[논문리뷰] ABot-M0.5: Unified Mobility-and-Manipulation World Action Model
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ronghan Chen, Yandan Yang, Zuojin Tang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- World Action Model (WAM): 미래의 시각적 환경 변화(video latents)와 로봇의 동작(actions)을 통합적으로 생성하여 장기적인 작업 계획과 제어를 수행하는 모델 프레임워크입니다.
- Intermediate Latent Action: 거친 시각적 변화와 정밀한 제어 동작 사이의 간극을 메우기 위해 도입된 중간 표현(bridging representation)으로, 시각적 상태 전이를 바탕으로 하드웨어 독립적인 동작 의도를 포착합니다.
- Dual-Level Mixture-of-Transformers (D-MoT): 이동성(mobility)과 조작(manipulation)이라는 이질적인 동작 공간을 구조적으로 분리하여 최적화하고, 동시에 다중 모달 표현을 효과적으로 처리하기 위한 이중 계층 구조의 모델 아키텍처입니다.
- Dream Forcing: 훈련 시 ground-truth 미래 정보에 의존하던 관행에서 벗어나, 모델이 스스로 생성한(dreamed) 미래 시각 정보를 바탕으로 역동역학(inverse dynamics)을 학습하게 함으로써 추론 시의 강건성을 높이는 훈련 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 모바일 매니퓰레이션(mobile manipulation) 환경에서 기존의 Embodied Learning 방식들이 겪는 구조적 한계를 해결하고자 합니다. 기존의 VLA(Vision-Language-Action) 정책은 명시적인 세계 모델(world model)이 없어 장기 기억력이 부족하며, 최근의 WAM 연구들조차 모바일 매니퓰레이션에 필수적인 세 가지 정렬(alignment) 문제를 해결하지 못하고 있습니다 [Figure 1]. 저자들은 거친 시각적 예측과 정밀한 제어 사이의 '시간적 세분성 불일치(temporal granularity mismatch)', 이동과 조작의 이질적 동작을 단일 공간에 통합할 때 발생하는 '동작 구조 불일치(action structure mismatch)', 그리고 훈련과 추론 시의 환경 정보 차이로 인한 '추론 조건 불일치(rollout condition mismatch)'를 핵심 문제로 정의합니다 [Figure 1]. 이러한 불일치들은 장기적인 작업 수행 시 오차 누적과 성능 저하를 초래하므로, 이를 체계적으로 해결할 수 있는 통합 프레임워크가 요구됩니다.
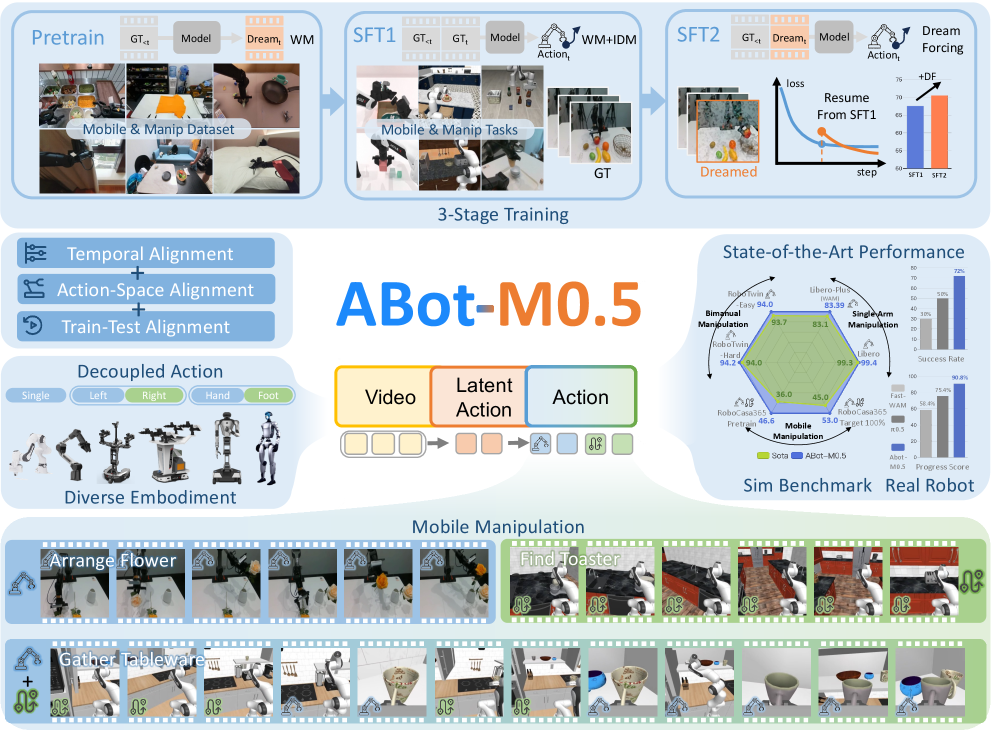
