[논문리뷰] GEAR: Guided End-to-End AutoRegression for Image Synthesis
링크: 논문 PDF로 바로 열기
메타데이터
저자: Bin Lin, Zheyuan Liu, Chenguo Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GEAR: Guided End-to-End AutoRegression의 약자로, VQ tokenizer와 AR generator를 end-to-end로 공동 학습시켜 생성 성능과 학습 속도를 최적화하는 프레임워크입니다.
- Dual Read-out: 코드북 할당을 hard와 soft 두 가지 방식으로 읽어내는 메커니즘으로, hard branch는 next-token prediction을 수행하고, differentiable soft branch는 representation alignment를 통해 tokenizer에 gradient를 전달합니다.
- Representation Alignment: DINOv2와 같은 사전 학습된 인코더의 특징을 생성 모델의 hidden states와 정렬하여 학습을 가속화하고 공간적 일관성을 강화하는 기법입니다.
- Straight-Through Estimator (STE): 이산적인 VQ index를 통해 gradient를 전파하기 위해 기존에 사용되던 근사 기법이나, 본 논문에서는 end-to-end 학습 시 불안정하여 코드북 붕괴를 초래함을 입증합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 시각적 생성 모델들이 tokenizer와 generator를 2단계로 분리하여 학습함으로써 발생하는 비효율성을 해결하고자 합니다 [Figure 2]. 기존 방식은 tokenizer가 단순히 재구성(reconstruction)만을 목적으로 학습되므로, AR generator가 학습하기 쉬운 잠재 공간(latent space)을 형성하지 못한다는 한계가 있습니다. 특히, 이산적인 VQ index의 비미분성으로 인해 Naive하게 end-to-end 학습을 시도할 경우 STE는 불안정한 학습 결과를 보이며 코드북의 붕괴를 야기합니다 [Figure 1]. 이를 극복하기 위해 제안된 GEAR는 모델 간의 학습 목적 충돌을 방지하면서도 효과적인 end-to-end guidance를 제공하는 방안을 제시합니다.
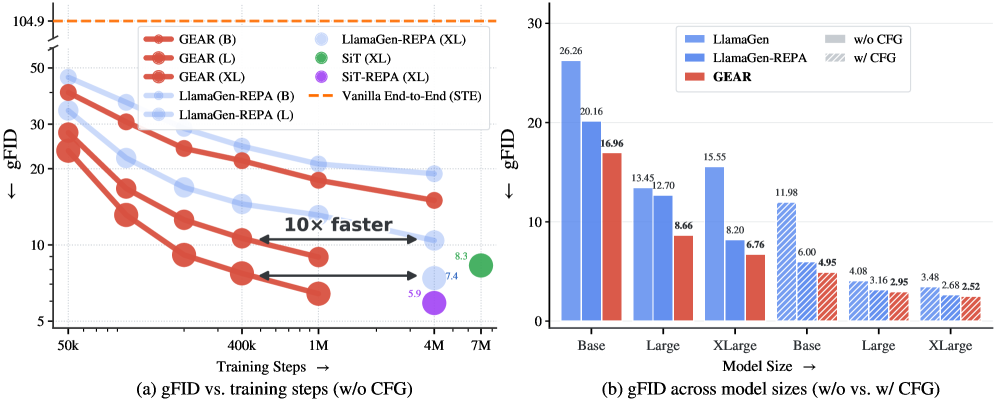
Figure 1 — GEAR의 학습 속도 및 성능 개선
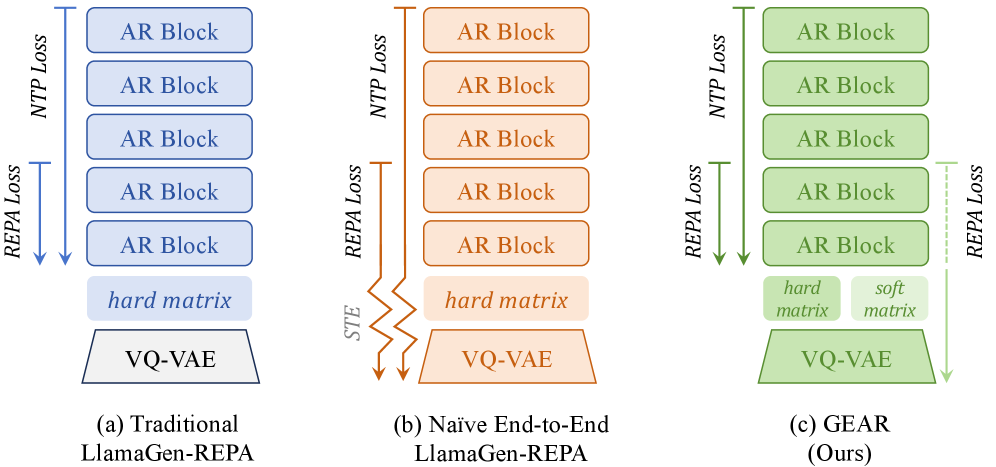
Figure 2 — GEAR 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
