[논문리뷰] Look Light, Think Heavy: What Multimodal Chain-of-Thought Reasoning Can and Cannot Do
링크: 논문 PDF로 바로 열기
저자: Zhuoran Jin, Kejian Zhu, Hongbang Yuan, Yupu Hao, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multimodal Chain-of-Thought (CoT): 멀티모달 입력(이미지 및 텍스트)에 대해 단계별 추론 과정을 생성함으로써 모델의 복잡한 문제 해결 능력을 향상시키는 방법론입니다.
- Look Light, Think Heavy: 모델이 추론 과정 중 언어적 반성(Verbal Reflection)은 강화하나, 시각적 정보에 대한 깊은 성찰(Visual Reflection)은 추론이 진행될수록 점차 감소하는 현상을 지칭합니다.
- RLVR (Reinforcement Learning with Verified Rewards): 검증 가능한 보상을 통해 모델의 추론 및 성찰 능력을 최적화하는 학습 방식으로, 최근 추론 모델 개발의 핵심 기법으로 사용됩니다.
- Visual/Textual Reasoning Probes: 모델의 추론 과정 중 시각적 분석 능력과 순수 텍스트 기반 논리 능력을 분리하여 측정하기 위해 설계된 정밀 평가 도구입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Multimodal CoT가 과연 모든 멀티모달 작업에서 일관되게 성능을 향상시키는지, 그리고 그 한계점은 무엇인지를 체계적으로 분석합니다. 최근 텍스트 중심 LLM에서는 CoT가 추론 능력을 극대화하는 표준으로 자리 잡았으나, 이를 멀티모달 영역으로 확장했을 때의 효용성은 여전히 불분명합니다. 특히 기존 연구들이 주로 수학적 추론에 국한되어 평가됨에 따라, 인식(Perception)과 추론(Reasoning)을 아우르는 광범위한 멀티모달 과제에서의 실질적인 효과를 검증할 필요성이 제기됩니다 [Figure 1].
