[논문리뷰] Light Interaction: Training-Free Inference Acceleration for Interactive Video World Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiacheng Lu, Haoyi Zhu, Sipei Yi, Enze Xie, Yu Li, Cheng Zhuo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Interactive Video World Models: 사용자의 카메라 움직임 제어에 따라 연속적인 비디오 청크를 생성하여 게임 시뮬레이션 및 가상 환경 탐색을 가능하게 하는 시스템.
- Adaptive Context Management: 카메라 포즈 기반의 유사도를 활용하여 불필요한 과거 Spatial Memory를 제거하고, 로컬 latent dynamics에 따라 Temporal Context Window를 동적으로 조절하는 기법.
- Denoising Cache Acceleration: 특정 조건(revisiting 시)에서 초기 denoising step의 출력을 후속 중간 단계에 재사용하여 연산량을 줄이는 기법.
- Hardware-Software Co-designed 3D Sparse Attention: 3D 블록 단위의 스파스 연산을 적용하고, Triton 커널 융합을 통해 메모리 접근 및 레이아웃 변환 오버헤드를 최소화하는 가속 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 interactive video world model의 장기 생성 시 발생하는 과도한 연산 비용과 추론 지연 문제를 해결하기 위해 Light Interaction을 제안한다. 기존 모델들은 긴 인터랙티브 경로를 생성할 때 context memory의 증가, quadratic한 attention 복잡도, 반복적인 denoising 단계로 인해 A100 GPU 기준 10초 분량 영상 생성에 200초 이상의 시간이 소요된다. 기존의 KV cache 압축이나 sparse attention 방식은 Autoregressive(AR) 환경에서의 인과적 제약과 불균일한 Q/K 길이 문제로 인해 실제 가속 효과가 미미하다는 한계가 있다 [Figure 1].
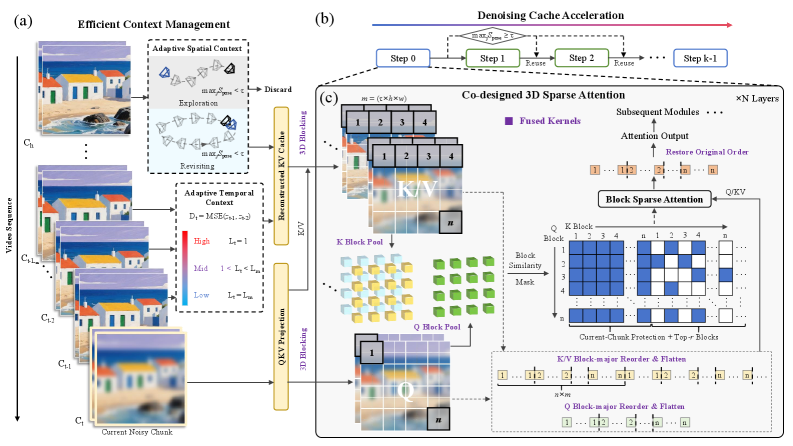
Figure 1 — Light Interaction 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 trajectory에 의존적인 adaptive computing을 핵심으로 하는 Light Interaction 프레임워크를 도입한다. 저자들은 세 가지 주요 기법을 통합하였는데, 첫째는 카메라 포즈 유사도와 로컬 latent dynamics를 활용한 Adaptive Context Management이고, 둘째는 revisiting 시 발생하는 denoising 과정의 중복성을 제거하는 Denoising Cache Acceleration이다 [Figure 2]. 마지막으로, historical visual KV cache에만 스파스 연산을 적용하고, Triton fused kernels를 사용하여 레이아웃 변환 오버헤드를 제거한 Hardware-Software Co-designed 3D Sparse Attention을 구현하였다 [Figure 3].
