[논문리뷰] How can embedding models bind concepts?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Arnas Uselis, Darina Koishigarina, Seong Joon Oh
1. Key Terms & Definitions (핵심 용어 및 정의)
- Concept Binding: 다중 객체 장면에서 특정 속성(색상 등)이 어떤 객체에 속하는지 식별하고, 이들을 조합하여 객체 전체를 인지하는 능력입니다.
- Scene Embedding: 이미지나 텍스트와 같은 입력 데이터를 모델이 인코딩하여 출력한 벡터로, 장면 내에 존재하는 객체와 개념 정보를 포함합니다.
- Binding Function: 개념(Concepts)을 장면 임베딩으로 매핑하는 함수로, 이 함수의 복잡도가 모델의 일반화 성능을 결정합니다.
- Uni-modal Binding: 단일 모달리티 내에서 선형 탐침(Linear Probe)을 통해 객체 정보를 회복할 수 있는 현상을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Vision-Language Embedding Models인 CLIP이 개념을 개별적으로는 잘 인지하면서도, 이들을 올바르게 조합하여 객체를 구성하는 Concept Binding에는 실패하는 문제에 주목합니다. 저자들은 객체 정보가 임베딩 내부에 존재함에도 불구하고 왜 이러한 cross-modal 바인딩 실패가 발생하는지, 그리고 이 한계가 근본적인 것인지 규명하고자 합니다. 기존 연구들은 이러한 문제를 인코딩 부족이나 데이터 분포의 문제로 해석했으나, 본 연구는 Binding Function의 기하학적 복잡도 관점에서 이 문제를 새롭게 접근합니다[2].
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 장면 임베딩이 객체별로 가산적으로 분해(Additive Decomposition)되는 구조임을 밝혀내었으며, 이를 통해 Uni-modal Binding이 성공하는 이유를 설명합니다 [4.1, 4.2]. 그러나 CLIP의 Binding Function은 지나치게 높은 복잡도를 가지고 있어, 간단한 MLP로는 학습 및 일반화가 불가능하며 이는 결과적으로 조합적 일반화를 저해하는 요인이 됩니다 [4.1, 5.1]. 이에 반해, 제안하는 통제된 Transformer 모델을 사용하여 충분한 데이터로 학습한 결과, 개념 간의 Multiplicative Interaction을 활용하는 낮은 복잡도의 Binding Function이 형성되어 보지 못한 개념 조합에 대해서도 일반화가 가능함을 입증했습니다 [5.2, 5.3, 5.4]. 핵심 실험 결과로, 제안 모델은 객체 공간의 커버리지가 높아질수록 바인딩 정확도가 급격히 향상되며, Global Product 형태의 곱셈적 구조가 바인딩 성능과 가장 높은 상관관계를 보였습니다 [5.2, 5.4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Embedding Models의 바인딩 실패가 객체 구조의 부재가 아닌, 학습된 Binding Function의 과도한 복잡성에서 기인한다는 점을 증명하였습니다. 일반화 가능한 바인딩을 위해서는 모델이 개념 간의 곱셈적 상호작용을 통한 체계적이고 낮은 복잡도의 매핑을 학습해야 함을 시사합니다 [5.4, 6]. 본 결과는 더 견고하고 조합적인 능력을 갖춘 다중 모달 모델 설계를 위한 기하학적 토대를 제공합니다 [6].
