Family와 각 Subtype의 예시를 시각적으로 보여주는 핵심 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks
- [논문리뷰] GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
- [논문리뷰] UniREditBench: A Unified Reasoning-based Image Editing Benchmark
- [논문리뷰] The Quest for Generalizable Motion Generation: Data, Model, and Evaluation
- [논문리뷰] ChartAB: A Benchmark for Chart Grounding & Dense Alignment
Review 의 다른글
- 이전글 [논문리뷰] MMDiff: Extending Diffusion Transformers for Multi-Modal Generation
- 현재글 : [논문리뷰] MVEB: Massive Video Embedding Benchmark
- 다음글 [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
댓글