[논문리뷰] JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jianwen Sun, Chuanhao Li, Zizhen Li, Yukang Feng, Fanrui Zhang, Yifei Huang, Yu Dai, Kaipeng Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- JamSet & JamBench: Godot 엔진을 기반으로 구축된 최초의 프로젝트 레벨 게임 코드 프레임워크 데이터셋 및 벤치마크.
- Deterministic Verification Pipeline: 게임 프로젝트의 파일 무결성, 컴파일, 런타임 안정성 및 행동 데이터를 Headless Mode에서 100% 자동화하여 검증하는 프레임워크.
- SCS (Structural Completeness Score): 게임 프로젝트의 정적 구조(스크립트 개수, 노드 구조, 신호 사용 등)가 참조 데이터 대비 얼마나 충실하게 구현되었는지 측정하는 지표.
- BAS (Behavioral Alignment Score): 게임 실행 중 발생하는 런타임 행동(이벤트, 위치 변화 등)의 유사도를 통해 기능적 완성도를 측정하는 정량적 지표.
- Capability Cliff: 프로젝트 규모가 커짐에 따라 LLM의 성능이 급격히 저하되는 현상으로, 코드 생성 및 엔지니어링 능력의 한계를 나타냄.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 프로페셔널 게임 엔진 환경에서 프로젝트 레벨의 코드 프레임워크를 생성하고 평가하는 AI 기술의 부재를 해결하고자 한다 [Figure 1]. 기존 연구들은 주로 단일 파일 생성이나 간단한 게임 로직에 국한되어 있으며, 게임의 복잡한 런타임 행동을 정량적으로 평가할 수 있는 방법론이 부족하였다. 특히 수동 테스트는 확장성이 낮고, LLM 기반 평가는 주관성과 재현성 결여라는 한계를 지닌다. 저자들은 이러한 한계를 극복하기 위해 Godot 엔진의 텍스트 기반 포맷과 Headless Mode를 활용한 결정론적 평가 파이프라인을 제안한다 [Figure 2].
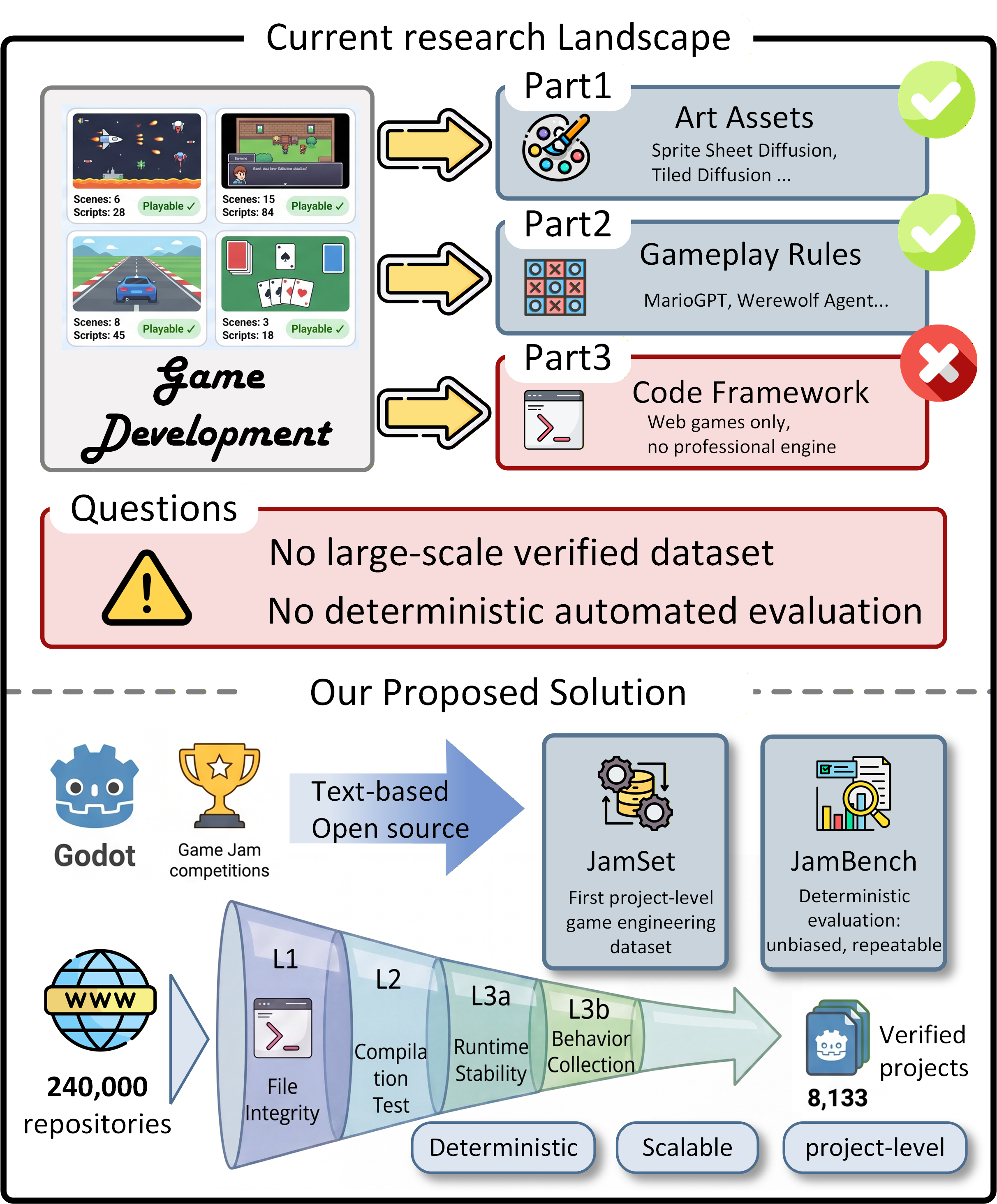
Figure 1 — 연구 배경 및 제안 해결책
Figure 2 — JamBench 파이프라인 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 전 세계 게임 잼(Game Jam) 데이터를 활용하여 240,000개 이상의 레포지토리에서 8,133개의 고품질 프로젝트를 필터링하여 JamSet을 구축하였다. 