[논문리뷰] GrepSeek: Training Search Agents for Direct Corpus Interaction
링크: 논문 PDF로 바로 열기
저자: Alireza Salemi, Chang Zeng, Atharva Nijasure, Jui-Hui Chung, Razieh Rahimi, Fernando Diaz, Hamed Zamani
1. Key Terms & Definitions (핵심 용어 및 정의)
- DCI (Direct Corpus Interaction): 고정된 인덱스나 retriever 대신, LLM이 Unix shell command를 사용하여 raw corpus를 직접 탐색하고 처리하는 검색 방식입니다.
- Cold-Start Data Generation: RL 학습 전, Tutor 모델을 활용해 답변 가능한 경로를 역방향으로 추적하고 Planner 모델을 통해 이를 정방향 trajectory로 변환하여 에이전트의 초기 탐색 능력을 확보하는 데이터 구축 과정입니다.
- GRPO (Group Relative Policy Optimization): 다수의 trajectory를 샘플링하고 보상을 그룹 내에서 정규화하여 학습하는 강화학습 알고리즘으로, 긴 호흡의 도구 사용 학습에 적합합니다.
- Semantics-Preserving Sharded-Parallel Execution: corpus를 여러 shard로 분할하여 병렬로 검색하되, 결과값의 정확성을 보장하는 최적화 엔진입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 retrieval-augmented agentic search 시스템이 pre-computed index와 retriever에 의존함으로써 발생하는 한계를 해결하고자 합니다. 기존 방식은 고정된 document chunk에 의존하여 유연한 탐색이 어렵고, 특히 복잡한 질문에 대해 추론 과정에서 중간 정보가 유실되는 경우가 많습니다. 또한, 최근 제안된 DCI 접근 방식들은 강력한 상용 모델의 inference-time prompting에만 의존하여 연산 비용이 매우 높고 실시간성 확보가 어렵다는 문제가 있습니다 [Figure 1]. 따라서 본 연구는 소형 에이전트 모델이 효율적으로 직접 corpus를 탐색하는 법을 학습하여 실용성을 확보하는 것을 목표로 합니다.
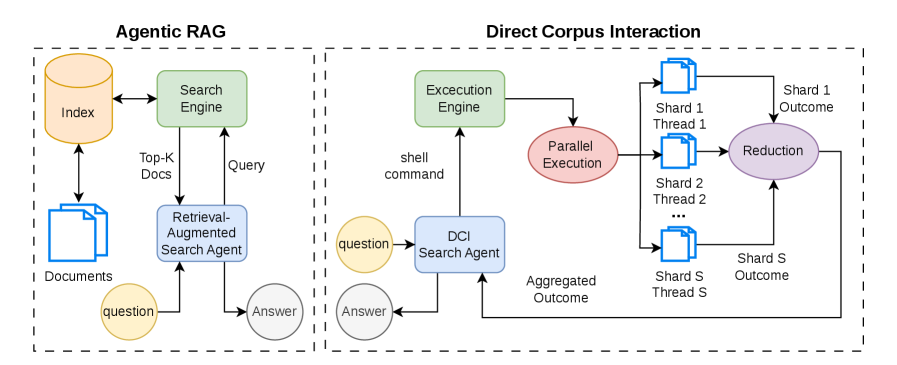
Figure 1 — RAG vs DCI 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 GrepSeek이라 명명된 최적화된 DCI 에이전트를 제안하며, 2단계 학습 파이프라인을 도입합니다. 먼저, Cold-Start Data Generation을 통해 answer-aware Tutor가 역방향으로 evidence chain을 구축하고, 이를 forward trajectory로 변환하여 모델을 초기화합니다. 이후 GRPO를 활용한 강화학습을 통해 에이전트의 검색 및 추론 능력을 고도화합니다 [Figure 2]. 또한, Semantics-Preserving Sharded-Parallel Execution 엔진을 통해 검색 지연 시간을 표준 순차 실행 대비 최대 7.6x 가속화하였습니다. 7개의 open-domain QA 벤치마크 실험 결과, GrepSeek은 기존 index-based RAG 시스템과 검색 에이전트 대비 가장 우수한 token-level F1 성능을 기록했습니다 [Table 1]. 특히, 복잡한 multi-hop reasoning 데이터셋에서 기존 시스템들이 겪는 entity ambiguity를 극복하며 통계적으로 유의미한 성능 향상을 달성하였습니다.
