[논문리뷰] Where Did It Go Wrong? Process-Level Evaluation of Web Agents with Semantic State Tracking
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiwan Chung, JiHyuk Byun, Vibhav Vineet, Seon Joo Kim
1. Key Terms & Definitions (핵심 용어 및 정의)
- WebStep: 1,800개의 태스크 인스턴스로 구성된 웹 에이전트 평가용 벤치마크로, 자동화된 의미론적 상태 추적(Semantic State Tracking) 기능을 제공함.
- Semantic MDP Dual: 웹 에이전트가 조작하는 GUI와 병렬로 존재하는 결정론적 MDP 모델로, 에이전트의 GUI 액션을 고수준의 의미론적 상태 전이로 변환하여 기록함.
- Trajectory Bifurcation: 동일한 태스크 내에서 성공한 에이전트의 경로와 실패한 에이전트의 경로가 갈라지는 분기점으로, 실패 원인을 국소화(Localization)하는 기준점임.
- Oracle Trajectory: 태스크 완료를 위한 최단 및 최적의 경로를 의미하며, 에이전트의 성능과 스킬 사용 패턴을 비교하기 위한 참조 데이터로 활용됨.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 웹 에이전트 평가의 핵심 문제인 '최종 성공 여부(Terminal Success)에만 의존하는 방식'이 에이전트의 실패 원인을 규명하는 데 한계가 있다는 점을 지적한다. 기존의 결과 중심 평가는 긴 상호작용 과정에서 발생하는 질적으로 다른 실패 모드들을 하나로 압축하여, 구체적인 개선 방향을 제시하지 못한다 [Figure 1]. 이러한 불투명성은 에이전트의 단계별 기여도 할당(Credit Assignment)을 어렵게 만든다. 따라서 본 연구는 에이전트의 전체 상호작용 과정을 세밀하게 진단하고 학습 및 개선을 위한 actionable insight를 제공하기 위해 제안되었다.
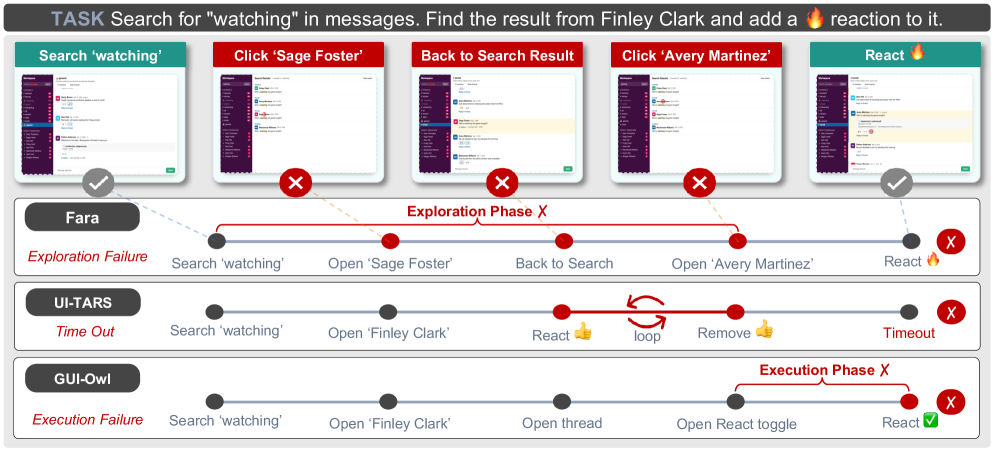
Figure 1 — 결과 중심 평가의 한계
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 각 웹사이트의 환경을 Semantic MDP Dual로 구축하여 에이전트의 GUI 액션이 어떤 고수준 상태 변화로 이어지는지를 자동으로 추적하는 WebStep 프레임워크를 제안한다 [Figure 2]. 이 프레임워크는 탐색(Exploration)과 실행(Execution) 성능을 분리하고, 스킬 단위로 에이전트의 강점과 약점을 진단할 수 있게 한다. 실험 결과, 최종 성공률이 31-33%로 유사한 소형 모델들조차도 탐색 범위와 실행 정확도 측면에서 큰 격차가 있음이 확인되었다 [Table 2]. 특히 특정 도메인(예: Housing) 내에서도 OpenAI CUA와 Qwen3.5 모델은 특정 스킬(Commit vs Filter)에서 상반된 성능을 보이는 등, 스킬 단위의 세밀한 진단이 필수적임이 증명되었다 [Figure 3]. 또한 탐색이 어려워질수록 모델 간의 성능 격차가 급격히 벌어지는 양상을 보여, 복잡도 기반의 평가 체계가 중요함을 시사한다.
