[논문리뷰] Show the Signal, Hide the Noise: Spectral Forcing for Pixel-Space Diffusion
링크: 논문 PDF로 바로 열기
메타데이터
저자: Weichen Fan, Haiwen Diao, Penghao Wu, Ziwei Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Spectral Forcing (SF): 픽셀 공간 확산 모델의 입력 단에 적용되는 매개변수 없는(parameter-free) 시간 조건부 2D-DCT(Discrete Cosine Transform) 저역 통과 연산자입니다.
- Rectified-flow: 본 논문에서 기반으로 하는 확산 모델 프레임워크로, 노이즈와 데이터 간을 선형적으로 보간하여 변환하는 방식을 취합니다.
- Data-to-Noise Ratio (DNR): 특정 주파수 대역에서 데이터의 신호 강도와 노이즈 분산의 비율을 나타내며, 모델이 학습해야 할 신호와 노이즈 지배 영역을 구분하는 기준이 됩니다.
- Bandwidth Front $k^*(t)$: DNR이 1이 되는 임계 주파수 대역으로, 시간에 따라 변화하며 모델이 학습해야 할 유효 신호 영역과 결정론적 베이스라인으로 수렴하는 노이즈 영역을 분리합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 픽셀 공간 확산 모델에서 모델의 컴퓨팅 자원이 비효율적으로 할당되는 문제를 해결하고자 합니다. 기존의 픽셀 기반 확산 모델은 전체 대역폭의 노이즈가 포함된 이미지를 매 타임스텝마다 처리해야 하는데, 이 과정에서 실제 데이터 분포를 학습하는 것보다 결정론적인 베이스라인으로 수렴하는 노이즈 지배 영역(noise-dominated region)에 과도한 연산 자원이 낭비되는 문제가 발생합니다 [Figure 1]. 저자들은 확산 모델의 학습이 본질적으로 'Coarse-to-fine' 구조를 띠고 있음을 규명하고, 모델이 명시적으로 주파수 경계(bandwidth boundary)를 인식하지 못해 발생하는 용량 할당 문제를 지적합니다. 이를 해결하기 위해 모델이 유효 신호 영역에 집중할 수 있도록 돕는 명시적인 사전(prior)이 필요함을 강조합니다.
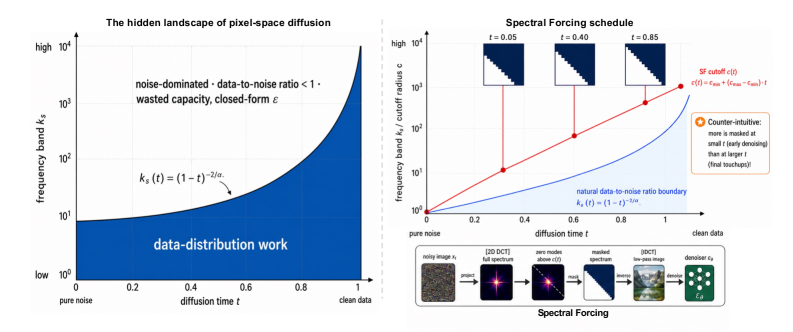
Figure 1 — Spectral Forcing 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Spectral Forcing(SF)을 제안하여, 모델이 학습 과정에서 노이즈가 지배적인 고주파수 영역을 사전에 차단함으로써 유효 신호 학습에 모델의 가용 자원을 집중시킵니다 [Figure 1]. SF는 시간 조건부 2D-DCT 마스크를 입력단에 적용하며, 확산 타임스텝 $t$에 따라 컷오프(cutoff) 주파수를 단조 증가시켜 최종 데이터 시점($t=1$)에서는 원래 이미지 대역을 완전히 복원합니다. 이는 추가적인 학습 파라미터를 요구하지 않으며, 기존의 확산 학습 프레임워크를 수정하지 않고도 즉시 통합(drop-in)이 가능하다는 장점이 있습니다. ImageNet-256 환경에서 JiT-700M/32 모델을 대상으로 실험한 결과, SF는 FID를 24.19에서 20.68로 약 14.5% 개선하였으며, Inception Score 또한 약 13% 향상시키는 성과를 거두었습니다 [Table 3]. 특히 이 기법은 토큰화가 거친(coarse tokenization) 환경에서 고주파수 영역의 노이즈를 효과적으로 제거할 때 성능 우위가 두드러졌으며, SenseNova-U1과 같은 VLM 모델에서도 GenEval 및 DPG-Bench 지표 개선을 통해 범용적인 유효성을 입증하였습니다 [Figure 5].
