[논문리뷰] CAVEWOMAN: How Large Language Models Behave Under Linguistic Input and Output Compression
링크: 논문 PDF로 바로 열기
메타데이터
저자: Morayo Danielle Adeyemi, Ryan A. Rossi, Franck Dernoncourt
1. Key Terms & Definitions (핵심 용어 및 정의)
- Input Compression: 사용자 프롬프트에서 불필요한 토큰을 제거하여 입력 길이를 줄이는 기법으로, 본 논문에서는 Part-of-Speech(POS) 필터링을 사용하여 구현함.
- Output Compression: 모델의 응답에 대해 특정 시스템 프롬프트를 적용하여 생성되는 텍스트의 길이를 강제로 제한하는 기법.
- Realized Cost: 모델의 입출력 토큰 수와 실제 토큰 가격을 반영한 실제 추론 비용.
- Bidirectional NLI (Natural Language Inference): 생성된 텍스트와 원본(Unconstrained) 참조 텍스트 간의 의미적 일치 여부를 판단하기 위한 평가 방식.
- Dissociation Table: 모델의
Accuracy와Reference-text Agreement(원본과의 의미적 일치도)를 2x2 매트릭스로 분석하여, 성능은 유지되나 추론 과정이 변질되는 현상을 시각화하는 도구 [Table 1].
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
대부분의 기존 연구는 입력 프롬프트 압축이나 출력 길이 제어 중 하나에만 집중하며, 이를 단순히 Task Accuracy 관점에서만 평가한다 [Figure 1]. 그러나 짧은 프롬프트가 반드시 낮은 비용으로 이어지지는 않으며, 특히 Output Compression 상황에서 모델이 생성하는 응답의 의미적 일관성이 유지되는지에 대한 근본적인 검증이 부족하다. 저자들은 기존의 평가 방식이 Realized Cost와 Semantic Fidelity(의미적 충실도)를 제대로 반영하지 못한다는 점을 지적하며, 두 채널을 통합적으로 평가하는 새로운 프로토콜인 CAVEWOMAN을 제안한다.
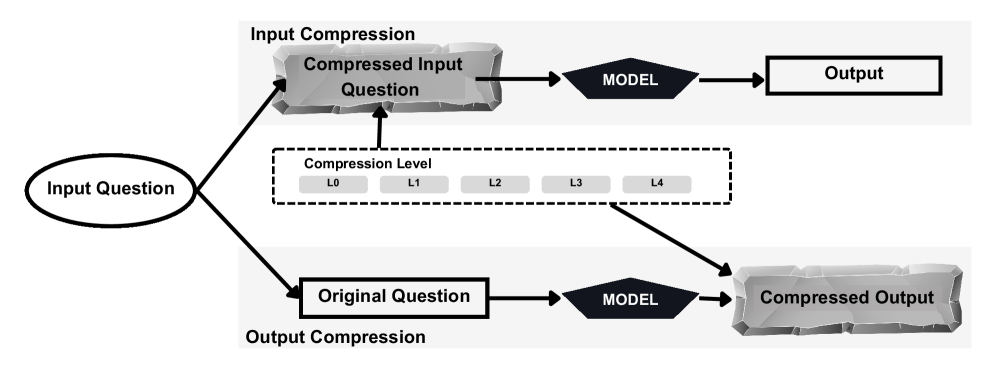
Figure 1 — CAVEWOMAN 평가 프레임워크 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 8개의 모델과 5개의 데이터셋을 대상으로 5단계의 Linguistic Reduction(L0L4) 수준에서 입출력 압축을 체계적으로 실험하였다 [Figure 2]. CAVEWOMAN 프로토콜은 입출력 토큰 비용, 2.4배 절감하는 데 성공하였으나, Input Compression은 모델이 보상 심리로 더 긴 응답을 생성하여 비용이 오히려 최대 1.8~2.7배 상승하는 'lose-lose' 상황을 초래함을 확인하였다 [Figure 3]. 특히, Output Compression 환경에서 정답률(Task Accuracy, 그리고 Reference-text Agreement라는 세 가지 핵심 축으로 생성물을 평가한다. 실험 결과, Output Compression은 대부분의 API 모델에서 실질 추론 비용을 1.4Accuracy)은 유지되더라도 모델의 내부 추론 과정(Reasoning trace)은 원본과 크게 달라지는 '탈동조화(Decoupling)' 현상이 발견되었다. 비추론(Non-reasoning) 모델의 경우, L1 수준의 압축 응답 중 51.9%가 정답임에도 불구하고 원본 참조 텍스트와 의미적으로 일치하지 않는 것으로 나타났다 [Finding 2].
