[논문리뷰] AsyncOPD: How Stale Can On-Policy Distillation Be?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wonjun Kang, Kevin Galim, Seunghyuk Oh, Minjun Kang, Sanghyun Park, Donghoon Kim, Minjae Lee, Minseo Kim, Rishabh Tiwari, Yuchen Zeng, Hyung Il Koo, Kangwook Lee
1. Key Terms & Definitions (핵심 용어 및 정의)
- On-policy Distillation (OPD): 학생 모델이 자신의 rollout을 통해 학습하며, 교사(Teacher) 모델로부터 토큰 단위의 피드백을 받아 지식을 증류하는 LLM 사후 학습 기법.
- Staleness: 비동기식 학습 파이프라인에서 rollout 생성 시점과 학습 업데이트 시점 간의 정책 차이로 인해 발생하는 데이터 지연 현상.
- Forward-KL/Reverse-KL: OPD의 학습 목적함수로, Forward KL은 교사 가중치(Teacher-weighted)를, Reverse KL은 학생 가중치(Student-weighted)를 사용하는 Divergence 측정 방식.
- Multi-sample MC (Monte Carlo): 비동기 학습 환경에서 발생하는 분산 문제를 해결하기 위해, 여러 개의 샘플을 캐싱하여 평균을 내고 Importance Sampling으로 보정하는 기법.
- AsyncOPD: rollout 생성, 교사 점수 산출, 학생 업데이트를 비동기적으로 병렬 처리하여 학습 효율을 극대화하는 프레임워크.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 사후 학습에서 OPD가 겪는 On-policy systems bottleneck 문제를 해결하기 위해 비동기식 학습 파이프라인의 도입 필요성을 제기한다. 