[논문리뷰] Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
링크: 논문 PDF로 바로 열기
저자: Seongheon Park, Wendi Li, Changdae Oh, Samuel Yeh, Zsolt Kira, Michael Hagenow, Sharon Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) models: 시각적 관찰과 자연어 지시를 입력받아 로봇의 제어 동작을 생성하는 다중 모달 정책 모델입니다.
- Coarsely Supervised Learning: 정밀한 단계별(step-level) 주석 없이, 에피소드 전체에 대한 성공/실패 여부(trajectory-level)만을 활용하여 세밀한 신호를 학습하는 패러다임입니다.
- Conformal Prediction (CP): 통계적 보장(statistical guarantees)을 제공하며 실행 시간(runtime) 동안 동적인 임계값을 결정하여 실패를 알람으로 변환하는 프레임워크입니다.
- Inter-trajectory Contrastive Loss: 실패 궤적과 성공 궤적 간의 가장 두드러진 실패 신호를 대조하여 모델이 실패 징후를 변별하도록 학습시키는 손실 함수입니다.
- Intra-trajectory Contrastive Loss: 궤적 내에서 실패 전(pre-onset)과 후(post-onset)의 점수 차이를 극대화하여 실패 시점을 시간적으로 구조화하는 손실 함수입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 범용 VLA 모델이 실환경 배포 시 겪는 실행 실패 문제를 실시간으로 감지하기 위한 효율적인 방법을 모색합니다. 기존의 방법론들은 고가의 단계별 실패 주석이 필요하거나, 액션 재샘플링 및 외부 VLM 모델 사용에 따른 높은 계산 오버헤드로 인해 실시간 배포가 어렵다는 한계가 있습니다. 또한, 단순히 궤적 수준의 실패 라벨을 모든 타임스텝에 균일하게 할당하는 방식은 정상 동작까지 실패로 간주하는 라벨 노이즈를 발생시켜 감지 성능을 저해합니다 [Figure 1]. 따라서 본 연구는 이러한 주석 비용과 계산 효율성, 그리고 정확도 문제들을 해결하기 위해 coarse supervision만으로 시간적 구조를 가진 실패 신호를 발견하는 새로운 접근 방식을 제안합니다.
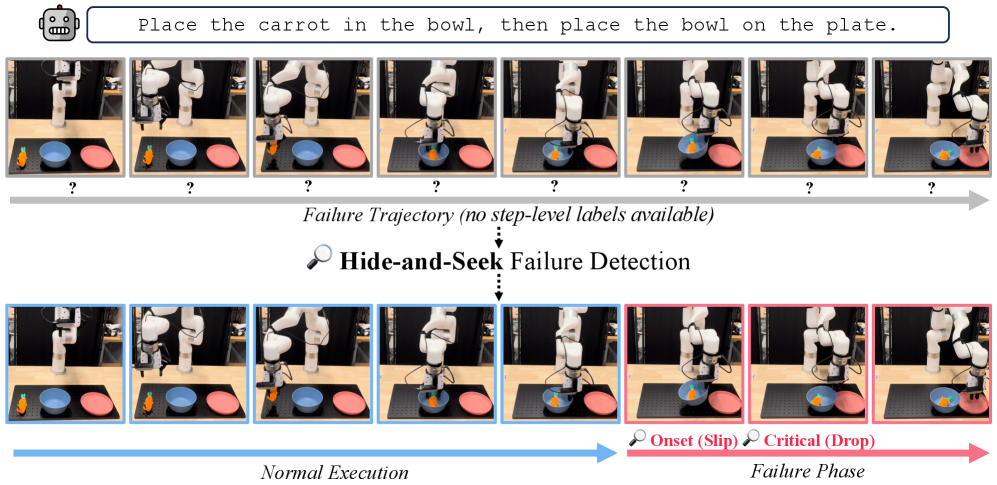
Figure 1 — Hide-and-Seek 실패 감지 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 실패 감지를 coarsely supervised learning 문제로 재정의하고, Hide-and-Seek라는 프레임워크를 제안합니다 [Figure 2]. 이 방법론은 학습 시 Inter-trajectory contrastive loss를 통해 서로 다른 궤적 간의 실패 신호를 대조하고, Intra-trajectory contrastive loss를 통해 궤적 내부에서 실패 시작점을 기준으로 시간적 점수 차이를 형성함으로써 주석 없이도 실패 징후를 국소화합니다. 런타임 모니터링을 위해서는 Functional Conformal Prediction을 채택하여 성공 궤적의 통계적 분포를 바탕으로 동적인 임계값을 설정합니다. 실험 결과, Hide-and-Seek는 LIBERO와 VLABench, 그리고 실세계 로봇 플랫폼에서 기존 최신 방법론(Classifier-based) 대비 bACC 기준 최대 11.7% 이상의 향상을 보였습니다. 특히, VLM 기반의 모니터링 방식과 비교했을 때 정확도는 13.1% 높으면서도 추론 속도는 2,000배 이상 빨라 실시간성에 탁월한 이점을 증명했습니다 [Table 1, Table 2, Table 3].
