[논문리뷰] Representation Forcing for Bottleneck-Free Unified Multimodal Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuqing Wang, Zhijie Lin, Ceyuan Yang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Representation Forcing (RF): 이해(Understanding) 인코더의 visual representation을 디코더가 autoregressively 예측하도록 유도하여, pixel-space diffusion을 위한 구조적 가이드(scaffold)로 사용하는 기법.
- Unified Multimodal Models (UMMs): 인식(Perception)과 생성(Generation)을 단일 transformer backbone 내에서 통합하여 수행하는 모델.
- Mixture-of-Transformers (MoT): 모든 토큰이 동일한 self-attention 레이어를 공유하되, modality별로 feed-forward expert를 다르게 배정하는 아키텍처.
- Online Vector Quantization: 외부 pre-trained tokenizer 없이 학습 중 EMA(Exponential Moving Average) 인코더에서 추출된 특징을 사용하여 동적으로 학습되는 이산화 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 UMM이 frozen VAE에 의존하여 발생하는 structural bottleneck 문제를 해결하기 위해 Representation Forcing (RF)을 제안한다 [Figure 1]. 기존 연구는 생성 시 VAE의 latent space에 의존하므로, VAE의 압축 손실과 재구성 품질의 한계가 모델 전체의 성능을 제약하는 hard upper bound로 작용한다 [Figure 1]. Naive하게 VAE를 제거하고 직접 pixel space에서 생성하는 방식은 높은 품질의 이미지 생성에 필요한 구조적 가이드를 상실하여 성능 저하를 유발한다 [Figure 1]. 저자들은 이러한 품질 격차(quality gap)를 극복하기 위해, 모델 내부의 이해 인코더가 학습한 시각적 특징을 활용하여 디코더가 구조적 가이드를 직접 예측하도록 만드는 새로운 접근 방식을 정의하였다.
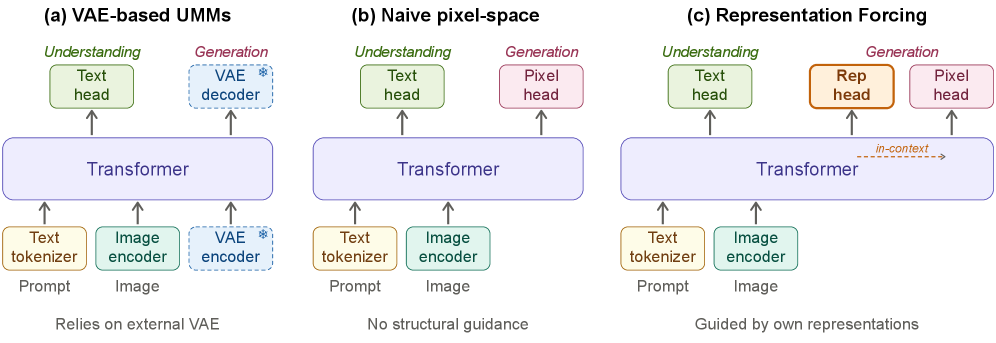
Figure 1 — 아키텍처 비교: RF 모델의 구조적 특징
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 디코더가 텍스트와 더불어 visual representation tokens를 먼저 예측하고, 이를 기반으로 pixel-space diffusion을 수행하는 Representation Forcing 프레임워크를 제안한다 [Figure 3]. 모델은 text, representation, pixel 패치를 하나의 시퀀스로 처리하며, representation tokens는 pixel 생성을 위한 강력한 in-context conditioning으로 작용한다 [Figure 3]. 실험 결과, pixel-space에서 RF를 적용한 모델은 GenEval에서 0.84, DPG-Bench에서 84.15의 점수를 기록하며 state-of-the-art VAE 기반 UMM 모델들과 대등한 성능을 보였다 [Table 1]. 또한, 이해 능력 측면에서도 8개 주요 벤치마크 중 6개에서 VAE 기반 모델을 능가하는 성과를 거두어, pixel-space generation이 UMM 환경에 더 적합함을 입증하였다 [Table 2]. 특히, pixel-space 생성 시 RF를 사용하지 않을 경우 구조적 붕괴가 관찰되지만, RF 도입 후 시각적 구조와 일관성이 비약적으로 향상되었다 [Figure 4].
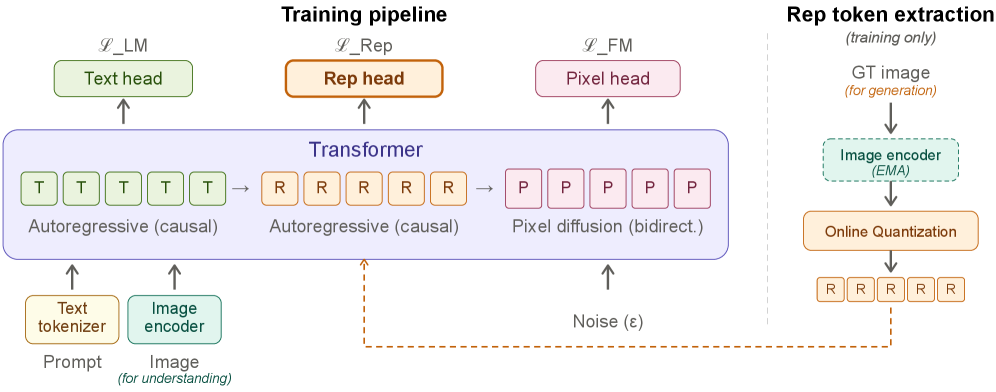
Figure 3 — RF 학습 및 추론 파이프라인

Figure 4 — RF 유무에 따른 생성 품질 정성적 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 외부 모듈 의존성 없이 단일 모델 내에서 인식과 생성을 end-to-end로 수행할 수 있는 bottleneck-free UMM의 실현 가능성을 제시한다. Representation Forcing 기법은 이해(Understanding)와 생성(Generation)을 동일한 표현 공간(representation space)으로 통합함으로써, 성능을 유지하면서도 모델의 독립성을 확보하는 효과적인 해법을 제공한다. 이 연구는 범용 멀티모달 모델(General-purpose multimodal intelligence)로 나아가는 과정에서 아키텍처의 단순화와 성능 최적화를 동시에 달성할 수 있음을 학계에 시사한다. 향후 연구를 통해 시공간 모델이나 더 복잡한 멀티모달 시나리오로의 확장이 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] See like a Robot: Robot-Centric Pointmaps for Vision-Language-Action Models
- [논문리뷰] GigaWorld-Policy-0.5: A Faster and Stronger WAM Empowered by AutoResearch
- [논문리뷰] Read It Back: Pretrained MLLMs Are Zero-Shot Reward Models for Text-to-Image Generation
- [논문리뷰] ABot-M0.5: Unified Mobility-and-Manipulation World Action Model
- [논문리뷰] GEAR: Guided End-to-End AutoRegression for Image Synthesis
Review 의 다른글
- 이전글 [논문리뷰] Recovering Policy-Induced Errors: Benchmarking and Trajectory Synthesis for Robust GUI Agents
- 현재글 : [논문리뷰] Representation Forcing for Bottleneck-Free Unified Multimodal Models
- 다음글 [논문리뷰] SAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
댓글