[논문리뷰] Beyond NL2Code: A Structured Survey of Multimodal Code Intelligence
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xuanle Zhao, Qiushi Sun, Jingyu Xiao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multimodal Code Intelligence: 시각적 입력(Screenshot, 차트, CAD 등)을 실행 가능한 코드(Executable Code)로 변환하거나, 시각적 맥락 하에서 코드를 생성·편집·추론하는 연구 분야를 지칭합니다.
- Direct Generation: 시각적 맥락(Visual Context)과 텍스트 프롬프트를 입력으로 받아, 이를 구현하는 코드를 한 번에 생성하는 태스크입니다.
- Executable Policy: 코드를 단순히 시각적 결과물이 아닌, 특정 환경 내에서 상태 전이(State Transition)를 유도하는 제어 정책(Control Policy)으로 활용하는 프레임워크입니다.
- Multimodal LLM (MLLM): 시각적 정보와 텍스트 정보를 동시에 처리하고, 이를 바탕으로 코드 생성 및 논리적 추론을 수행하는 핵심 모델 아키텍처입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 NL2Code 모델이 텍스트 중심의 명세에만 의존하여, 시각적 정보가 필수적인 실제 프로그래밍 작업의 복잡도를 완전히 해결하지 못한다는 점을 지적합니다. [Figure 1] 기존 연구들은 고수준의 인간 의도를 코드로 변환하는 데 성공했으나, UI 설계, 과학적 시각화, CAD 등 시각적 데이터가 중요한 도메인에서는 텍스트만으로 공간적 구조나 미세한 기하학적 제약 조건을 표현하는 데 한계가 있습니다. 이러한 modality gap을 해소하기 위해 저자들은 시각적 입력을 단순한 보조 정보가 아닌 핵심 요소로 다루는 Multimodal Code Intelligence의 필요성을 강조합니다. 특히, 생성된 코드의 정확성을 평가할 때 단순한 visual similarity를 넘어 의미론적(semantic) 및 상호작용(interaction) 검증이 필요함을 문제로 제기합니다.
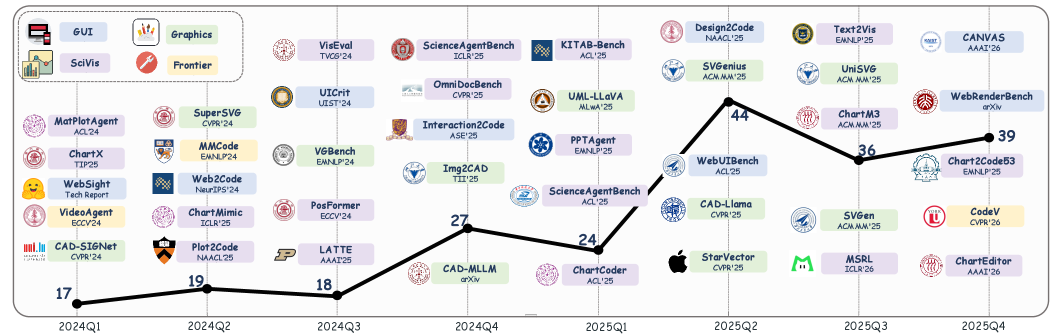
Figure 1 — 멀티모달 코드 지능 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Multimodal Code Intelligence를 체계적으로 분류하기 위해 Graphical User Interface, Scientific Visualization, Structured Graphics, Frontier Tasks의 4가지 도메인으로 나눈 새로운 분류 체계(Taxonomy)를 제안합니다. [Figure 3] 각 도메인 내에서 코드는 렌더링된 결과물(rendered artifact), 편집 가능한 구조(editable structure), 또는 환경과 상호작용하는 정책(executable policy)으로서의 역할을 수행합니다. 연구진은 또한 코드의 역할에 따라 직접 생성(Direct Generation), 지시 기반 편집(Instruction-driven Editing), 참조 기반 정제(Reference-based Refinement)로 방법론을 공식화합니다. 