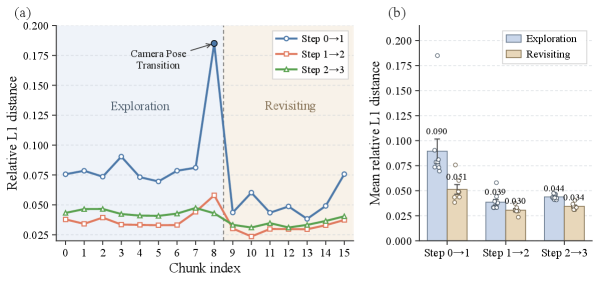
Figure 2 — Denoising 과정의 상대적 L1 거리 비교
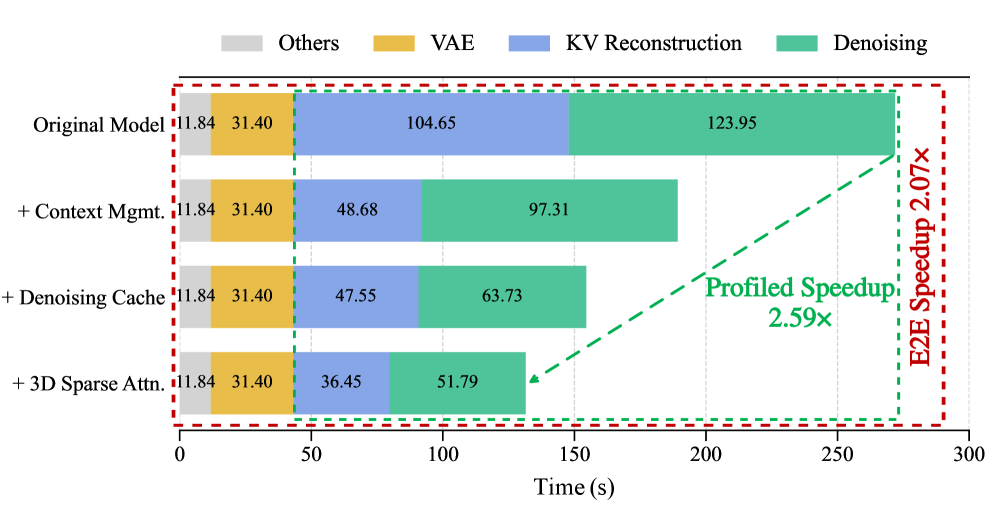
Figure 3 — 모듈별 단계적 지연 시간 감소 효과
실험 결과, 제안 모델은 HY-WorldPlay 데이터셋에서 원본 대비 **2.59×**의 속도 향상을 달성하며, 24.81 PSNR을 기록하여 기존 모델과 경쟁력 있는 품질을 유지하였다. 또한, Matrix-Game-3.0 데이터셋에서도 **1.61×**의 속도 향상을 입증하였다 [Table 1]. 개별 컴포넌트 분석 결과, Adaptive Context Management는 메모리 효율을, 3D Sparse Attention은 연산 속도 개선에 기여하며 상호 보완적으로 작동함을 확인하였다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 교육 및 연구 환경에서 interactive video world model의 접근성을 높이는 훈련 불필요(Training-Free) 추론 가속 프레임워크인 Light Interaction을 제시하였다. 제안된 방식은 가상 장면 탐색, embodied AI 학습 및 게임 시뮬레이션 분야에서 더 높은 반응성을 가진 모델 구현을 가능하게 한다. 추후 연구는 더 복잡한 환경에서의 카메라 포즈 유사도 측정 정밀도를 높이고, 다양한 denoising solver 환경으로 확장하는 방향으로 전개될 것으로 보인다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Vidu S1: A Real-Time Interactive Video Generation Model
- [논문리뷰] HunyuanOCR-1.5: Making Lightweight OCR VLMs Faster and Better
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- [논문리뷰] Parallel Rollout Approximation for Pixel-Space Autoregressive Image Generation
Review 의 다른글
- 이전글 [논문리뷰] How can embedding models bind concepts?
- 현재글 : [논문리뷰] Light Interaction: Training-Free Inference Acceleration for Interactive Video World Models
- 다음글 [논문리뷰] Linear Scaling Video VLMs for Long Video Understanding
댓글