[논문리뷰] RODS: Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ruishan Fang, Siyuan Lu, Chenyi Zhuang, Tao Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRPO (Group Relative Policy Optimization): 본 논문에서 에이전트 학습을 위해 사용하는 RL 알고리즘으로, 여러 rollout을 통해 얻은 보상의 상대적 우위(advantage)를 산출합니다.
- Progress Reward ($R_P$): 복잡한 다단계 작업에서 전체적인 성공 여부뿐만 아니라 부분적인 진행도를 보상으로 부여하여 보상 희소성(reward sparsity) 문제를 해결하는 연속적 보상 지표입니다.
- Capability Boundary: 에이전트가 완벽하게 학습한 영역(mastered)과 도달할 수 없는 영역(hard) 사이의 경계로, 주로 보상 평균값이 약 0.5 근처에 분포하며 모델의 학습에 가장 유용한 gradient 신호를 제공하는 구간입니다.
- Skill-Aligned Resampling: 시드 데이터의 API 의존성 및 복잡도 프로파일(structural complexity)을 유지하면서 새로운 쿼리 변형을 생성하여 구조적 일관성을 보존하는 합성 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Multi-turn Tool-Use 에이전트 학습 시 발생하는 데이터 부족 및 정보 밀도 감소 문제를 해결하고자 합니다. 기존 Agentic RL 연구들은 고품질 다단계 데이터셋 구축 비용이 매우 높고, 학습이 진행됨에 따라 정적 데이터셋이 에이전트의 현재 능력 범위에서 벗어나 gradient 학습 효율이 급격히 저하되는 문제에 직면해 있습니다 [Figure 1]. 또한, 무분별한 데이터 합성은 궤적의 논리적 일관성을 해치는 semantic disjointedness 문제를 초래합니다 [Figure 1]. 따라서 저자들은 에이전트의 현재 능력과 보조를 맞추며 끊임없이 진화하는 학습 데이터 생성 프레임워크의 필요성을 제기합니다.
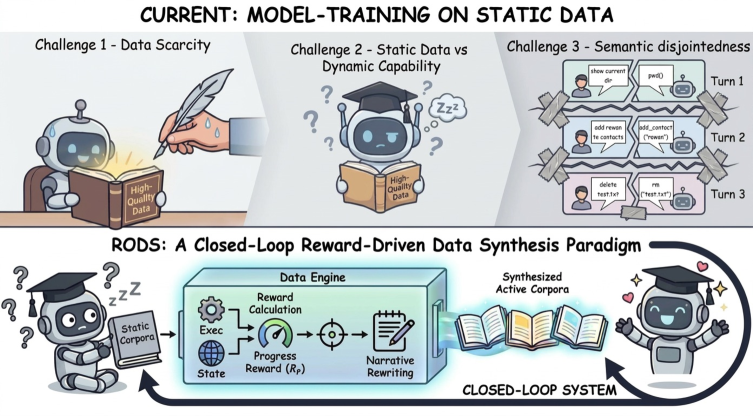
Figure 1 — 정적 데이터 vs RODS
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RODS (Reward-Driven Online Data Synthesis) 프레임워크를 제안하며, 이는 RL 학습 루프와 실시간 데이터 생성을 밀접하게 결합합니다 [Figure 2]. 핵심 방법론은 GRPO 학습 과정에서 발생하는 rollout 보상의 분산(variance)이 Capability Boundary 영역에서 가장 크다는 사실에 기반합니다 [Figure 3]. RODS는 이 분산 값을 저비용 boundary 감지기로 활용하여, 학습에 가장 유용한 샘플을 지속적으로 식별하고 재합성합니다. 합성 과정에서는 시드 데이터의 의존성 구조를 보존하는 skill-aligned 파이프라인을 도입하여 논리적 일관성을 보장합니다 [Figure 2]. 실험 결과, RODS는 단 400개의 휴먼 시드 데이터로 약 800개의 활성 학습 샘플을 유지하며, 17K 규모의 오프라인 합성 파이프라인과 유사한 성능을 달성했습니다 [Table 1]. 특히, Qwen3-4B-Instruct 모델 기준, 정적 데이터셋 대비 +33.87%, 기존 EnvTuning 대비 +5.50%의 높은 성능 향상을 보여주며 데이터 효율성 측면에서의 우위를 증명했습니다 [Table 1].
