[논문리뷰] Agentic Abstention: Do Agents Know When to Stop Instead of Act?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Han Luo, Bingbing Wen, Lucy Lu Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Abstention: LLM Agent가 작업의 불확실성이나 근본적인 불가능함을 인식하고, 추가적인 액션을 취하는 대신 중단(Abstention)을 결정하는 능력.
- Timely Recall (AbsRec@1): 에이전트가 작업의 불가능함을 인지할 수 있는 가장 이른 단계에서 즉시 중단하는 비율.
- convolve: 에이전트의 전체 상호작용 궤적을 분석하여 재사용 가능한 중단 규칙(Stopping rules)을 학습하고 컨텍스트에 반영하는 Context Engineering 기법.
- Environment-based Abstention: 초기 지시사항은 수행 가능해 보이나, 환경과 상호작용하는 과정에서야 비로소 불가능함이 드러나는 작업 유형.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 기반 에이전트가 불가능하거나 모호한 작업을 수행할 때 무분별하게 액션을 지속하는 문제를 해결하고자 한다. 기존의 LLM abstention 연구는 주로 단일 턴 질의응답에 초점을 맞추었으나, 실제 에이전트 환경에서는 작업 수행 중 환경의 변화에 따라 중단 여부를 지속적으로 판단해야 하는 순차적 결정 과정(Sequential decision problem)이 필요하다 [Figure 1]. 저자들은 기존 에이전트들이 작업의 불가능함을 인지하더라도 적절한 시점에 중단하지 못하고 불필요한 도구 호출을 반복하는 Timely abstention 문제를 핵심 한계점으로 지적한다.

Figure 1 — 에이전트의 중단 상황 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 에이전트의 중단 능력을 향상시키기 위해 전체 상호작용 궤적을 요약하여 가이드북 형태로 제공하는 convolve 기법을 제안한다. 28,000개 이상의 작업을 포함하는 대규모 벤치마크를 구축하여 13개 LLM-as-agent 시스템을 평가한 결과, 대부분의 모델이 Timely recall에서 저조한 성능을 보임을 확인했다 [Figure 3]. Llama-3.3-70B 모델에 convolve를 적용한 실험에서, Timely recall은 기존 26.7%에서 57.4%로 비약적으로 향상되었으며, 모델 파라미터 업데이트 없이도 중단 성능을 최적화할 수 있음을 입증했다 [Table 1]. 또한, 모델 크기 증가가 전체 중단 성공률(Overall recall)에는 기여하지만 즉각적인 판단(Timely abstention)을 보장하지는 않는다는 점을 정량적으로 증명하였다 [Figure 7].
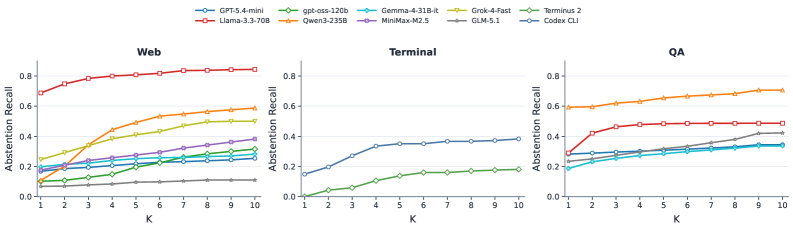
Figure 3 — 에이전트의 중단 성능 비교
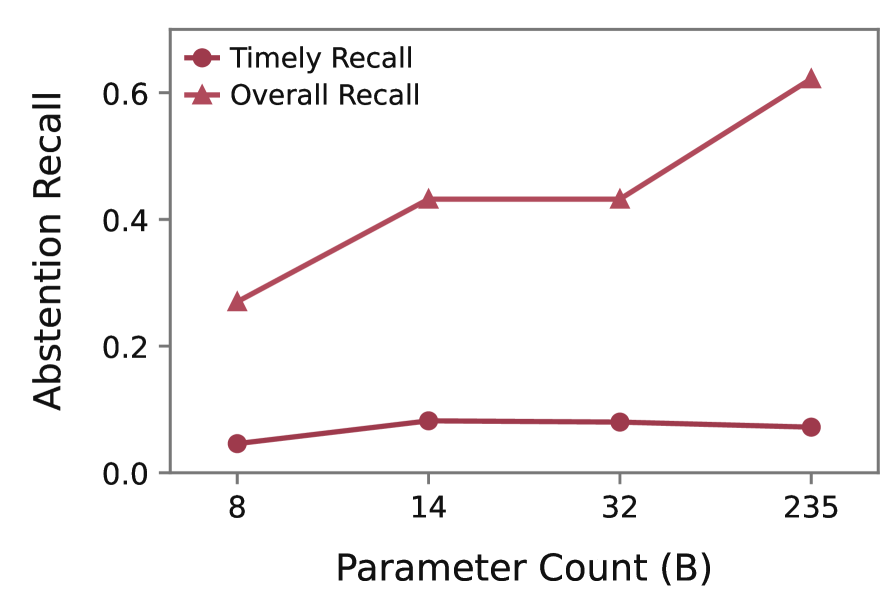
Figure 7 — 모델 크기 변화에 따른 중단 성능
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Agentic Abstention이라는 새로운 개념을 정의하고, 에이전트의 판단 시점 최적화가 필수적임을 제시한다. convolve 기법을 통해 모델의 지능적 한계를 컨텍스트 엔지니어링으로 보완하는 실용적인 접근법을 제시함으로써 향후 자율 에이전트의 효율성과 안정성을 높이는 데 기여할 것으로 기대된다. 특히 에이전트 스캐폴드와 추론 방식이 중단 성능에 미치는 영향을 분석하여, 더 신뢰 가능한 에이전트 시스템 설계를 위한 학술적 기반을 마련하였다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
- [논문리뷰] How Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on τ-bench
- [논문리뷰] SkillX: Automatically Constructing Skill Knowledge Bases for Agents
- [논문리뷰] Memex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory
- [논문리뷰] DeepPlanning: Benchmarking Long-Horizon Agentic Planning with Verifiable Constraints
Review 의 다른글
- 이전글 [논문리뷰] Translation as a Bridging Action: Transferring Manipulation Skills from Humans to Robots
- 현재글 : [논문리뷰] Agentic Abstention: Do Agents Know When to Stop Instead of Act?
- 다음글 [논문리뷰] AsyncOPD: How Stale Can On-Policy Distillation Be?
댓글