[논문리뷰] Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kaiwen Zheng, Guande He, Min Zhao, Jintao Zhang, Huayu Chen, Huayu Chen, Jianfei Chen, Chen-Hsuan Lin, Ming-Yu Liu, Jun Zhu, Qianli Ma
1. Key Terms & Definitions (핵심 용어 및 정의)
- Teacher-Forcing (TF): Autoregressive 모델 학습 시, 이전 단계의 예측값이 아닌 실제 Ground-truth 데이터를 입력으로 사용하여 학습하는 방식입니다.
- Self-Forcing (SF): 모델이 직접 생성한 샘플을 입력으로 사용하여 학습하는 On-policy 기반 방식이며, 실제 추론 시의 환경과 학습 환경 간의 격차(Training-Inference Gap)를 줄입니다.
- Consistency Models (CMs): Diffusion 모델의 샘플링 속도를 높이기 위해, 시간 $t$에 상관없이 trajectory 상의 모든 점을 초기 점 $x_0$로 매핑하도록 학습하는 Distillation 프레임워크입니다.
- Distribution Matching Distillation (DMD): Student 모델이 생성한 데이터 분포를 Teacher 모델의 분포와 일치시키기 위해 역방향 KL 다이버전스를 최적화하는 기법입니다.
- JVP (Jacobian-Vector Product): Forward-mode 자동 미분을 통해 연속 시간(continuous-time) 모델의 미분값을 효율적으로 계산하는 연산입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Autoregressive(AR) 비디오 확산 모델의 학습 효율성과 추론 품질 간의 불균형을 해결하기 위해 Causal-rCM을 제안한다. 기존의 Teacher-Forcing 방식은 학습 과정에서 에러가 누적되는 현상(Exposure Bias)이 발생하며, Self-Forcing은 학습 초기에 모델이 불안정하여 수렴이 어렵다는 한계가 있다. 이러한 문제들은 Distillation 기법인 CM과 DMD의 상호보완적 관계를 적절히 활용하지 못할 때 더욱 심화된다. 따라서 저자들은 효율적인 Causal 학습과 정밀한 분포 매칭을 결합한 통합적인 방법론의 필요성을 강조한다 [Figure 2].
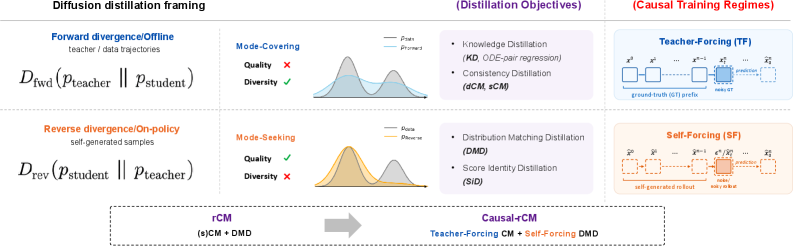
Figure 2 — rCM 및 Causal-rCM의 통합적 관점
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Teacher-Forcing을 통한 안정적인 초기화와 Self-Forcing을 통한 고품질 분포 최적화를 결합한 Causal-rCM 프레임워크를 제안한다. 구체적으로, Teacher-Forcing 기반의 sCM(continuous-time Consistency Model)을 최초로 구현하여 기존의 dCM 대비 10x 빠른 수렴 속도를 달성하였다. 이를 위해 개발된 Custom-mask FlashAttention-2 JVP Kernel은 효율적인 Causal 학습을 가능하게 한다. 제안된 모델은 Wan2.1-1.3B 베이스 모델을 활용하여 단 1~2단계의 샘플링만으로도 우수한 품질의 비디오를 생성한다. 주요 실험 결과, 1-step 생성 설정에서 VBench-T2V 점수 84.63을 기록하며 SOTA 성능을 달성하였다 [Figure 1]. 이러한 수치는 고가의 실데이터 없이 합성 데이터만으로 학습했음에도 불구하고 달성된 결과이다.
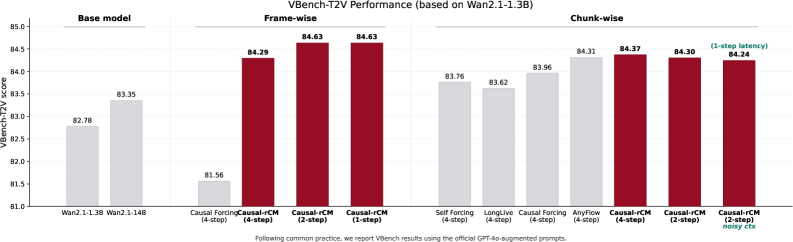
Figure 1 — Streaming 비디오 생성 SOTA 성능
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Autoregressive 비디오 확산 모델을 위한 통합적인 알고리즘 및 인프라 레시피인 Causal-rCM을 성공적으로 제시하였다. 이 연구는 Forward(Teacher-Forcing/CM)와 Reverse(Self-Forcing/DMD) 목적 함수 간의 상호보완성을 체계화하여, 차세대 비디오 생성 및 물리 엔진 기반의 인터랙티브 월드 모델 발전에 기여하였다. 특히, 낮은 지연 시간과 높은 처리량이 요구되는 Streaming 비디오 생성 분야에서 학계와 산업계 모두에 실질적인 레퍼런스를 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AdaState: Self-Evolving Anchors for Streaming Video Generation
- [논문리뷰] Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
- [논문리뷰] Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
- [논문리뷰] Streaming Video Generation with Streaming Force Control
- [논문리뷰] Flash-WAM: Modality-Aware Distillation for World Action Models
Review 의 다른글
- 이전글 [논문리뷰] CAVEWOMAN: How Large Language Models Behave Under Linguistic Input and Output Compression
- 현재글 : [논문리뷰] Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
- 다음글 [논문리뷰] Constraint Tax in Open-Weight LLMs: An Empirical Study of Tool Calling Suppression Under Structured Output Constraints
댓글