[논문리뷰] FlexiSLM: A Dynamic and Controllable Frame Rate Spoken Language Model
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiaqi Li, Chaoren Wang, Xiaohai Tian, Mingjie Chen, Xinyu Liang, Xu Li, Yufan Lin, Junwen Qiu, Jun Zhang, Lu Lu, Haizhou Li, Zhizheng Wu
1. Key Terms & Definitions (핵심 용어 및 정의)
- FlexiSLM: 동적이고 조절 가능한(dynamic and controllable) frame rate를 지원하는 최초의 Spoken Language Model.
- Frame Merging Module: 음성 정보의 밀도에 따라 인접한 프레임을 병합하여 토큰 수를 압축하는 모듈.
- FlexiCodec: 음성 입력을 가변적인 frame rate로 변환하고 재구성할 수 있도록 하는 사전 학습된 오디오 토크나이저.
- Direct Frame-Rate Control: 사용자가 목표 평균 frame rate를 직접 입력 신호로 지정하여 추론 과정에서 생성 속도를 제어하는 기법.
- Thinker-Talker Architecture: LLM Backbone(Thinker)이 음성 이해 및 계획을 담당하고, Talker Transformer가 최종 speech token을 생성하는 구조.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Spoken Language Model(SLM)들이 고정된 frame rate(fixed frame rate)를 사용하여 불필요한 연산 자원을 낭비하고, 추론 시 속도와 품질 간의 유연한 조절이 불가능하다는 문제를 해결하고자 한다. [Figure 1] 기존의 SLM은 음성의 시간적 변화와 정보 밀도 차이를 무시한 채 고정된 단위로 데이터를 처리하여 실시간 서비스 환경에서의 최적화가 어렵다. 이러한 한계를 극복하기 위해 저자들은 음성 데이터의 비균일성을 활용하여 효율성을 높이고, 다양한 배포 환경(예: 장치 성능, 네트워크 상태)에 맞게 frame rate를 실시간으로 제어할 수 있는 새로운 접근 방식을 제안한다. [Figure 1]
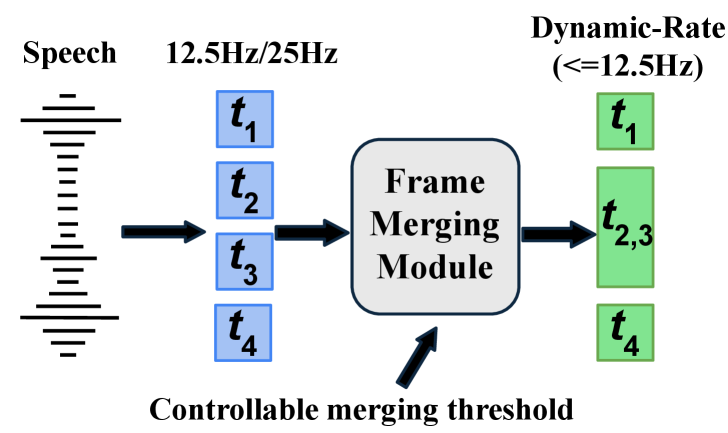
Figure 1 — 동적 frame rate 전략 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 FlexiSLM이라는 동적/가변적 frame rate SLM 프레임워크를 제안하여 음성 입력과 출력 모두에서 효율적인 정보 처리를 달성한다. 저자들은 Frame Merging Module을 도입하여 입력 음성에서 정보 밀도가 낮은 구간을 병합하고, 이를 통해 토큰 시퀀스의 길이를 동적으로 압축한다. [Figure 2] 특히, 사용자나 시스템이 추론 시 목표 평균 frame rate를 직접 설정할 수 있도록 Direct Frame-Rate Control을 구현하여 학습 재훈련 없이도 다양한 환경에서 유연한 연산이 가능하다. [Figure 3] Talker Transformer는 LLM의 출력과 타겟 frame rate 정보를 결합하여 최적화된 오디오 토큰을 생성한다. [Figure 3] 실험 결과, FlexiSLM-7B는 고정된 frame rate를 사용하는 7B급 모델들(예: Qwen2.5-Omni, Kimi-Audio) 대비 고품질 운영 환경에서 우수한 성능을 입증했다. 또한, 12.5Hz 대비 6.25Hz 설정에서 추론 시간을 약 50% 단축하면서도 높은 음성 대 음성(speech-to-speech) 품질을 유지하였으며, 4.0Hz까지 안정적인 수준으로 생성을 제어할 수 있음을 확인하였다.
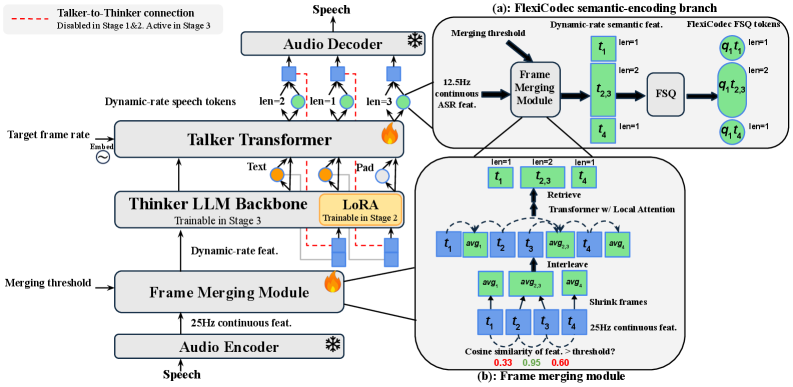
Figure 2 — FlexiSLM 전체 아키텍처
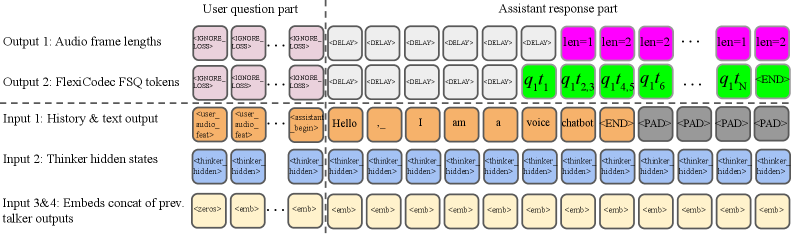
Figure 3 — Talker Transformer 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Dynamic frame rate 기반의 SLM이 가진 효율성과 제어 가능성을 입증함으로써 음성 생성 기술의 새로운 패러다임을 제시하였다. FlexiSLM은 고정된 frame rate라는 기존 연구의 한계를 타파하고, 실제 산업 현장에서의 이기종(heterogeneous) 컴퓨팅 자원 배포 시 매우 실용적인 솔루션을 제공한다. 본 연구의 결과는 향후 더 경량화되고 즉각적인 반응이 필요한 실시간 음성 대화 시스템 개발에 중요한 학술적/기술적 기반이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ReFreeKV: Towards Threshold-Free KV Cache Compression
- [논문리뷰] Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
- [논문리뷰] Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
- [논문리뷰] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It
Review 의 다른글
- 이전글 [논문리뷰] Evolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks
- 현재글 : [논문리뷰] FlexiSLM: A Dynamic and Controllable Frame Rate Spoken Language Model
- 다음글 [논문리뷰] GEAR: Guided End-to-End AutoRegression for Image Synthesis
댓글