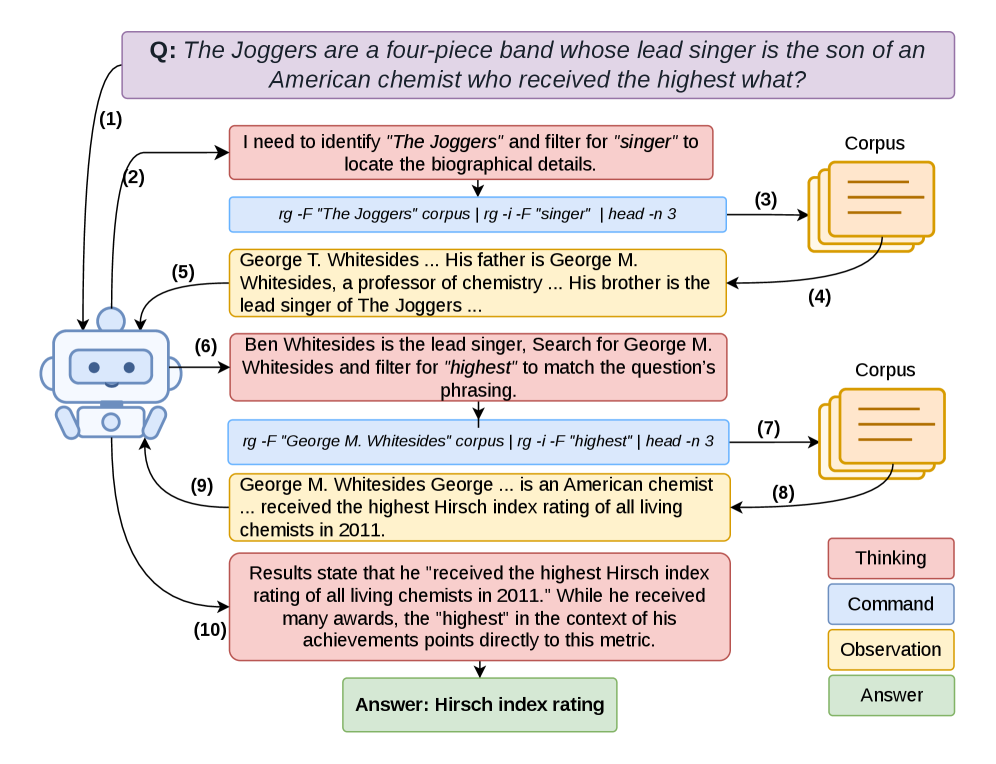
Figure 2 — GrepSeek의 검색 워크플로우
4. Conclusion & Impact (결론 및 시사점)
본 논문은 DCI가 단순한 prompting 전략을 넘어, 학습 가능한 검색 에이전트의 실용적이고 강력한 대안이 될 수 있음을 입증했습니다. GrepSeek은 인덱스 기반 시스템의 비용 부담을 제거하고 정밀한 어휘 수준 검색을 가능하게 하여, 특히 compositional reasoning이 필요한 영역에서 탁월한 성능을 보입니다. 본 연구의 결과는 향후 정보 검색 및 에이전트 시스템 설계에 있어 index-based retrieval과 direct corpus interaction을 결합하는 하이브리드 아키텍처 발전에 큰 시사점을 줍니다.
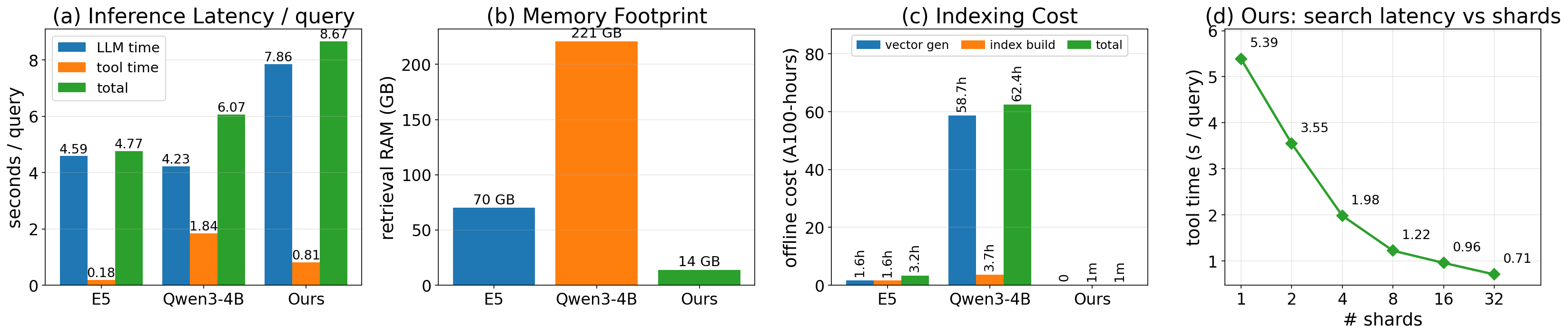
Figure 3 — 효율성 및 비용 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Towards Retrieving Interaction Spaces for Agentic Search
- [논문리뷰] SmartSearch: Process Reward-Guided Query Refinement for Search Agents
- [논문리뷰] Dr-DCI: Scaling Direct Corpus Interaction via Dynamic Workspace Expansion
- [논문리뷰] FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
- [논문리뷰] SAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
Review 의 다른글
- 이전글 [논문리뷰] GGT-100K: Generative Ground Truth for Generalizable Real-World Image Restoration
- 현재글 : [논문리뷰] GrepSeek: Training Search Agents for Direct Corpus Interaction
- 다음글 [논문리뷰] Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
댓글