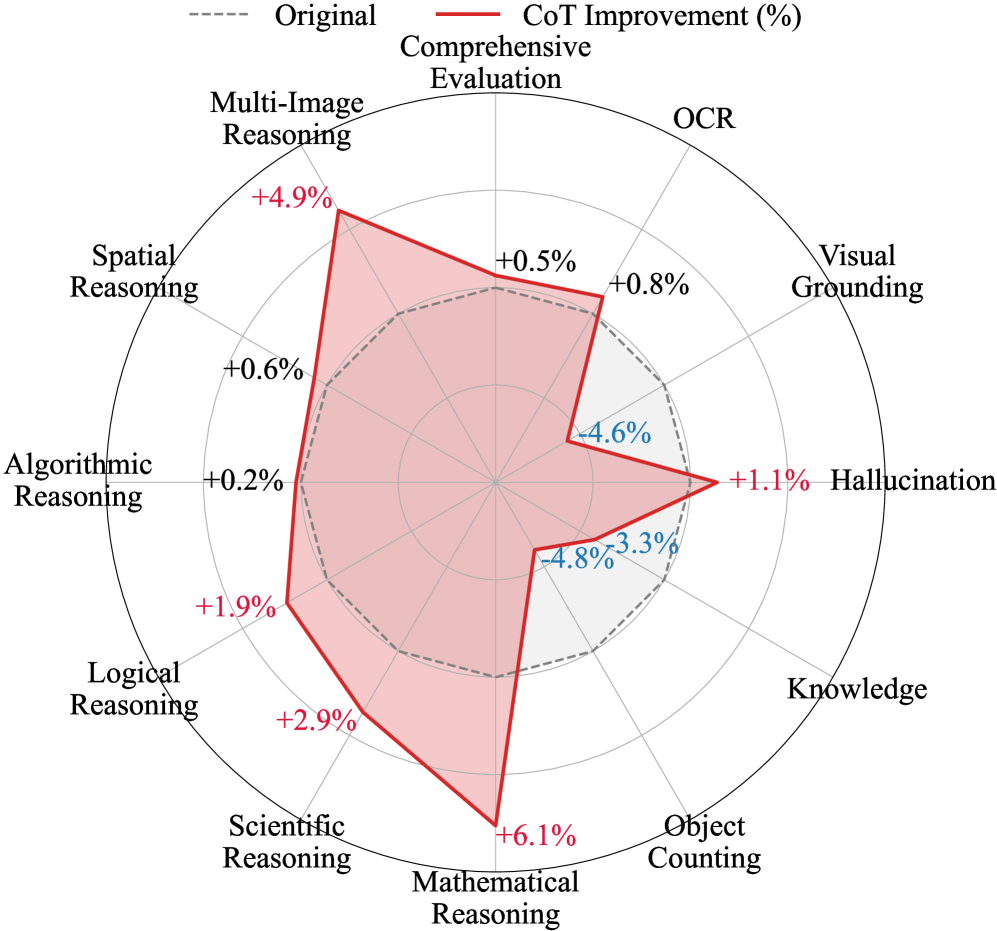
Figure 1 — Multimodal CoT의 주요 발견 사항
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 14개의 비추론 모델과 8개의 추론 모델을 활용하여 12개의 멀티모달 작업을 인식과 추론 범주로 나누어 평가하였습니다. 연구 결과, CoT는 모든 작업에서 유효한 'Free lunch'가 아니며, Visual Grounding이나 Object Counting 같은 인식 작업에서는 오히려 성능 저하를 초래할 수 있음을 확인하였습니다 [Figure 2]. 반면, 수학적/과학적 추론 작업에서는 유의미한 성능 향상을 보였으며, 논리 및 알고리즘 추론에서는 모델 규모에 따라 효용성이 달라짐을 입증하였습니다. 특히, 기존 오픈소스 멀티모달 추론 모델들은 RLVR 학습 과정에서 수학적 능력에 과도하게 편향되어 일반적인 멀티모달 추론 능력의 향상이 미미하다는 사실을 밝혀냈습니다 [Figure 3]. 모델 내적 메커니즘 분석 결과, 추론 과정에서 시각적 정보 처리 능력은 모델의 전체 성능과 강한 상관관계를 보이며, 시각적 정보 처리가 현재 Multimodal CoT의 핵심적인 Bottleneck임이 확인되었습니다 [Figure 6].
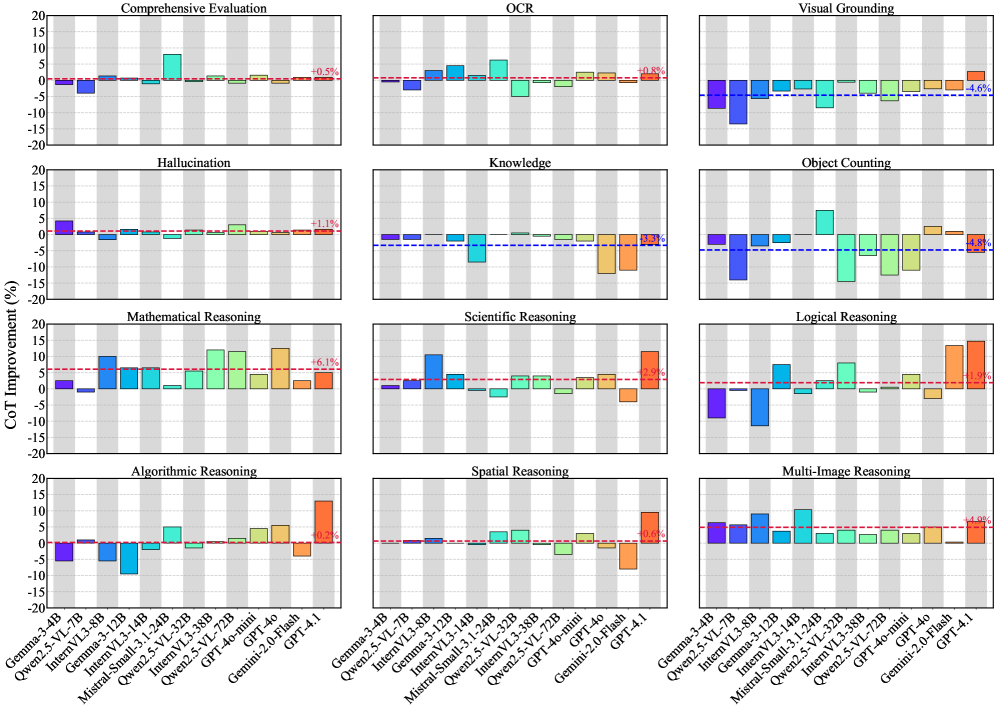
Figure 2 — Direct Answer와 CoT 성능 비교
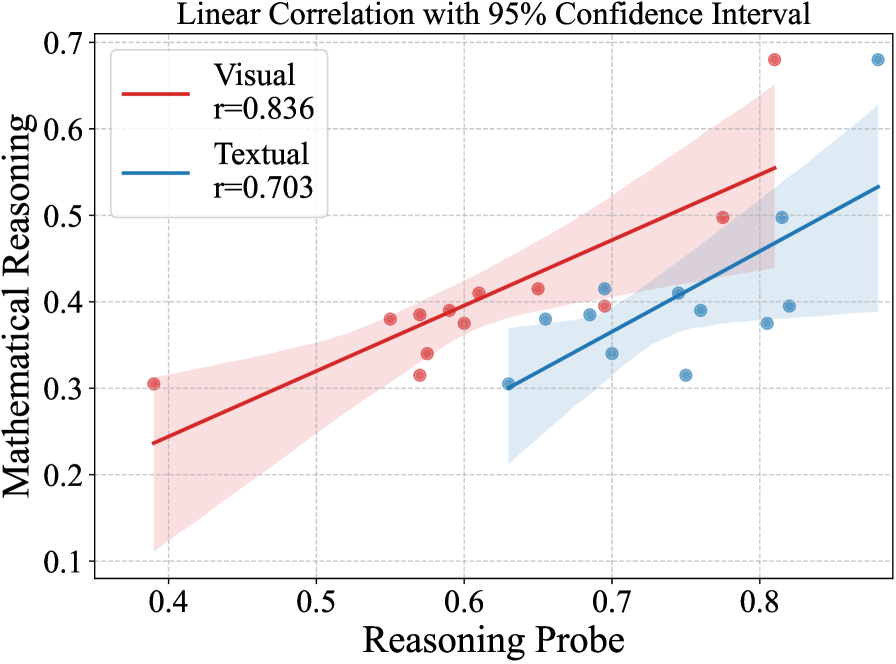
Figure 6 — 시각적/텍스트적 추론 Probe와 전체 성능 상관관계
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Multimodal CoT가 'Look Light, Think Heavy'라는 고유한 한계를 지니고 있음을 규명하며, 현재의 모델들이 시각적 정보에 대한 깊은 내성(Visual Introspection)이 부족함을 지적합니다. 이러한 결과는 향후 MLLM이 단순히 긴 추론 과정을 생성하는 것을 넘어, 시각적 정보를 지속적으로 재확인하고 외부 도구를 적절히 활용하는 방향으로 진화해야 함을 시사합니다. 이는 멀티모달 추론 모델의 학습 패러다임이 보다 범용적이고 시각적으로 견고한 방향으로 전환되는 데 중요한 학술적 근거를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Evaluation-driven Scaling for Scientific Discovery
- [논문리뷰] Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning
- [논문리뷰] EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
- [논문리뷰] Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
Review 의 다른글
- 이전글 [논문리뷰] Improved Large Language Diffusion Models
- 현재글 : [논문리뷰] Look Light, Think Heavy: What Multimodal Chain-of-Thought Reasoning Can and Cannot Do
- 다음글 [논문리뷰] MVTrack4Gen: Multi-View Point Tracking as Geometric Supervision for 4D Video Generation
댓글