제안하는 검증 파이프라인은 L1(파일 무결성), L2(컴파일), L3a(런타임 안정성), L3b(행동 데이터 수집)의 4단계로 구성되어 모든 과정에서 LLM의 판단 없이 자동화된 수치를 산출한다 [Figure 2]. 실험 결과, 9개 최첨단 LLM 모델들은 프로젝트 규모가 커질수록 Capability Cliff를 보이며, 대규모 프로젝트에서 런타임 패스율이 5.7%까지 급감하는 현상을 확인하였다 [Table 4]. 또한, Code Agent를 도입해도 컴파일 성공률은 개선되지만 구조적 완성도(SCS)나 행동 정렬도(BAS)는 유의미한 향상이 없음을 발견하였다. 반면, JamSet을 활용한 SFT (Supervised Fine-Tuning)는 모델의 입출력 추상화 및 전역 상태 관리 등 인간의 엔지니어링 관행 습득에 효과적임을 입증하였다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 프로페셔널 게임 엔진 환경에서 프로젝트 레벨의 코드 생성을 체계적으로 평가할 수 있는 최초의 프레임워크를 제공하였다. 연구 결과는 현재 LLM들이 단순한 문법적 수정을 넘어 복잡한 게임 아키텍처를 설계하는 데 한계를 가지고 있음을 명확히 보여준다. 이 연구가 제안하는 SCS와 BAS는 게임 소프트웨어 공학 분야에서 객관적인 벤치마킹 표준으로 활용될 수 있다. 향후 본 데이터셋은 게임 엔지니어링 특화 모델의 개발과 고도화된 코드 에이전트 연구에 핵심적인 토대가 될 것으로 기대된다.
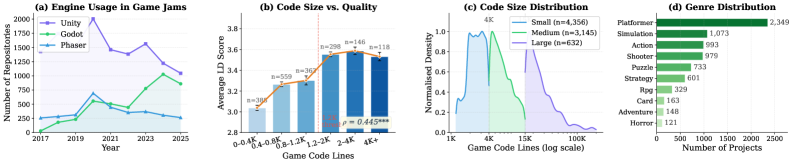
Figure 3 — 데이터셋 통계 및 품질 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?
- [논문리뷰] PaintBench: Deterministic Evaluation of Precise Visual Editing
- [논문리뷰] SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing
- [논문리뷰] Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports
- [논문리뷰] SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
Review 의 다른글
- 이전글 [논문리뷰] ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
- 현재글 : [논문리뷰] JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
- 다음글 [논문리뷰] JanusMesh: Fast and Zero-Shot 3D Visual Illusion Generation via Cross-Space Denoising
댓글