[논문리뷰] SAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yunbo Tang, Chengyi Yang, Shiyu Liu, Zhishang Xiang, Zerui Chen, Qinggang Zhang, Jinsong Su
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Search: LLM이 추론 과정 중에 필요에 따라 외부 도구를 사용하여 정보를 검색하고 이를 통합하는 능동적 검색 체계입니다.
- Over-Search: 모델이 내부 지식으로 충분히 답변 가능한 질문임에도 검색을 시도하거나(Unnecessary), 충분한 증거를 확보했음에도 검색을 멈추지 않는(Redundant) 비효율적인 탐색 행위입니다.
- Search Boundary: 모델의 현재 정책(policy)이 외부 정보 없이 답변할 수 있는 영역과 추가 검색이 필요한 영역을 구분하는 동적인 기준선입니다.
- Boundary-aware Reward: 모델의 현재 Search Boundary를 반영하여, 불필요하거나 중복되는 검색 행위에 대해 trajectory-level에서 패널티를 부과하는 최적화 기법입니다.
- GRPO (Group Relative Policy Optimization): 다수의 rollout을 그룹화하여 상대적인 advantage를 계산함으로써 안정적인 강화학습을 수행하는 알고리즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Agentic Search 시스템에서 발생하는 심각한 Over-search 문제를 해결하기 위해 SAAS 프레임워크를 제안합니다. 기존의 outcome-only RL 방식은 모델이 최종 정답률을 높이기 위해 무분별하게 검색을 호출하게 만들며, 이는 inference latency와 계산 비용을 불필요하게 증대시킵니다. 기존 연구들은 고정된 규칙이나 단순한 패널티를 적용하여 검색을 제어하려 하지만, 이는 모델의 능력이 학습 과정 중에 변함에 따라 Search Boundary가 달라지는 현상을 반영하지 못합니다 [Figure 1]. 결과적으로 이러한 방식은 모델이 진정한 의미의 검색 제어를 학습하지 못하게 방해하거나, 특정 검색 행동을 무조건 억제하여 오히려 성능을 저하시키는 reward hacking 문제를 유발합니다 [Figure 2].
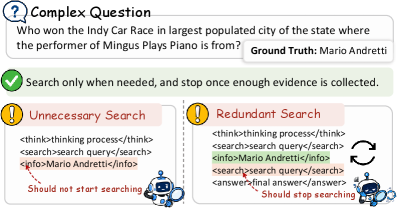
Figure 1 — Agentic Search 내 Over-search 유형
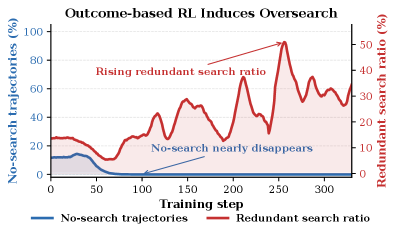
Figure 2 — 전통적 RL의 Over-search 유도 현상
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 모델의 진화하는 능력을 추적하고 이를 최적화에 반영하는 SAAS (Self-Aware Reinforcement Learning for Over-Search Mitigation) 프레임워크를 제안합니다 [Figure 4]. SAAS는 먼저 검색을 활성화한 rollout과 비활성화한 rollout을 비교하여 현재 모델의 Search Boundary를 동적으로 모델링합니다. 이어서, 이를 바탕으로 불필요한 검색을 억제하는 Boundary-aware reward를 산출하며, 학습 초기에 모델이 도구 사용 능력을 충분히 습득할 수 있도록 단계별(stage-wise) 학습 전략을 채택합니다. 실험 결과, SAAS는 Qwen2.5-3B-Instruct 모델 기준 기존 최상위 Baseline인 HiPRAG 대비 정답 정확도(ACC)를 43.6%에서 45.8%로 향상시키면서도 검색 횟수(SC)를 40.2% 감소시켰습니다 [Table 1]. 또한, Qwen2.5-7B-Instruct 환경에서도 SOR(Step-level Over-search Ratio)과 QOR(Question-level Over-search Ratio)을 대폭 낮추어 검색 효율성을 극대화함을 입증했습니다 [Table 2].
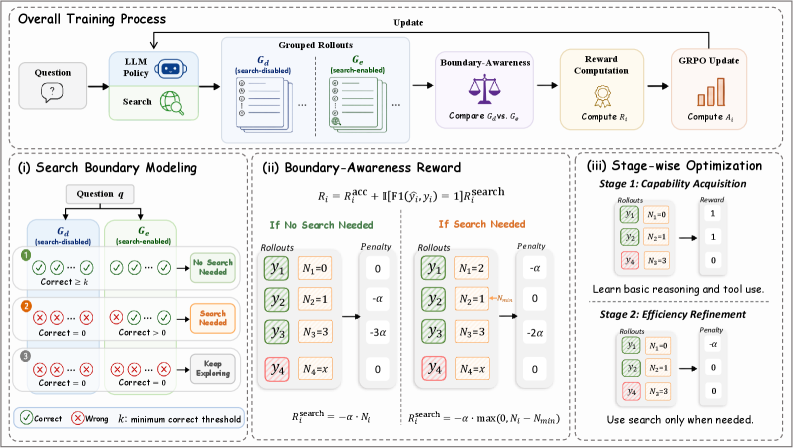
Figure 4 — SAAS 전체 파이프라인 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 모델의 동적인 Search Boundary를 학습하는 SAAS 프레임워크를 통해 Agentic Search의 Over-search 문제를 효과적으로 완화하였습니다. SAAS는 정답 정확도를 유지하면서도 불필요한 검색을 대폭 줄임으로써 실질적인 추론 효율성을 크게 개선하였습니다. 이 연구는 Agentic AI가 자신의 지식 경계를 자각하는 능력을 갖추는 것이 효율적이고 강력한 시스템 구축에 필수적임을 학계와 산업계에 시사합니다. 향후 SAAS의 원리는 텍스트 중심의 검색을 넘어 멀티모달 도구 사용 및 복합 환경 추론으로 확장될 잠재력을 가지고 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] GrepSeek: Training Search Agents for Direct Corpus Interaction
- [논문리뷰] Beyond Stochastic Exploration: What Makes Training Data Valuable for Agentic Search
- [논문리뷰] UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
- [논문리뷰] Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations
Review 의 다른글
- 이전글 [논문리뷰] Representation Forcing for Bottleneck-Free Unified Multimodal Models
- 현재글 : [논문리뷰] SAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
- 다음글 [논문리뷰] SANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer
댓글