Figure 1 — ABot-M0.5의 전체 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 모바일 매니퓰레이션을 위한 ABot-M0.5를 제안하며, 이는 시각적 예측(Video Latent), 동작 의도(Latent Action), 제어(Executable Action)로 이어지는 계층적 캐스케이드 구조를 가집니다 [Figure 2]. 첫째, Intermediate Latent Action을 통해 비디오와 제어 사이의 다리 역할을 하는 중간 동작 공간을 생성하여 시간적 세분성을 맞춥니다. 둘째, D-MoT(Dual-Level Mixture-of-Transformers)를 도입하여 이질적인 이동과 조작 동작을 분리 학습함으로써 최적화의 효율성을 높입니다 [Figure 2]. 셋째, Dream Forcing 훈련 전략을 통해 모델이 자체 생성한 미래 시각 정보를 기반으로 역동역학을 학습하도록 유도하여 추론 시의 환경 변화에 강건하게 대응합니다 [Figure 1]. 실험 결과, ABot-M0.5는 다양한 모바일 매니퓰레이션 벤치마크에서 장기 작업 성공률과 정밀한 조작 정확도 측면에서 State-of-the-art(SOTA) 성능을 달성하였습니다. 특히, 제안된 3단계 훈련 파이프라인(Pretraining, SFT1, SFT2)을 통해 모델의 로버스트함이 점진적으로 향상됨을 정량적으로 입증하였습니다 [Figure 1].
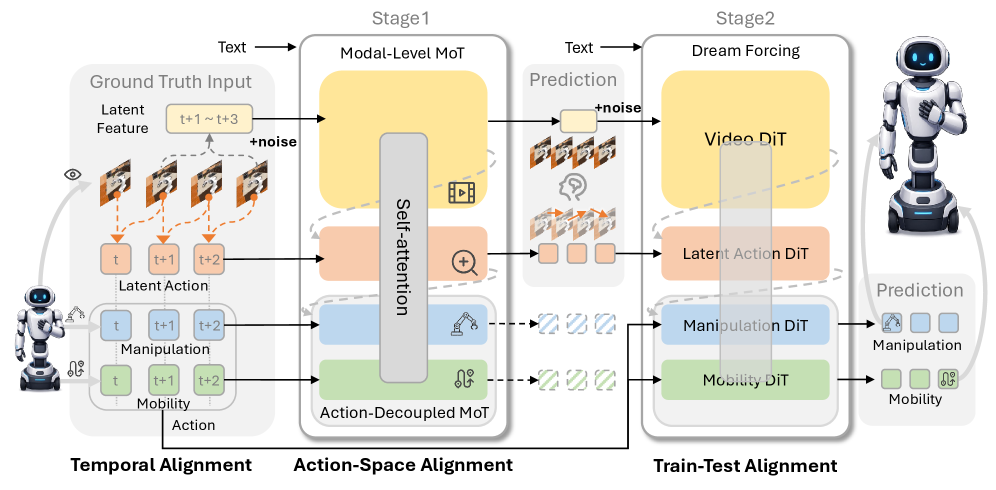
Figure 2 — D-MoT 기반의 모델 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 모바일 매니퓰레이션의 성능 향상이 단순히 모델 스케일이나 데이터 확장에만 의존하는 것이 아니라, 세계 모델링과 동작 추상화, 그리고 추론 시의 강건성 간의 정렬이 필수적임을 보여줍니다. 제안된 ABot-M0.5는 구조적 정렬을 통해 기존 WAM의 한계를 극복하고, 실제 환경에서의 복잡한 작업 수행 능력을 입증하였습니다. 이 연구는 범용 로봇이 복잡한 환경에서 이동과 조작을 동시에 수행할 수 있도록 하는 새로운 설계 방향을 제시하며, 향후 embodied AI 연구의 표준 프레임워크로 발전할 가능성을 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Cosmos 3: Omnimodal World Models for Physical AI
- [논문리뷰] EVA01: Unified Native 3D Understanding and Generation via Mixture-of-Transformers
- [논문리뷰] Representation Forcing for Bottleneck-Free Unified Multimodal Models
- [논문리뷰] HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
- [논문리뷰] Action Images: End-to-End Policy Learning via Multiview Video Generation
Review 의 다른글
- 이전글 [논문리뷰] Xiaomi-GUI-0 Technical Report
- 현재글 : [논문리뷰] ABot-M0.5: Unified Mobility-and-Manipulation World Action Model
- 다음글 [논문리뷰] AI translation of literary texts is 'fine', but readers still prefer human translations
댓글