실험적 분석 결과, 대규모 SFT(Supervised Fine-Tuning)를 거친 MLLM 기반 방법론들이 기존의 템플릿 기반 방식 대비 비약적인 성능 향상을 보였으나, 여전히 복잡한 상호작용 환경에서의 실행 정확도(Execution Accuracy)는 과제로 남아 있습니다. [Figure 4] 특히 Web-to-Code 분야에서는 브라우저 환경을 활용한 정적/동적 검증이 모델의 성능을 측정하는 핵심 지표로 자리 잡았으며, 다단계 에이전트(Multi-agent) 시스템이 단일 모델보다 복합적인 UI 구축에서 높은 Throughput과 정확도를 나타냄을 확인했습니다. [Figure 5]
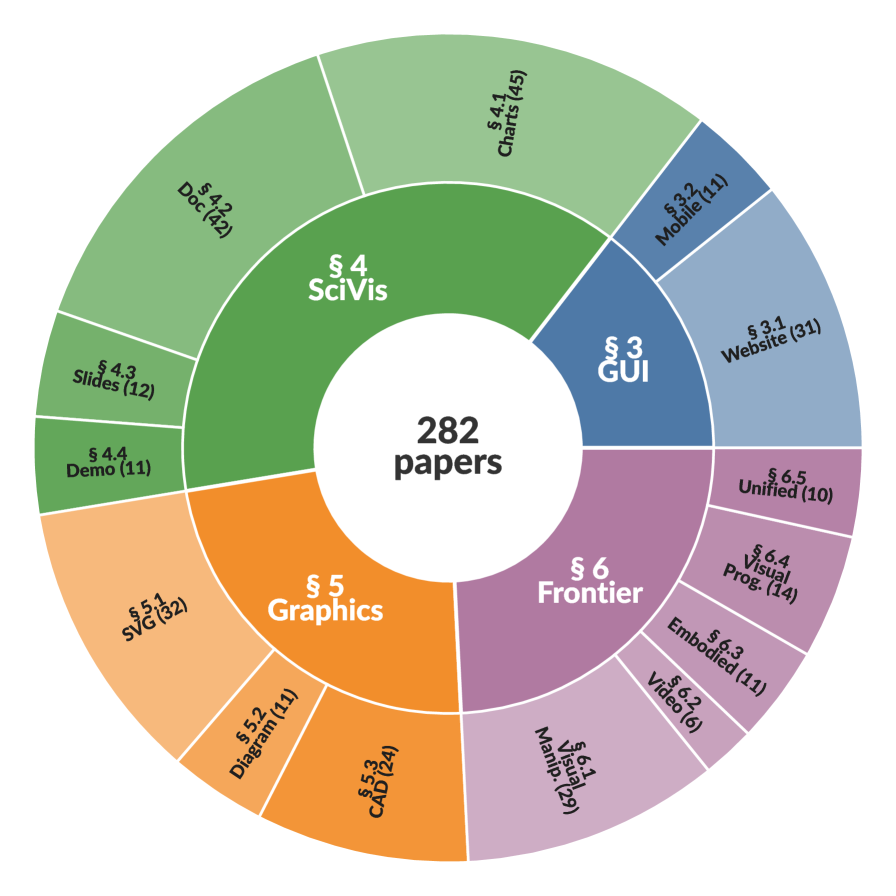
Figure 3 — 벤치마크 분류 체계
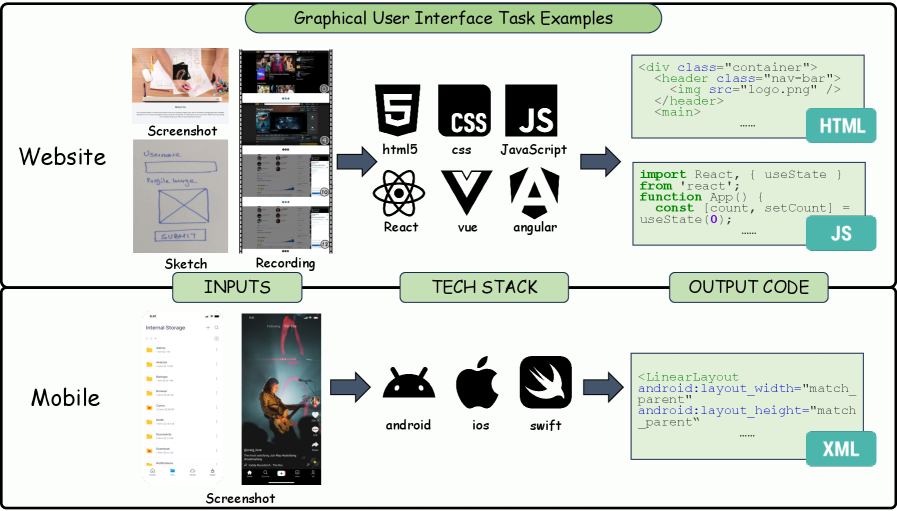
Figure 5 — GUI 코드 생성 예시
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Multimodal Code Intelligence의 현주소를 진단하고, 향후 연구 방향으로 다중 신호 검증(Multi-signal validation), 상태 기반 검증(Multi-state verification), 에이전트 추적 검증(Verifiable agent traces)을 제시합니다. 이 연구는 단순히 코드를 생성하는 단계를 넘어, 시각적 증거에 기반하여 실행 가능한 소프트웨어 시스템을 자율적으로 구축하는 에이전트 연구로의 패러다임 전환을 시사합니다. 학계와 산업계는 이 분류 체계를 통해 파편화된 멀티모달 코드 생성 연구들을 통합적으로 이해하고, 신뢰성 있는 실행 가능 시스템 구축에 집중할 수 있을 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Code-Space Response Oracles: Generating Interpretable Multi-Agent Policies with Large Language Models
- [논문리뷰] JanusCoder: Towards a Foundational Visual-Programmatic Interface for Code Intelligence
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Symbolic Graphics Programming with Large Language Models
- [논문리뷰] Evolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks
Review 의 다른글
- 이전글 [논문리뷰] Autodata: An agentic data scientist to create high quality synthetic data
- 현재글 : [논문리뷰] Beyond NL2Code: A Structured Survey of Multimodal Code Intelligence
- 다음글 [논문리뷰] CAVEWOMAN: How Large Language Models Behave Under Linguistic Input and Output Compression
댓글