[논문리뷰] GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tongxu Luo, Rongsheng Wang, Jiaxi Bi, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Engine Grounding: 게임 생성이 가상의 코딩 환경이 아닌, 실제 Game Engine 내에서 이루어지며 해당 엔진의 네이티브 도구와 워크플로우를 활용해야 함을 의미합니다.
- Artifact Completeness: 생성된 게임이 코드 조각이 아닌, 실행 가능한(launchable) 전체 프로젝트 형태여야 하며, 이에 필요한 모든 리소스와 설정을 포함해야 한다는 조건입니다.
- Interactive Verification: 게임을 정적 코드 분석이 아닌, 실제 플레이어 입력을 시뮬레이션하고 그에 따른 반응(Action-Response Loop)을 관찰하여 성능을 평가하는 방식입니다.
- GameCraft-Bench: 저자들이 제안한 게임 생성 평가 프레임워크로, Godot 엔진을 기반으로 140개의 태스크와 15개의 게임 패밀리를 포함합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Coding Agent가 자연어 명세(Specification)를 실제 실행 가능한 게임으로 변환하는 End-to-End 생성 능력을 엄밀하게 평가하고자 합니다. 기존의 벤치마크들은 엔진 통합성, 결과물의 완전성, 혹은 상호작용 기반의 검증 중 일부만을 다루며, 실제 엔진 환경에서의 온전한 게임 구축 능력을 측정하는 데 한계가 있습니다 [Table 1]. 따라서 본 연구는 Engine Grounding, Artifact Completeness, Interactive Verification이라는 세 가지 핵심 요건을 정립하고, 이를 통합적으로 평가할 수 있는 새로운 벤치마크 환경의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 GameCraft-Bench를 구축하여 5단계 평가 파이프라인을 구현했습니다 [Figure 2, Figure 5]. 먼저 에이전트는 주어진 명세에 따라 Godot 프로젝트를 생성하며, 검증 단계에서 제출된 프로젝트의 실행 가능성(Build Gate)을 확인하고 기록된 입력 트레이스(Replay Trace)를 통해 상호작용 영상을 생성합니다. 이 과정에서 도출된 시각적 증거들은 다중 모달 판정(Multimodal Judging) 시스템을 통해 코어 메커니즘, 콘텐츠 깊이, 시각 기능성, 예술적 완성도의 4개 카테고리로 정량화됩니다. 실험 결과, 현재의 최첨단 Coding Agent 중 가장 뛰어난 Claude Code (Opus-4.7 high) 모델조차 41.46%의 평균 점수를 기록하는 데 그쳤으며, 대부분의 모델은 40% 미만의 낮은 성능을 보였습니다 [Table 4]. 특히 에이전트들은 로컬 메커니즘 구축에는 비교적 능숙하지만, 복합적인 게임 콘텐츠와 시각적 피드백을 완성도 높게 결합하는 데 구조적인 어려움을 겪는 것으로 나타났습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 AI 에이전트의 게임 생성 능력을 평가하기 위한 표준화된 프레임워크인 GameCraft-Bench를 성공적으로 제시하며, End-to-End 게임 개발이 여전히 고도의 추론과 반복적 개선을 요구하는 복잡한 과제임을 입증했습니다. 이 연구는 단순히 코드를 생성하는 수준을 넘어, 물리적인 엔진 제약 하에서 인터랙티브한 경험을 구현하는 에이전트 설계의 중요성을 강조합니다. 향후 학계 및 게임 산업 분야에서 에이전트의 개발 생산성을 높이고 복잡한 소프트웨어 아키텍처를 안정적으로 구축하도록 유도하는 핵심 척도로 활용될 것입니다.