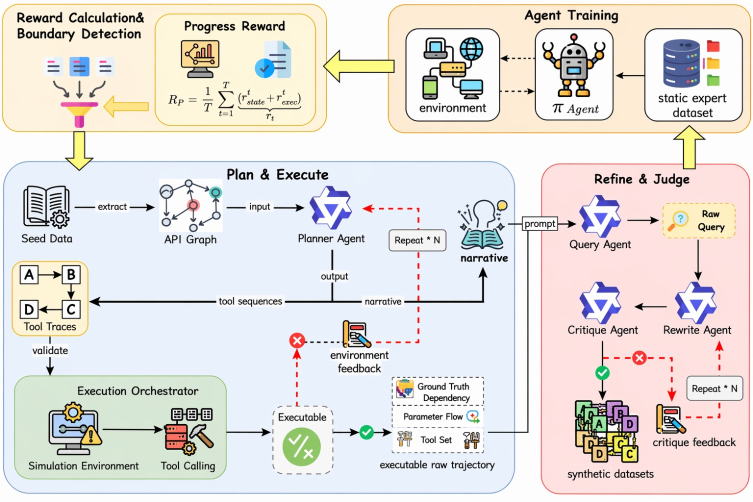
Figure 2 — RODS 아키텍처
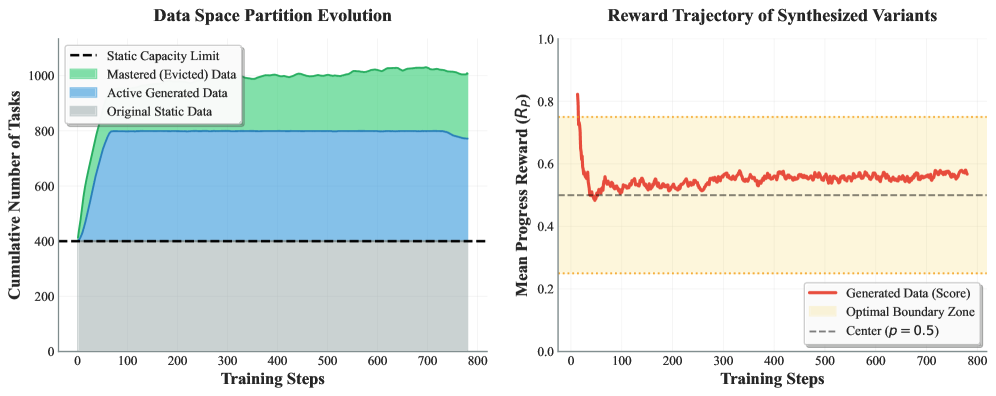
Figure 3 — 동적 데이터 생성 및 검증
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고비용의 데이터셋 확보 없이도 실시간 보상 분산 추적을 통해 에이전트의 학습 효율을 극대화하는 RODS 프레임워크를 정립하였습니다. 연구 결과는 정적인 데이터셋이 가질 수밖에 없는 한계를 극복하고, 에이전트의 능력치 변화에 따라 학습 데이터도 진화해야 한다는 새로운 패러다임을 제시합니다. 본 연구의 성과는 학계의 데이터 부족 문제 해결뿐만 아니라, 산업계의 Tool-Use 에이전트 개발 비용 절감 및 범용적 적용 가능성을 넓히는 데 크게 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
- [논문리뷰] CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
- [논문리뷰] Search More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization
- [논문리뷰] OmegaUse: Building a General-Purpose GUI Agent for Autonomous Task Execution
- [논문리뷰] DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
Review 의 다른글
- 이전글 [논문리뷰] Physics-IQ Verified
- 현재글 : [논문리뷰] RODS: Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
- 다음글 [논문리뷰] Reinforcing Dual-Path Reasoning in Spatial Vision Language Models
댓글