기존의 동기식 학습은 rollout 생성이 완료될 때까지 학습기를 대기시켜 하드웨어 활용률을 저하시킨다. 비동기식 학습은 이를 해결할 수 있으나, rollout 과정에서 사용된 정책이 최신 정책과 일치하지 않는 Staleness 문제가 발생하여 학습 품질을 저하시킨다. 특히 OPD 환경에서는 교사 피드백을 위한 전체 어휘 사전 Logits를 저장하거나 전송하는 것이 비용 면에서 불가능하여, 유한한 Teacher-score cache를 사용해야 하는 제약이 존재한다. 저자들은 이 Teacher-cache constraint 하에서 발생하는 Staleness가 학습 성능에 미치는 영향을 체계적으로 분석한다 [Figure 1].
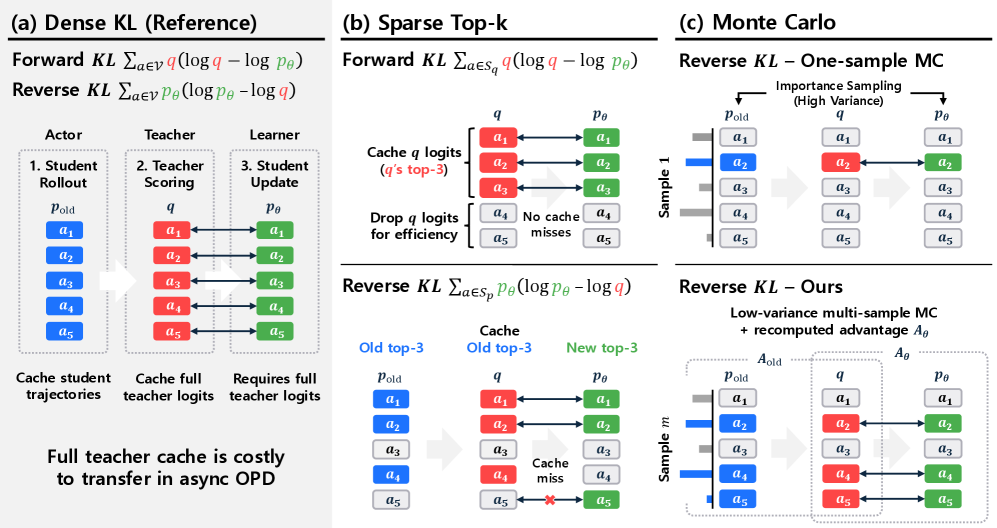
Figure 1 — 비동기 OPD의 estimator 설계
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 KL 방향성에 따른 Staleness 영향력을 분석하고, Reverse-KL의 성능을 개선하기 위한 최적의 학습 전략을 제안한다. 저자들은 Forward-KL이 교사 가중치 방식 덕분에 Staleness에 상대적으로 강건한 반면, Reverse-KL은 학생 가중치로 인해 지연 데이터에 훨씬 취약함을 실험적으로 입증한다 [Figure 2]. 취약한 Reverse-KL 문제를 해결하기 위해, 저자들은 기존의 복잡한 비동기 RL 방식들(예: Decoupled PPO, M2PO)보다 훨씬 효과적인 단순 surrogate 전략을 제시한다. 구체적으로, 학습 시점에 현재 학생 모델을 사용하여 Reverse-KL의 이점(advantage) 항을 재계산하고, Clipping 없이 학습하는 것이 가장 안정적인 성능을 보였다 [Figure 3]. 