[논문리뷰] Rethinking the Role of Efficient Attention in Hybrid Architectures
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziqing Qiao, Yinuo Xu, Chaojun Xiao, Zhou Su, Zihan Zhou, Yingfa Chen, Xiaoyue Xu, Xu Han, Zhiyuan Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Full Attention: 전체 문맥을 처리하는 표준 Softmax 기반의 Attention 메커니즘으로, 긴 시퀀스에서 높은 컴퓨팅 비용이 요구됩니다.
- Efficient Attention: Sliding-Window Attention (SWA)이나 Recurrent Sequence Mixers(예: Lightning Attention, Mamba-2, Gated DeltaNet)와 같이 연산 효율성을 높인 Attention 모듈을 통칭합니다.
- Hybrid Architecture: Full Attention과 Efficient Attention 레이어를 결합하여 긴 문맥 처리를 최적화한 언어 모델 구조입니다.
- Large-Window Laziness: 긴 SWA 윈도우를 사용할 경우, 모델이 국소적인 정보만으로 학습을 완료하려 하여 장거리 정보 검색(Retrieval) 능력을 학습할 동기를 잃게 되는 현상입니다.
- LongPPL: 긴 문맥에서의 성능을 지속적이고 안정적으로 측정하기 위해 사용하는 Perplexity 기반 지표입니다 [3.2].
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 하이브리드 아키텍처에서 Efficient Attention이 모델의 장거리 문맥 학습 능력에 미치는 영향을 체계적으로 규명하는 것을 목표로 합니다. 최근 언어 모델들은 계산 효율성을 위해 SWA나 Recurrent Sequence Mixers를 혼합하는 추세이나, 이러한 모듈이 실제 성능과 학습 역학에 기여하는 바에 대한 학술적 이해는 여전히 부족합니다 [1]. 기존 연구들은 최종적인 벤치마크 결과만을 제시할 뿐, 학습 과정에서의 아키텍처별 차이와 그 기제를 명확히 설명하지 못합니다. 이에 본 연구는 Scaling Law, 메커니즘 분석, 아키텍처 설계를 통해 이 격차를 해소하고자 합니다 [1].
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 다양한 Efficient Attention 설계를 적용한 하이브리드 모델들을 S1~S5 규모로 사전 학습(Pretraining)하여 Loss 및 LongPPL을 분석합니다 [4.1]. 연구 결과, Validation Loss(단기 문맥 성능)는 하이브리드 설계와 무관하게 모든 모델이 유사한 분포를 보였으나, LongPPL(장기 문맥 성능)에서는 초기 학습 단계에서 모델별로 유의미한 차이가 발생함이 밝혀졌습니다 [4.2, 4.3]. 