[논문리뷰] JanusMesh: Fast and Zero-Shot 3D Visual Illusion Generation via Cross-Space Denoising
링크: 논문 PDF로 바로 열기
메타데이터
저자: Siang-Ling Zhang, Huai-Hsun Cheng, Tsung-Ju Yang, Yu-Lun Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- 3D Visual Illusion: 특정 관점(viewpoint)에서 서로 다른 의미론적(semantic) 정보를 드러내도록 설계된 단일 3D mesh.
- Cross-Space Denoising: 3D latent를 반복적으로 voxel space로 디코딩하여 SDF 기반의 결합(blending)을 수행하고, 다시 인코딩하는 과정을 통해 기하학적 무결성을 보장하는 기술.
- SDF Blending: 두 객체의 Signed Distance Field(SDF)를 요소별로 평균내어 기하학적 형태를 자연스럽게 융합하는 기법.
- CLIP-guided Orientation Search: 3D 객체의 Silhouette 정렬을 최대화하기 위해 CLIP 유사도를 활용하여 최적의 상대 회전 각도를 자동으로 탐색하는 알고리즘.
- View-Conditioned Texture Synthesis: 관찰 각도에 따라 서로 다른 diffusion prior를 투영하고 집계하여, 시점별로 분리된 텍스처를 생성하는 모듈.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 텍스트 기반의 프롬프트로부터 서로 다른 시점에서 상이한 의미를 갖는 3D Visual Illusion을 효율적으로 생성하는 문제를 해결하고자 한다 [Figure 1]. 기존의 최적화 기반 방법론(Optimization-based methods)은 SDS(Score Distillation Sampling)를 사용해 수렴 속도가 매우 느리며, 색상 과포화(oversaturation) 현상이 발생하는 한계가 있다. 또한, 단순히 두 객체를 이어 붙이는 Direct Concatenation 방식은 기하학적인 이음새(seam)가 발생하고 의미론적 정보가 유출되어 환영(illusion) 효과를 저해한다 [Figure 2]. 따라서 연구자들은 트레이닝 과정 없이 3~5분 이내에 고품질의 3D 환영을 생성할 수 있는 훈련 없는(training-free) 프레임워크를 제안한다.
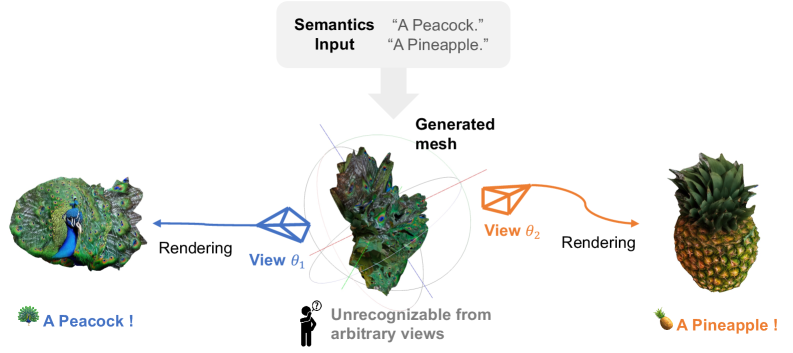
Figure 1 — 제로샷 3D 환영 생성 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 크게 Dual-Branch Geometry Generation과 View-Conditioned Texture Synthesis라는 2단계 프레임워크를 제안한다 [Figure 3]. 1단계에서는 TRELLIS 기반의 rectified flow를 활용하여 두 개의 독립적인 denoising 브랜치를 구성하고, 디코딩된 voxel 내에서 SDF Blending을 통해 이음새 없는 기하학적 결합을 수행한다 [Figure 4]. 이후, CLIP-guided Orientation Search를 통해 두 객체의 최적 회전 각도를 계산함으로써 실루엣 간의 정렬을 극대화한다 [Figure 6]. 2단계에서는 Stable Diffusion의 2D diffusion prior를 3D mesh에 투영하여 관점에 따라 최적화된 텍스처를 합성한다. 실험 결과, 본 논문의 방법론은 GPT Accuracy 84%를 기록하며 기존 방식 대비 우수한 의미 인식률을 보였으며, Impact Factor 지표에서 기하학적 연속성을 입증하였다 [Table 2]. 특히 3-5분의 빠른 생성 속도는 Shape from Semantics 대비 압도적인 효율성을 보여준다 [Figure 9, Figure 10].