GEAR는 코드북 할당을 hard one-hot branch와 differentiable soft branch로 나누어 처리하는 dual read-out 전략을 핵심 방법론으로 제안합니다 [Figure 2]. 하드 브랜치는 추론 시 사용되는 이산적 토큰을 통해 next-token prediction (NTP)을 수행하며, 소프트 브랜치는 temperature-scaled 소프트맥스를 통해 representation alignment 손실을 계산하여 tokenizer로 역전파합니다. 이를 통해 AR generator의 지식은 tokenizer를 보다 예측 가능한(predictable) 토큰 분포로 유도합니다 [Figure 4]. 실험 결과, ImageNet 벤치마크에서 GEAR는 LlamaGen-REPA 대비 최대 10배 빠른 gFID 수렴 속도를 기록하였습니다 [Figure 1]. 또한, GPIC 데이터셋을 이용한 text-to-image 학습에서 동일한 계산 비용으로 더 우수한 성능을 달성하였으며, 특히 NTP 손실 수렴은 2.5배, REPA 정렬 손실 수렴은 11.1배 가속화되었습니다 [Figure 3].
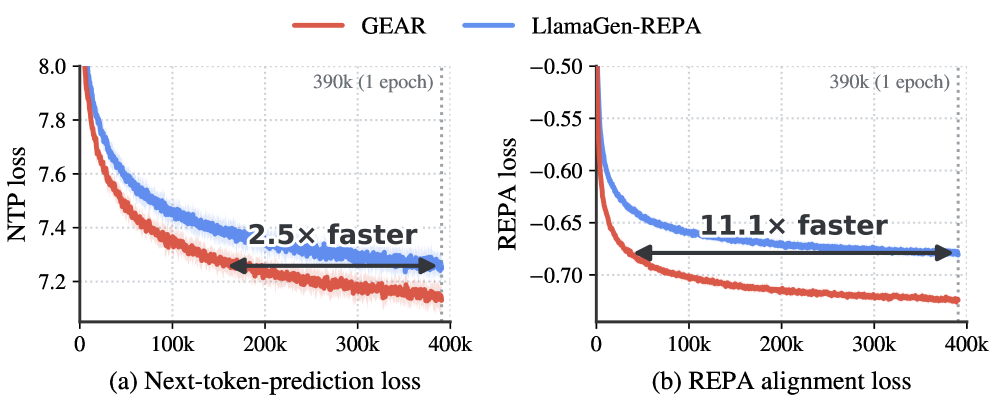
Figure 3 — GPIC 데이터셋 학습 동학 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 GEAR를 통해 기존의 VQ-AR 모델 학습에서 고착화된 2단계 학습 구조를 end-to-end로 통합하는 새로운 프레임워크를 정립하였습니다. 이 방법론은 tokenizer가 단순 재구성 임무를 넘어 generator의 예측 용이성을 보조하도록 구조화함으로써 생성 품질과 학습 효율성을 동시에 달성했습니다. 본 연구의 시사점은 representation alignment의 중심축을 tokenizer에서 AR generator로 재배치함으로써 최신 LLM-style 생성 모델의 한계를 극복했다는 데 있으며, 향후 다양한 도메인의 시각적 생성 과제에 널리 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] BrainJanus: A Unified Model for Understanding and Generation across Brain, Vision, and Language
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
- [논문리뷰] Distill Once, Adapt Life-Long: Exploring Dataset Distillation for Continual Test-Time Adaptation
Review 의 다른글
- 이전글 [논문리뷰] FlexiSLM: A Dynamic and Controllable Frame Rate Spoken Language Model
- 현재글 : [논문리뷰] GEAR: Guided End-to-End AutoRegression for Image Synthesis
- 다음글 [논문리뷰] LUMOS: A Semantic Operating-System Layer for Accessibility-Grounded AI Agents
댓글