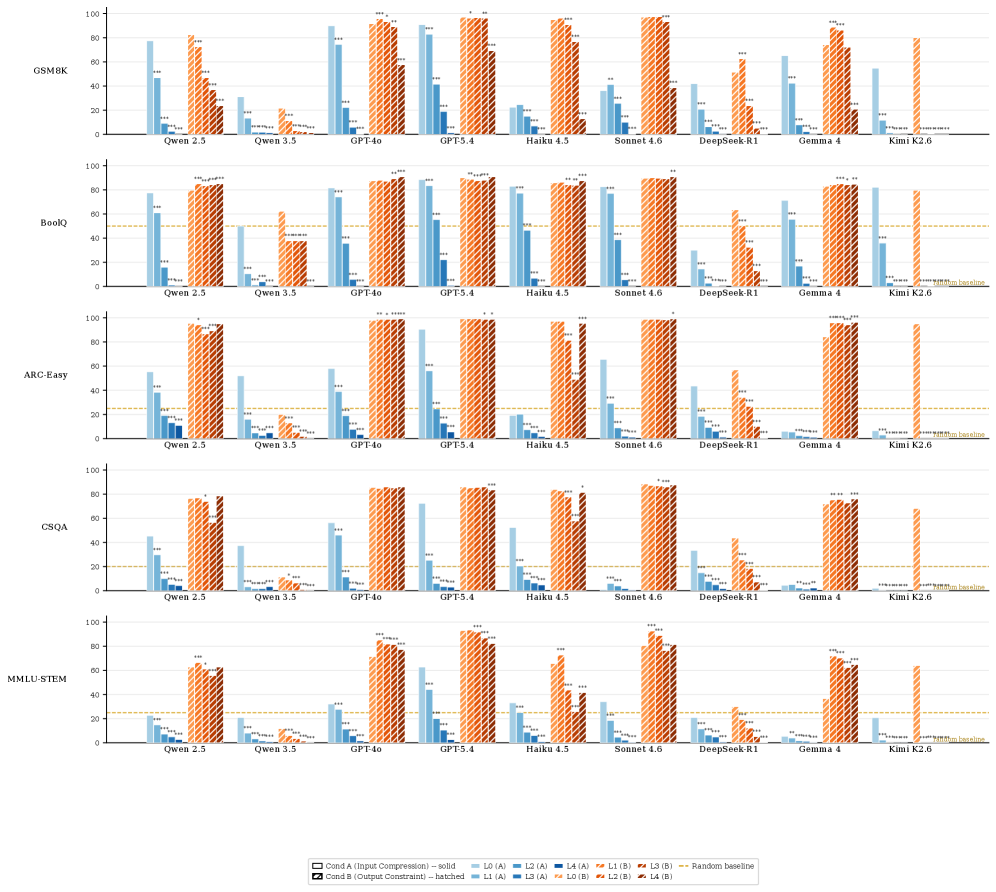
Figure 2 — 모델별 압축 수준에 따른 Task Accuracy 비교
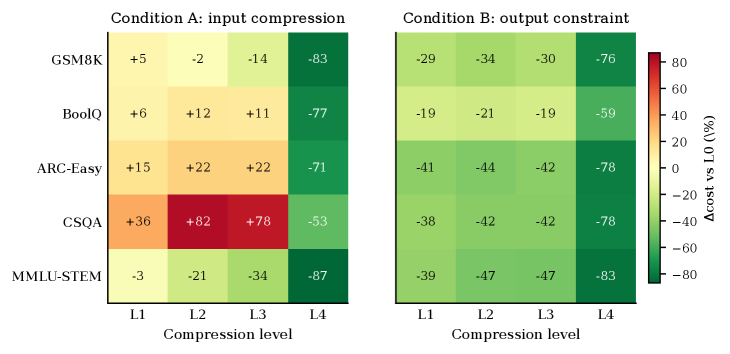
Figure 3 — 입출력 압축에 따른 비용 변화(상대적)
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM의 입출력 압축이 단순히 비용을 줄이는 마법의 도구가 아니라, 채널에 따라 상이한 비용 효과와 의미적 변질을 동반하는 복잡한 과정임을 입증했다. 특히 입력 채널의 압축이 비용 효율적이라는 통념과 달리 실제로는 모델의 응답 확장을 유발하여 경제적 비효율을 초래할 수 있음을 규명하였다. 이 결과는 향후 상용 LLM 서비스 운영 시 추론 비용 최적화를 위한 가이드라인을 제공하며, 모델의 신뢰성 검증에 있어 단순 Accuracy 측정 외에도 생성물의 의미적 일관성을 평가하는 다각적 프레임워크가 필수적임을 시사한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Evolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks
- [논문리뷰] ReFreeKV: Towards Threshold-Free KV Cache Compression
- [논문리뷰] What Intermediate Layers Know: Detecting Jailbreaks from Entropy Dynamics
- [논문리뷰] Improved Large Language Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] Beyond NL2Code: A Structured Survey of Multimodal Code Intelligence
- 현재글 : [논문리뷰] CAVEWOMAN: How Large Language Models Behave Under Linguistic Input and Output Compression
- 다음글 [논문리뷰] Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
댓글