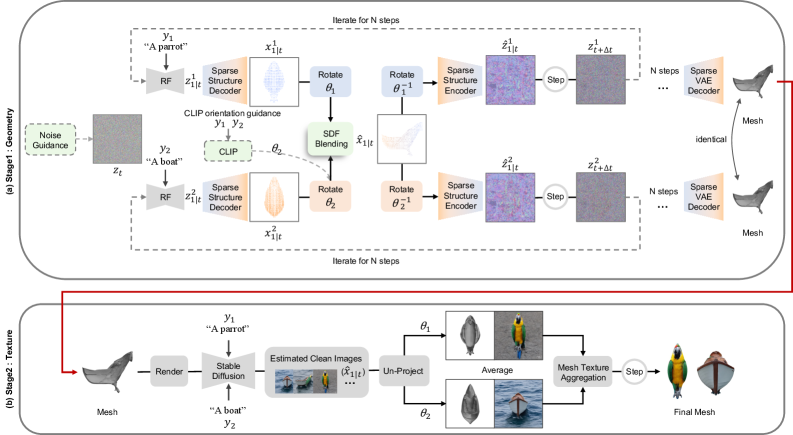
Figure 3 — 전체 파이프라인 개요
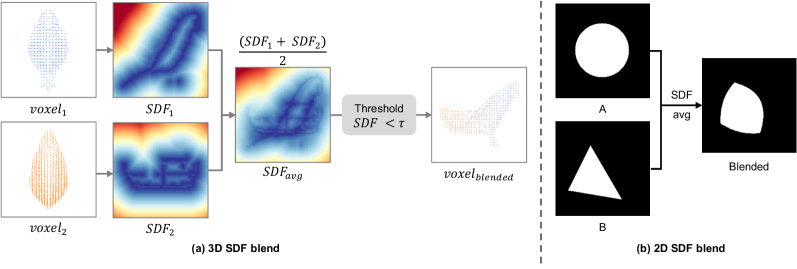
Figure 4 — SDF 기반 기하학적 결합
4. Conclusion & Impact (결론 및 시사점)
본 논문은 2D에서 정립된 Visual Illusion 생성 기술을 3D 영역으로 성공적으로 확장하며, 기하학적 무결성과 의미론적 인식을 보장하는 효율적인 제로샷 프레임워크를 정립하였다. 이 연구는 기존의 긴 최적화 시간 문제를 해결함으로써 3D 콘텐츠 생성 분야의 상업적 활용 가능성을 넓혔다. 또한, 제안된 SDF Blending과 CLIP-guided 정렬 전략은 복잡한 다중 객체 환영(3-object illusions) 생성으로의 확장이 가능함을 보여주며, 향후 다양한 3D 생성 모델에 응용될 수 있는 강력한 기법적 토대를 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ChangeFlow -- Latent Rectified Flow for Change Detection in Remote Sensing
- [논문리뷰] Map2World: Segment Map Conditioned Text to 3D World Generation
- [논문리뷰] FlowSlider: Training-Free Continuous Image Editing via Fidelity-Steering Decomposition
- [논문리뷰] FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
- [논문리뷰] TactAlign: Human-to-Robot Policy Transfer via Tactile Alignment
Review 의 다른글
- 이전글 [논문리뷰] JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
- 현재글 : [논문리뷰] JanusMesh: Fast and Zero-Shot 3D Visual Illusion Generation via Cross-Space Denoising
- 다음글 [논문리뷰] LooseControlVideo: Directorial Video Control using Spatial Blocking
댓글