기제 분석을 통해 장거리 검색은 주로 Full Attention 레이어에서 처리됨을 확인하였으며, Efficient Attention은 그 자체가 정보를 전달하기보다 Full Attention의 학습 경로를 조절하는 Optimization Prior로 작용한다는 결론을 내렸습니다 [5.1, 5.2]. 특히 Large-Window Laziness 현상을 통해 윈도우가 클수록 Retrieval-Head 형성이 지연됨을 증명했습니다 [Figure 5]. 이를 바탕으로 Full Attention 레이어에 NoPE(No Positional Encoding)를 적용한 결과, 단기 성능 저하 없이 장기 문맥 성능을 효과적으로 개선하였습니다 [6.3, Table 2].
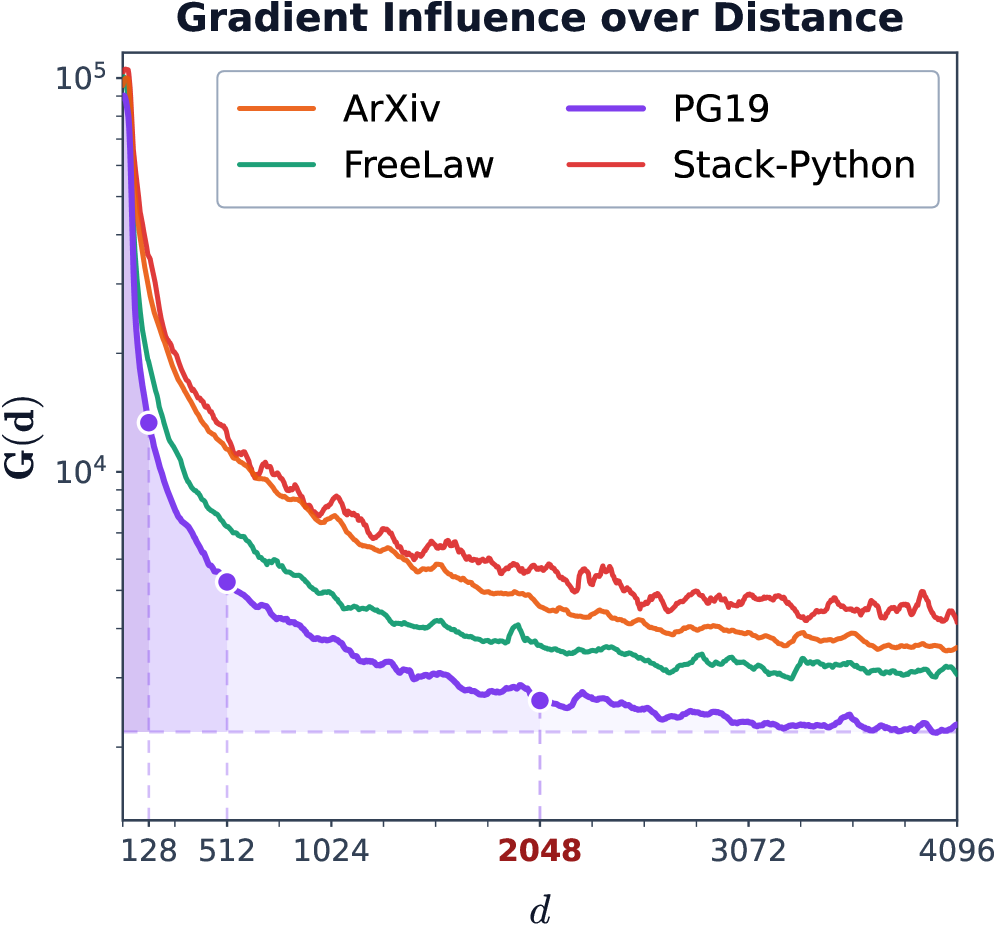
Figure 5 — Large-Window Laziness 현상 입증 데이터
4. Conclusion & Impact (결론 및 시사점)
본 논문은 하이브리드 아키텍처에서 Efficient Attention의 핵심 역할이 직접적인 정보 저장이 아닌 Full Attention의 학습 촉진에 있음을 이론적으로 정립하였습니다. 따라서 향후 하이브리드 모델 설계는 효율성 중심의 모듈 개선보다, Full Attention의 장거리 검색 능력을 극대화할 수 있는 방향으로 전환되어야 함을 시사합니다. 본 연구에서 제안한 NoPE 적용 등은 제한된 학습 예산 내에서 성능 효율성을 최적화하는 실질적인 설계 원칙을 제공합니다. 이는 산업계와 학계에서 대규모 언어 모델의 장거리 문맥 학습 전략을 수립하는 데 중요한 이정표가 될 것입니다.
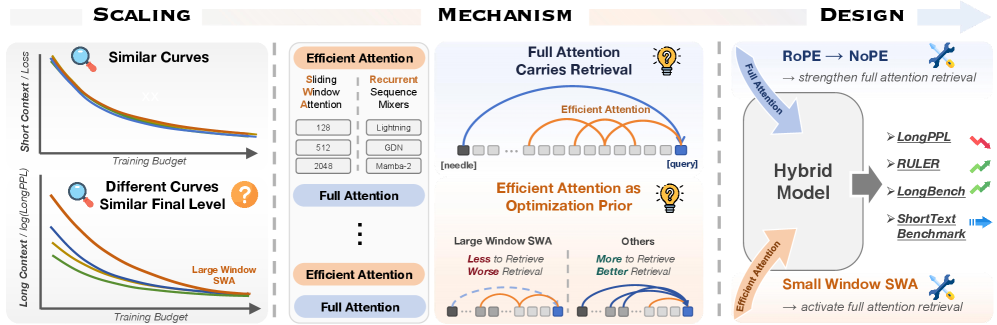
Figure 1 — 하이브리드 아키텍처 설계와 메커니즘 요약
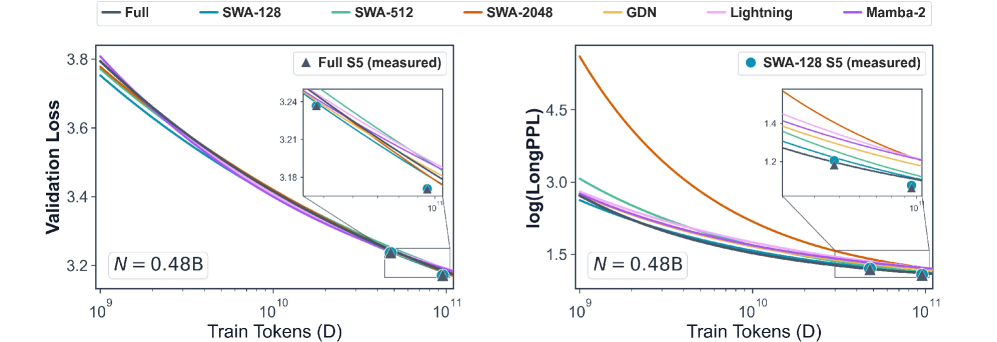
Figure 2 — 모델별 Loss 및 LongPPL 확장 법칙 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Ghosts of Polymarket: When Off-Chain Matches Meet On-Chain Reverts
- [논문리뷰] Avatar V: Scaling Video-Reference Avatar Video Generation
- [논문리뷰] SANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer
- [논문리뷰] Voxtral TTS
- [논문리뷰] DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] RepSelect: Robust LLM Unlearning via Representation Selectivity
- 현재글 : [논문리뷰] Rethinking the Role of Efficient Attention in Hybrid Architectures
- 다음글 [논문리뷰] Show the Signal, Hide the Noise: Spectral Forcing for Pixel-Space Diffusion
댓글