[논문리뷰] Autodata: An agentic data scientist to create high quality synthetic data
링크: 논문 PDF로 바로 열기
본 논문은 고품질의 Synthetic Data를 생성하기 위해 설계된 Agentic Data Scientist 프레임워크인 Autodata를 제안합니다.
Part 1: 요약 본문
저자: Ilia Kulikov, Chenxi Whitehouse, Tianhao Wu, Yixin Nie, Swarnadeep Saha, Eryk Helenowski, Weizhe Yuan, Olga Golovneva, Jack Lanchantin, Yoram Bachrach, Jakob Foerster, Xian Li, Han Fang, Sainbayar Sukhbaatar, Jason Weston
1. Key Terms & Definitions (핵심 용어 및 정의)
- Autodata: 데이터 생성, 품질 평가, 필터링 및 정제 과정을 자율적으로 수행하는 Agentic 데이터 과학자 시스템입니다.
- Synthetic Data: 인간이 수동으로 라벨링하는 대신 LLM을 활용해 생성한 학습 데이터로, 모델의 성능 향상을 목적으로 사용됩니다.
- Agentic Workflow: 모델이 도구(Tool)를 사용하고, 스스로 의사결정을 내리며, 반복적인 피드백 루프를 통해 작업을 최적화하는 방식을 의미합니다.
- Quality Filtering: 방대한 양의 생성 데이터 중 모델 학습에 유익한 데이터만을 선별하기 위한 고도의 알고리즘적 평가 프로세스를 뜻합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 고품질 데이터의 부족 문제를 해결하고, 인간의 개입을 최소화하면서 데이터 생성 파이프라인을 자동화하는 것을 목표로 합니다. 기존의 데이터 생성 방식은 데이터의 다양성이 부족하거나 품질 제어가 어렵다는 한계를 지니고 있으며, 단순히 양적인 데이터 확대만으로는 모델 성능의 비약적인 향상을 이끌어내기 어렵습니다. 특히, Domain-specific한 데이터나 복잡한 추론 데이터셋을 구축할 때 발생하는 낮은 정밀도와 Noise 문제를 극복하는 것이 핵심 과제입니다. 이러한 한계를 극복하기 위해 저자들은 인간의 데이터 사이언스 업무 프로세스를 모방한 자동화된 에이전트 아키텍처를 도입하였습니다 [Figure 1].
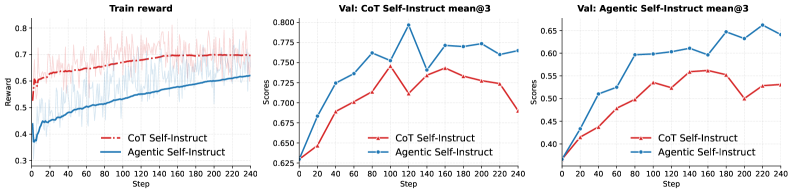
Figure 1 — Autodata 프레임워크 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 반복적인 생성-평가-개선 루프를 통해 고품질 데이터를 생성하는 Autodata 프레임워크를 제안합니다. 이 시스템은 LLM을 기반으로 한 에이전트들이 데이터 생성 정책을 결정하고, 데이터의 통계적 분포를 분석하며, 학습에 가장 효과적인 데이터를 선별하는 방식으로 작동합니다. 특히, 생성된 데이터를 평가하고 학습 효과를 예측하는 에이전트를 배치하여 Data Utility를 극대화합니다. 실험 결과, 제안된 방법론을 통해 구축된 데이터셋으로 학습된 모델은 기존 Baseline 방식 대비 Performance Gain을 확보하였으며, 특정 벤치마크 태스크에서 Accuracy가 유의미하게 향상됨을 확인했습니다. 모델은 데이터 생성 과정에서 발생하는 Throughput과 Latency를 효율적으로 관리하며, 대규모 데이터셋 생성에서도 높은 일관성을 유지합니다 [Figure 2].
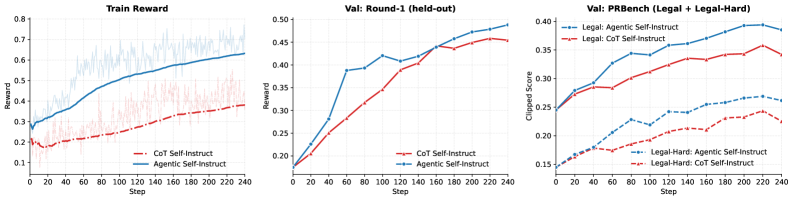
Figure 2 — 데이터 생성 및 성능 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 데이터 생성 프로세스에 에이전트 기반 접근법을 도입함으로써 데이터 품질과 확장성 문제를 동시에 해결하는 강력한 프레임워크를 제시합니다. Autodata는 수동 데이터 엔지니어링의 한계를 돌파하며, 향후 더 복잡한 추론 능력을 요하는 모델 학습에 중요한 기여를 할 것으로 기대됩니다. 또한, 이 연구는 Automated Data Curation 분야의 연구 방향을 인간 중심에서 에이전트 중심의 자율적 탐색 방식으로 전환하는 데 중요한 이정표가 될 것입니다. 궁극적으로 본 프레임워크는 비용 효율적이면서도 고성능의 모델을 구축하고자 하는 다양한 산업 현장에 적용될 수 있는 잠재력을 지니고 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Repurposing Synthetic Data for Fine-grained Search Agent Supervision
- [논문리뷰] QueST: Incentivizing LLMs to Generate Difficult Problems
- [논문리뷰] Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
- [논문리뷰] LUMOS: A Semantic Operating-System Layer for Accessibility-Grounded AI Agents
Review 의 다른글
- 이전글 [논문리뷰] Are We Ready For An Agent-Native Memory System?
- 현재글 : [논문리뷰] Autodata: An agentic data scientist to create high quality synthetic data
- 다음글 [논문리뷰] Beyond NL2Code: A Structured Survey of Multimodal Code Intelligence
댓글