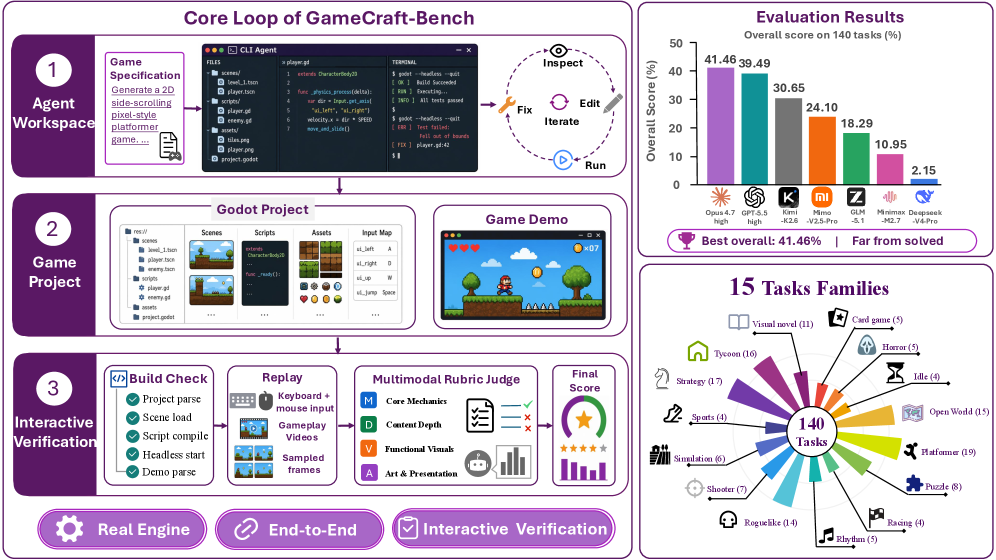
Figure 2 — 벤치마크 전체 개요
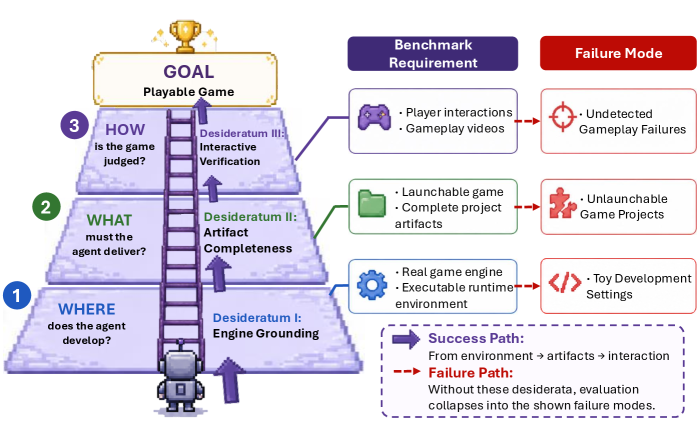
Figure 4 — 3대 핵심 평가 요건
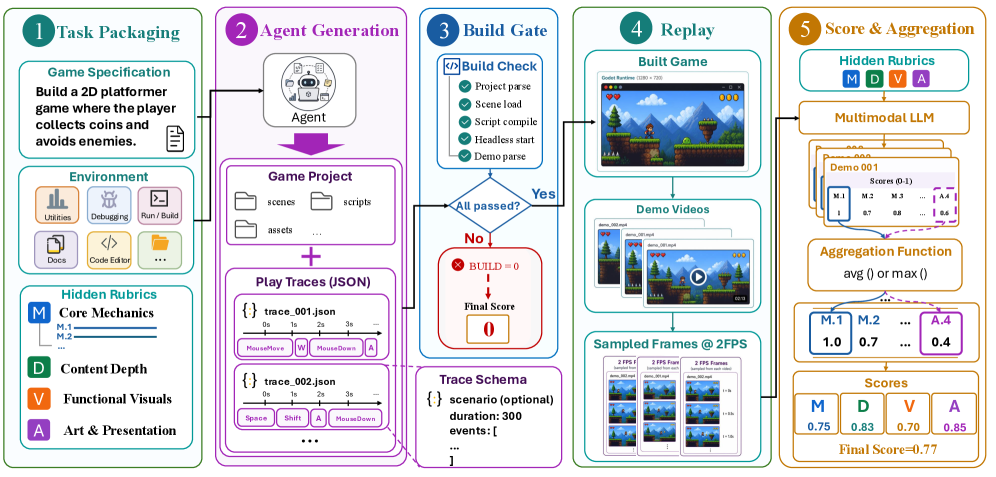
Figure 5 — 평가 파이프라인 상세
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
- [논문리뷰] NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
- [논문리뷰] CodeFuse-CR-Bench: A Comprehensiveness-aware Benchmark for End-to-End Code Review Evaluation in Python Projects
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] DF3DV-1K: A Large-Scale Dataset and Benchmark for Distractor-Free Novel View Synthesis
Review 의 다른글
- 이전글 [논문리뷰] EgoCS-400K: An Egocentric Gameplay Dataset for World Models
- 현재글 : [논문리뷰] GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?
- 다음글 [논문리뷰] Learning from the Self-future: On-policy Self-distillation for dLLMs
댓글