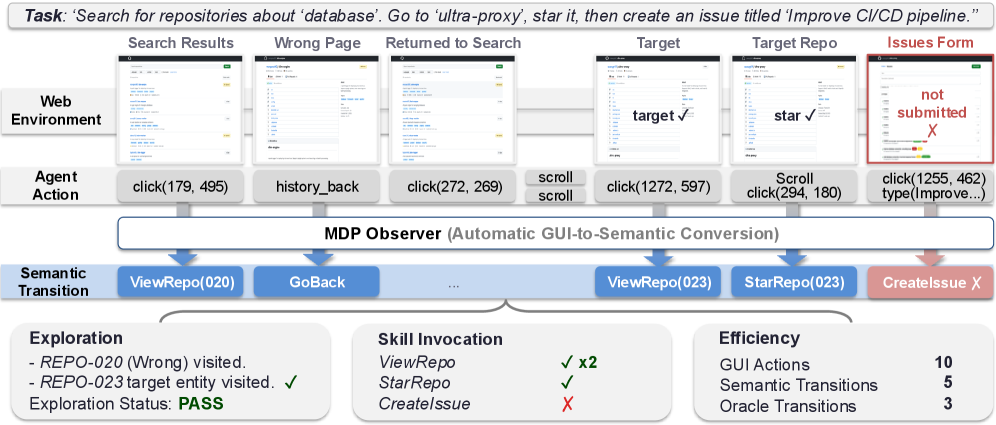
Figure 2 — WebStep 아키텍처
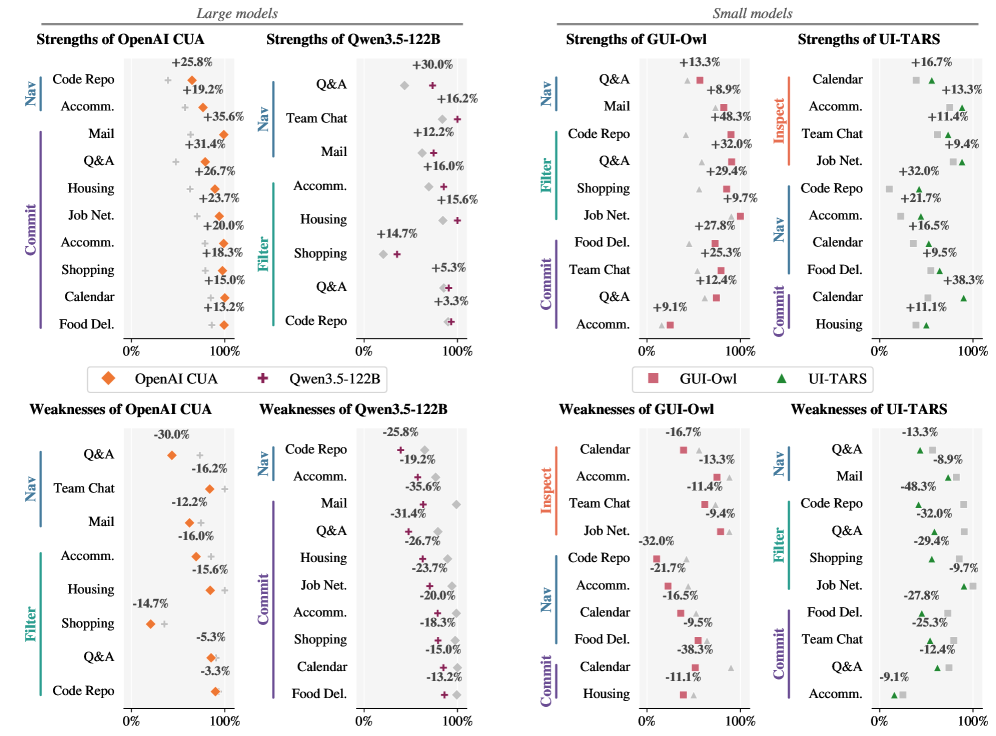
Figure 3 — 스킬별 강점 및 약점 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 웹 에이전트의 평가를 단순 순위 산정에서 구체적인 성능 진단 단계로 전환했다는 점에 의의가 있다. WebStep을 통해 제안된 프로세스 수준의 평가는 특정 도메인에서 에이전트가 왜 실패하는지, 어떤 스킬을 보강해야 하는지 등 실질적인 개선 방향을 명확히 제공한다. 이 접근 방식은 향후 웹 에이전트의 강건성을 높이고, 단순한 모델 확장을 넘어 특정 Interaction Skill을 타겟팅한 최적화 학습을 가속화할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
- [논문리뷰] DF3DV-1K: A Large-Scale Dataset and Benchmark for Distractor-Free Novel View Synthesis
- [논문리뷰] Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
- [논문리뷰] Physics-IQ Verified
Review 의 다른글
- 이전글 [논문리뷰] VisualClaw: A Real-Time, Personalized Agent for the Physical World
- 현재글 : [논문리뷰] Where Did It Go Wrong? Process-Level Evaluation of Web Agents with Semantic State Tracking
- 다음글 [논문리뷰] Who Flips? Self- and Cross-Model Counterarguments Reveal Answer Instability in LLMs
댓글