[논문리뷰] Unstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
링크: 논문 PDF로 바로 열기
저자: Gleb Gerasimov, Timofei Rusalev, Nikita Balagansky, Daniil Laptev, Vadim Kurochkin, Daniil Gavrilov
1. Key Terms & Definitions (핵심 용어 및 정의)
- Sparse Autoencoders (SAEs): LLM의 hidden states를 sparse한 선형 조합(feature)으로 분해하여 해석 가능성을 높이는 기법입니다.
- Feature Stability: 서로 다른 random seed로 학습된 여러 SAE 사이에서 동일한 feature가 재발현(reappear)되는 확률을 의미합니다.
- Stable vs. Unstable Features: Feature의 재발현 확률이 특정 임계값(
ε=0.05)을 기준으로 높으면 stable, 낮으면 unstable로 분류합니다. - Decoder Subspaces: Decoder weight matrix의 열(column)들이 구성하는 벡터 공간으로, unstable feature들이 개별적으로는 재발현되지 않아도 특정 저차원 공간 내에 존재함을 분석하는 대상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 독립적인 random seed로 학습된 SAE들이 왜 서로 다른 feature 세트를 학습하는지, 즉 feature의 비재현성(non-reproducibility) 문제를 해결하고자 합니다. 기존 연구들은 SAE의 불안정성을 지적해왔으나, 개별 feature가 사라진 것인지 아니면 단순히 다른 basis로 표현된 것인지에 대한 기하학적 근거가 부족했습니다. 또한, 자동 해석(automatic interpretation) 도구가 비결정론적 설정에서도 그럴듯한 설명을 생성할 수 있다는 점은 어떤 feature가 진정한 '단위'인지 파악하기 어렵게 만듭니다. 저자들은 개별 feature의 재발현 확률을 추정하여, 불안정한 feature들이 단순 노이즈인지 아니면 재현 가능한 저차원 구조의 일부인지 규명합니다 [Figure 1].
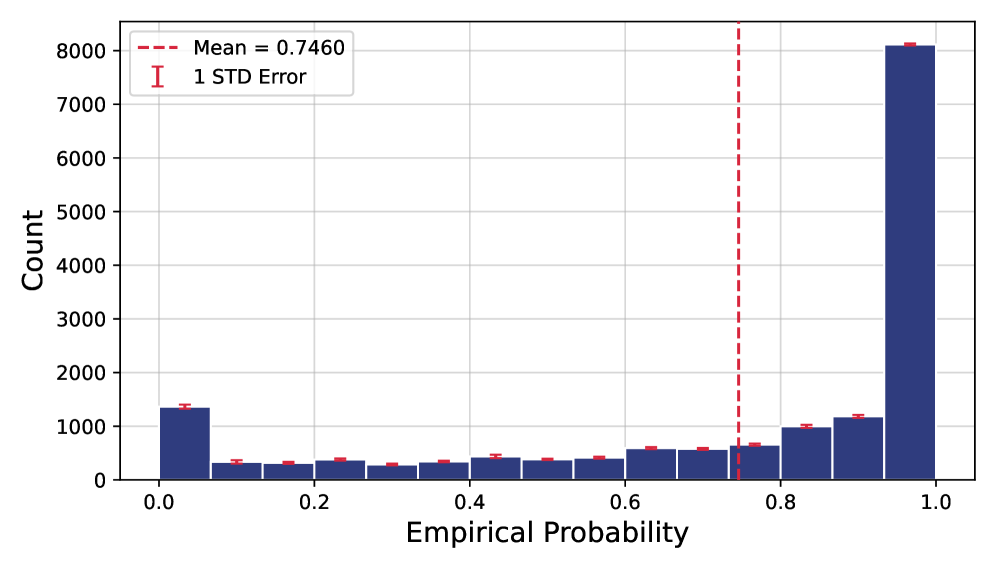
Figure 1 — Feature 재발현 확률 분포
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 feature 재발현 확률을 통해 Stable feature와 Unstable feature를 분리하고, 이들의 기능적/기하학적 차이를 분석합니다. 주요 분석 결과는 다음과 같습니다:
- Functional Asymmetry: Stable feature는 모델의 reconstruction 및 next-token loss에 결정적인 영향을 미치는 반면, Unstable feature는marginal한 영향만을 미치며 주로 표면적인(surface-form) 트리거에 집중되어 있습니다 [Figure 3].
