[논문리뷰] FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jinghong Lan, Wei Cheng, Yunuo Chen, Ziqi Ye, Peng Xing, Yixiao Fang, Rui Wang, Yufeng Yang, Xuanyang Zhang, Xianfang Zeng, Difan Zou, Gang Yu, Chi Zhang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- FreeStyle: 커뮤니티에서 생성된 LoRA 모델을 활용하여 대규모 스타일-콘텐츠 이중 참조 데이터셋을 구축하고, 이를 통해 정밀한 제어가 가능한 스타일-콘텐츠 이중 참조 생성을 수행하는 프레임워크입니다.
- Dual-Reference Generation: 콘텐츠 참조(Content Reference)의 구조와 스타일 참조(Style Reference)의 시각적 속성을 텍스트 지시사항에 따라 동시에 합성하는 고난도 생성 작업입니다.
- Attention Enrichment Constraint: 스타일 참조 이미지로부터의 콘텐츠 누출을 방지하기 위해 생성 과정의 초기 Transformer 블록에서 어텐션 맵(Attention Map)의 비대칭성을 조절하는 학습 제약 기법입니다.
- Frequency-Aware RoPE Modulation: 듀얼 참조 단계에서 고주파 RoPE 성분을 억제하고 저주파 성분을 증폭하여, 위치 대응을 통한 patch-level 복사(copying) 현상을 차단하는 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 스타일과 콘텐츠를 동시에 참조하는 Dual-Reference Generation 작업에서 발생하는 콘텐츠 누출(Content Leakage) 및 구조 왜곡 문제를 해결하고자 합니다. 기존 방식들은 대규모의 고품질 Triplet 데이터셋의 부재로 인해 콘텐츠와 스타일의 정밀한 분리가 어렵고, 생성 과정에서 스타일 참조 이미지의 정보가 원치 않는 방식으로 전이되는 현상을 효과적으로 제어하지 못한다는 한계가 있습니다. 특히, 기존 평가는 개별 지표를 단일 점수로 통합하여 모델의 성능을 오도할 위험이 있으므로, 본 논문은 데이터 구축부터 disentanglement 전략, 그리고 체계적인 평가 벤치마크까지 아우르는 통합된 프레임워크를 제안합니다. [Figure 1]에 명시된 것처럼 본 연구는 커뮤니티 LoRA를 활용한 효율적인 데이터 마이닝 파이프라인을 구축하여 이를 해결합니다.

Figure 1 — 전체 데이터 파이프라인 및 생성 프로세스를 요약한 핵심 아키텍처 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 2단계 학습 커리큘럼과 각 단계별 맞춤형 disentanglement 전략을 결합하여 스타일-콘텐츠 간의 강력한 제어 능력을 확보합니다. 1단계에서는 스타일 전이 데이터를 기반으로 Attention Enrichment Constraint를 적용하여 어텐션 맵의 과도한 비대칭성을 보정하고, 2단계에서는 듀얼 참조 설정에서 Frequency-Aware RoPE Modulation을 도입하여 공간적 복사를 차단합니다. 이러한 전략은 추가적인 아키텍처 변경 없이 모델의 학습 최적화만으로 효과적인 분리를 달성합니다. 실험 결과, FreeStyle은 SRef 및 CRef+SRef 벤치마크에서 기존 오픈소스 방법론 대비 우수한 성능을 입증했습니다. 정량적으로 VLM-Style 점수와 Ver-S 지표에서 최상위권을 기록하였으며, 이는 스타일 정렬과 콘텐츠 보존 사이의 최적의 균형을 유지하고 있음을 시사합니다. [Table 1]과 [Table 2]에서 확인할 수 있듯이, 본 모델은 스타일 fidelity와 콘텐츠 보존력 모두에서 높은 신뢰도를 보여줍니다.
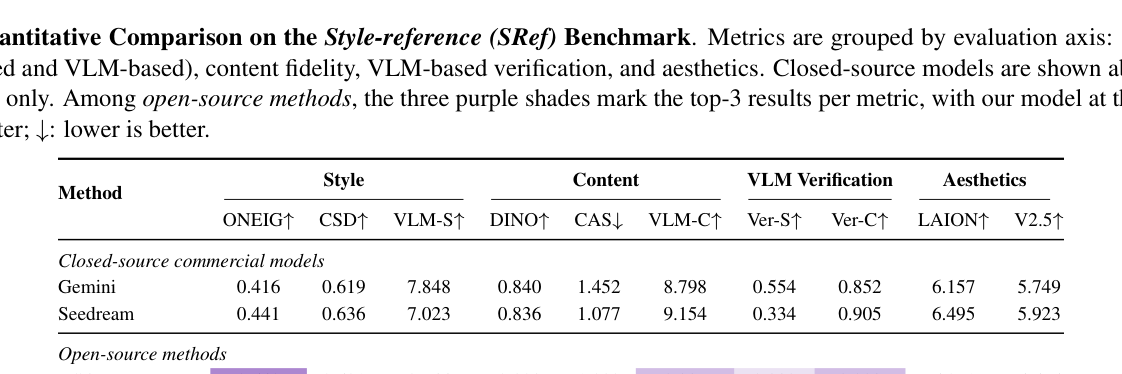
Table 1 — 기존 방법론들과의 정량적 성능 비교를 보여주는 핵심 결과 표

Table 2 — 듀얼 참조 생성 환경에서의 정량적 성능 우위를 보여주는 결과 표
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 커뮤니티 LoRA 마이닝 기반의 데이터 구축과 단계적 disentanglement 학습을 통해 스타일-콘텐츠 이중 참조 생성의 새로운 표준을 제시합니다. 제안된 프레임워크는 고품질의 triplet 데이터를 대규모로 자동 생성할 수 있는 파이프라인을 제공하며, 특히 콘텐츠 누출을 방지하는 정밀한 제어 기법은 생성 모델의 controllability를 획기적으로 개선합니다. 이 연구는 앞으로의 다중 참조 기반 제어 생성 연구에 중요한 이정표가 될 것이며, 실용적인 디자인 및 예술 작업 분야에서 AI 모델의 활용도를 대폭 확장할 것으로 기대됩니다.
Part 2: 중요 Figure 정보
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Cow of Rembrandt - Analyzing Artistic Prompt Interpretation in Text-to-Image Models
- [논문리뷰] Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
- [논문리뷰] Sumi: Open Uniform Diffusion Language Model from Scratch
- [논문리뷰] Text-Vision Co-Instructed Image Editing
- [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
Review 의 다른글
- 이전글 [논문리뷰] FlowBender: Feedback-Aware Training for Self-Correcting Conditional Flows
- 현재글 : [논문리뷰] FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining
- 다음글 [논문리뷰] Holo-World: Unified Camera, Object and Weather Control for Video World Model
댓글