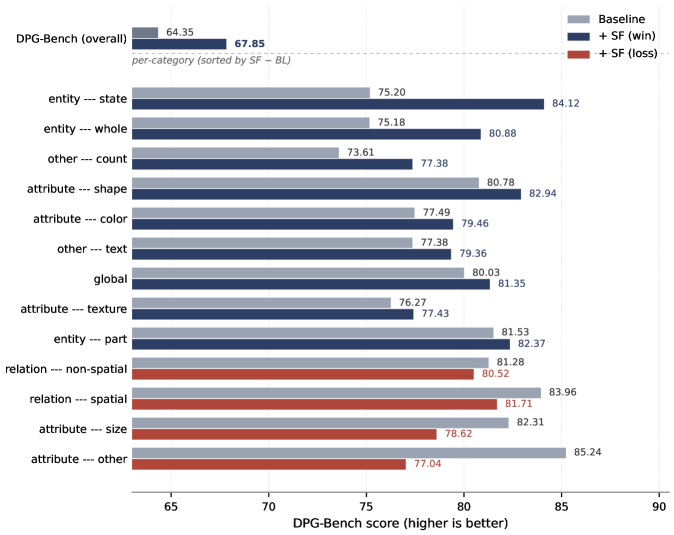
Figure 5 — VLM 모델에 적용된 SF 성능
4. Conclusion & Impact (결론 및 시사점)
본 논문은 확산 모델의 학습 효율성을 극대화하기 위해 '신호를 보여주고 노이즈를 숨기는' 명시적인 주파수 제어 기법인 Spectral Forcing을 제안하였습니다. 이 접근법은 모델이 비효율적인 연산을 수행하는 주파수-시간 영역을 능동적으로 제어함으로써 학습 속도와 성능을 동시에 최적화합니다. 이 연구는 고해상도 이미지 생성을 위한 컴퓨팅 자원 효율화 측면에서 중요한 통찰을 제공하며, 특히 비전-언어 모델(VLM)을 포함한 다양한 픽셀 기반 생성 아키텍처로의 확장 가능성을 제시했다는 점에서 학술적 및 실무적 가치가 큽니다.
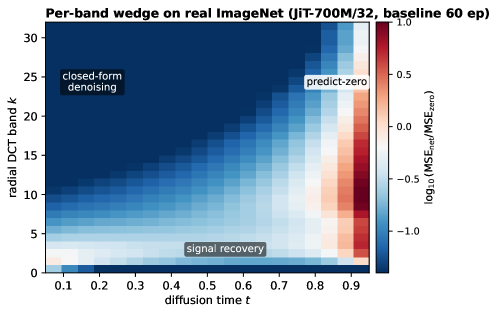
Figure 3 — ImageNet에서 확인된 wedge 구조
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Representation Forcing for Bottleneck-Free Unified Multimodal Models
- [논문리뷰] Representation Alignment for Just Image Transformers is not Easier than You Think
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
Review 의 다른글
- 이전글 [논문리뷰] Rethinking the Role of Efficient Attention in Hybrid Architectures
- 현재글 : [논문리뷰] Show the Signal, Hide the Noise: Spectral Forcing for Pixel-Space Diffusion
- 다음글 [논문리뷰] TRIAGE: Dialectical Reasoning for Explainable Risk Prediction on Irregularly Sampled Medical Time Series with LLMs
댓글