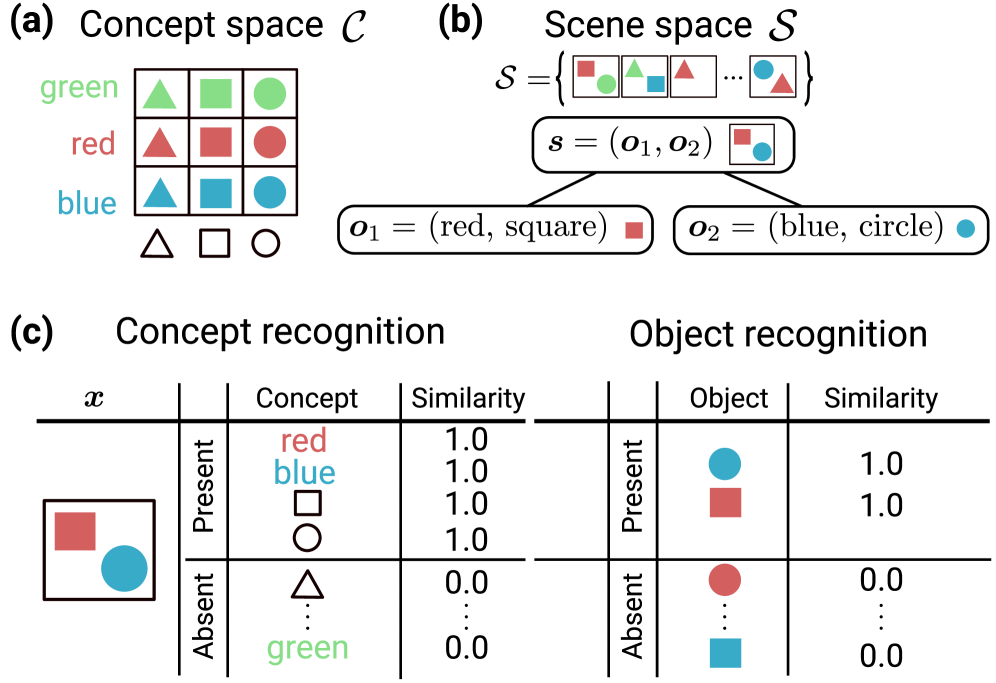
Figure 1 — 개념 바인딩 설정 개념도
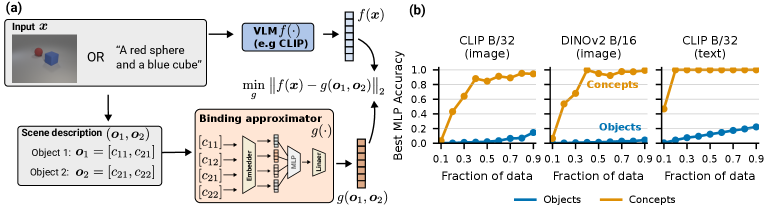
Figure 4 — CLIP 바인딩 함수의 복잡도 분석
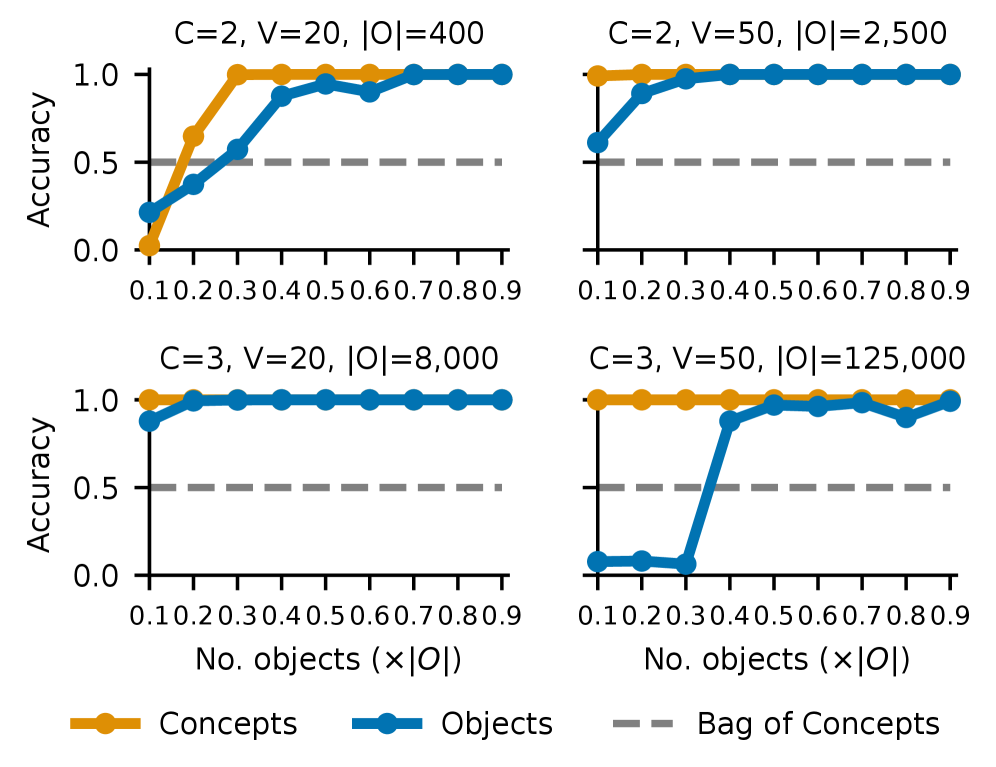
Figure 6 — 데이터 스케일에 따른 바인딩 일반화
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HDINO: A Concise and Efficient Open-Vocabulary Detector
- [논문리뷰] Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] MuScriptor: An Open Model for Multi-Instrument Music Transcription
- [논문리뷰] Why Can't I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition
Review 의 다른글
- 이전글 [논문리뷰] Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
- 현재글 : [논문리뷰] How can embedding models bind concepts?
- 다음글 [논문리뷰] Light Interaction: Training-Free Inference Acceleration for Interactive Video World Models
댓글