- Subspace Reproducibility: Unstable feature는 개별적으로는 재현되지 않지만, cross-seed 간에 공유되는 재현 가능한 Lower-rank Subspaces에 집중되어 있습니다. 이는 seed 의존성이 노이즈 때문이 아니라 동일한 활성화 공간 내의 basis 모호성(basis ambiguity)에서 기인함을 시사합니다 [Figure 5].
- Feature Pooling: 고확률(high-probability) feature들을 풀링(pooling)하여 학습된 SAE는 기존의 EV(Explained Variance)를 유지하면서도 seed에 강건한(robust) 특성을 보입니다 [Figure 4].
- 합성 모델(synthetic model) 실험을 통해 full-rank feature는 개별적으로 식별 가능하지만, Low-rank feature는 특정 subspace 내에서만 재현된다는 기하학적 메커니즘을 명확히 입증했습니다 [Figure 6].
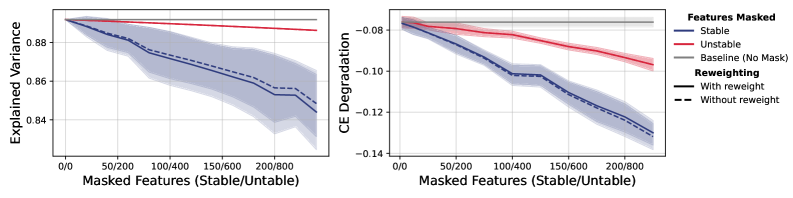
Figure 3 — Masking 결과 기능적 영향
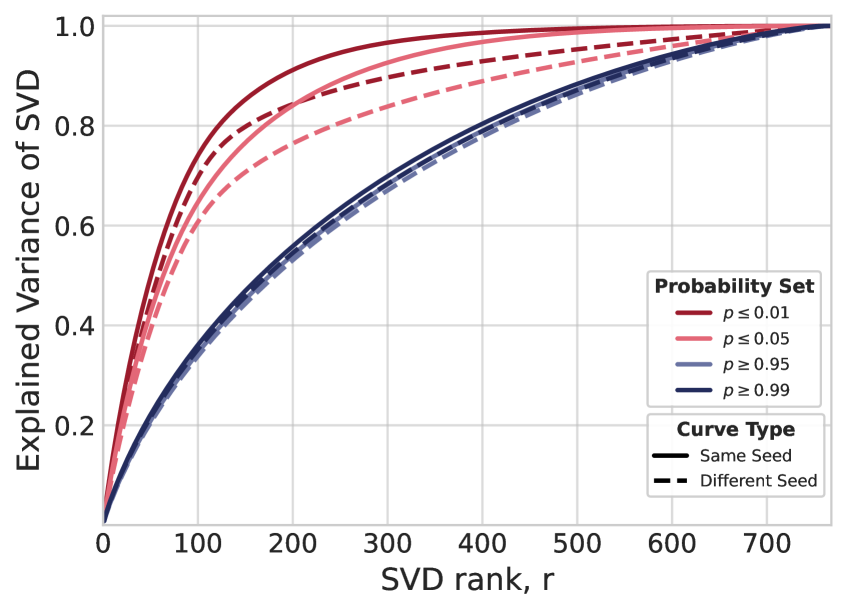
Figure 5 — Cross-seed Subspace 유사도
4. Conclusion & Impact (결론 및 시사점)
본 연구는 SAE의 seed 의존성이 임의적인 노이즈가 아니라, 재현 가능한 저차원 구조를 서로 다른 basis로 해석하는 과정에서 발생하는 체계적인 현상임을 밝혔습니다. 이 결과는 Mechanistic Interpretability 분야에서 단일 SAE 사전(dictionary)의 한계를 지적하며, 보다 견고한 feature 분석을 위해 cross-run pooling 기법을 도입할 것을 제안합니다. 향후 연구는 이러한 reproducible low-rank component를 생성하는 모델 내부의 구체적인 요인을 식별하고, 식별 가능한 individual feature를 분리해내는 방법론에 집중해야 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
- [논문리뷰] WriteSAE: Sparse Autoencoders for Recurrent State
- [논문리뷰] Sanity Checks for Sparse Autoencoders: Do SAEs Beat Random Baselines?
- [논문리뷰] OrtSAE: Orthogonal Sparse Autoencoders Uncover Atomic Features
- [논문리뷰] CorrSteer: Steering Improves Task Performance and Safety in LLMs through Correlation-based Sparse Autoencoder Feature Selection
Review 의 다른글
- 이전글 [논문리뷰] UniDDT: Unifying Multimodal Understanding and Generation with Decoupled Diffusion Transformer
- 현재글 : [논문리뷰] Unstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
- 다음글 [논문리뷰] VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
댓글