또한, 유한한 캐시로 인해 발생하는 편향(Bias)과 분산(Variance) 문제를 해결하기 위해 Multi-sample MC를 제안하여, 1-sample 방식의 높은 분산 문제를 성공적으로 완화하였다 [Table 1]. 결과적으로 제안된 AsyncOPD는 순수 동기식 학습 대비 학습 처리량(Throughput)을 **1.6×**에서 최대 **3.8×**까지 향상시키면서도 동등 수준의 정확도를 유지하는 결과를 보였다.
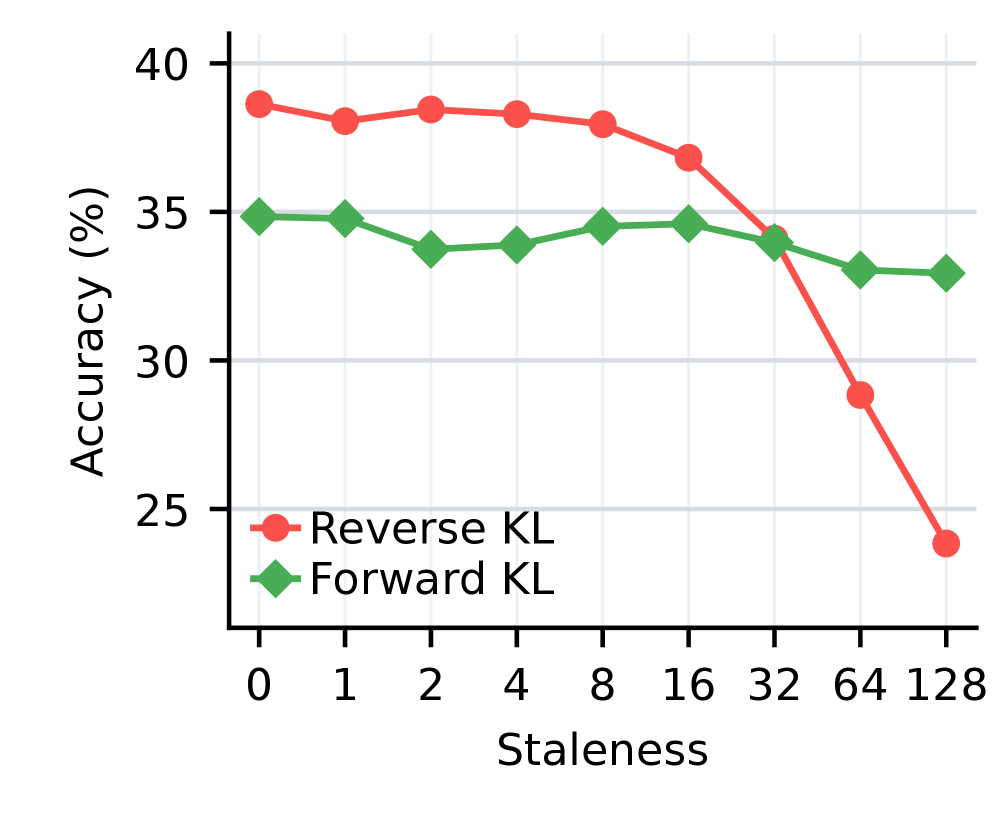
Figure 2 — KL 방향성에 따른 정확도 비교
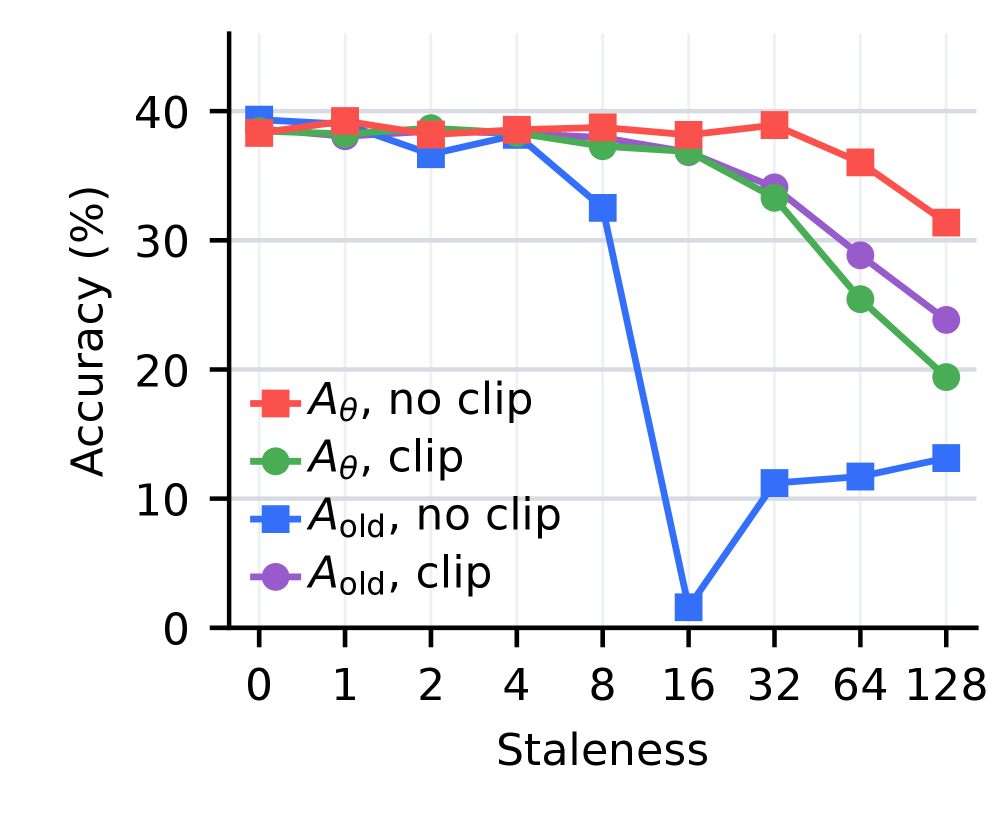
Figure 3 — Surrogate ablation 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 OPD 분야에서 비동기식 학습 시 발생하는 Staleness 문제를 최초로 체계적으로 분석하여 최적의 estimator 디자인과 surrogate 전략을 정의하였다. 특히 Reverse-KL 환경에서의 핵심은 Clipping 없는 advantage 재계산과 Multi-sample MC의 활용임을 증명하였다. 이 결과는 효율적인 대규모 LLM 사후 학습 시스템을 구축하고자 하는 산업계와 학계 모두에게 중요한 실무적 가이드라인을 제공한다. 공개된 AsyncOPD 프레임워크는 실제 리소스 제약이 큰 환경에서 학습 효율성을 높이는 표준적인 도구로 활용될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] Agentic Abstention: Do Agents Know When to Stop Instead of Act?
- 현재글 : [논문리뷰] AsyncOPD: How Stale Can On-Policy Distillation Be?
- 다음글 [논문리뷰] Beyond Drug Discovery: The Nanotechnology Molecular Optimization (NMO) Benchmark
댓글