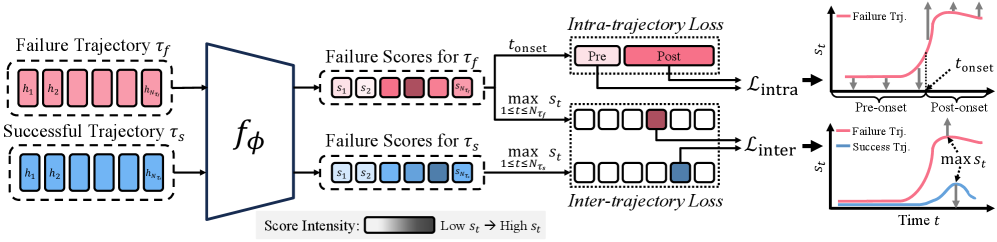
Figure 2 — 제안 모델 전체 프레임워크
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고비용의 단계별 주석 없이도 Trajectory-level의 Coarse supervision만 활용하여 VLA의 실패 신호를 효과적으로 감지하는 Hide-and-Seek 프레임워크를 성공적으로 구축하였습니다. 이 연구는 embodied agent의 안전한 배포를 위한 가볍고 정확한 실시간 감지 메커니즘을 제공함으로써 학계 및 산업계의 로봇 신뢰성 향상에 크게 기여합니다. 향후 본 기술은 실패 감지뿐만 아니라 로봇의 자체 수정(corrective intervention) 및 회복(recovery) 전략과 결합하여, 보다 강건한 자가 치유(self-correcting) VLA 시스템 구현을 위한 핵심 요소 기술로 활용될 것으로 기대됩니다.
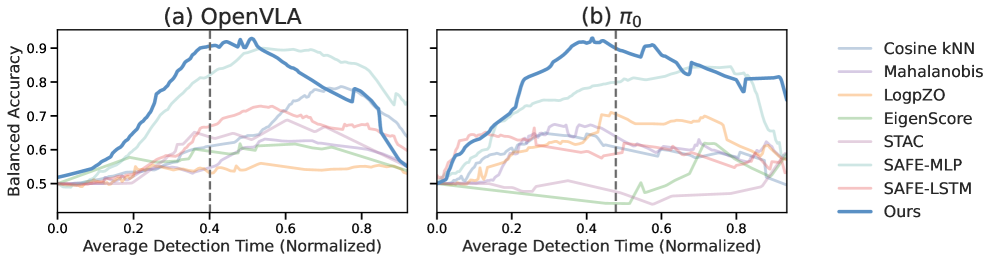
Figure 3 — 정확도-신속성 트레이드오프 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
- [논문리뷰] π-StepNFT: Wider Space Needs Finer Steps in Online RL for Flow-based VLAs
- [논문리뷰] ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
- [논문리뷰] BagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
- [논문리뷰] TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
Review 의 다른글
- 이전글 [논문리뷰] GrepSeek: Training Search Agents for Direct Corpus Interaction
- 현재글 : [논문리뷰] Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
- 다음글 [논문리뷰] How can embedding models bind concepts?
댓글