[논문리뷰] Video-MME-Logical: A Controlled Diagnostic Benchmark for Video Temporal-Logical Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hohin Kwan, Hongyu Li, Ray Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Video Temporal-Logical Reasoning: 단순히 개별 프레임의 객체를 인식하는 수준을 넘어, 시간이 흐름에 따라 변화하는 시각적 상태를 유지(maintain), 업데이트(update), 그리고 합성(compose)하여 논리적 추론을 수행하는 능력.
- Video-MME-Logical: 저자들이 제안하는 5개의 Temporal-Logical Operation과 25개의 세분화된 태스크로 구성된 통제된(controlled) 진단용 벤치마크.
- Intermediate-State Diagnostic: 최종 결과뿐만 아니라, 추론 과정의 중간 단계(예: 상태 변화 추적)를 검증하여 모델이 올바른 논리적 흔적(trace)을 따라갔는지 확인하는 평가 방식.
- Programmatic Generation: 합성 데이터를 사용하여 객체 상태, 전이, 시간적 의존성 및 논리적 복잡성을 프로그래밍 방식으로 제어하여 생성하는 파이프라인.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재의 MLLMs가 비디오 내의 동적인 시각적 증거를 바탕으로 논리적 추론을 수행하는 데 있어 심각한 한계를 가지고 있음을 지적한다. 기존의 비디오 이해 벤치마크들은 대부분 일반적인 비디오 이해(General Video Understanding)에 초점을 맞추고 있어, 복잡한 시간적 의존성과 논리적 복잡성을 명확히 분리하여 평가하지 못한다는 문제점이 있다. 또한, 대부분의 벤치마크는 최종 답변(Final-Answer)만을 평가할 뿐, 모델이 실제로 올바른 추론 과정을 거쳤는지 확인할 수 있는 중간 상태 검증을 제공하지 않는다 [Table 1]. 이러한 데이터의 비통제성과 평가 방식의 한계로 인해, 현재 모델들의 실제 논리적 추론 능력이 과대평가되고 있다는 것이 저자들의 핵심 진단이다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Temporal-Logical Reasoning 능력을 5가지 핵심 operation(State Tracking, Sequential Counting, Temporal Ordering, Dynamic Spatiality, Structural Composition)으로 분류하고, 이를 25개의 태스크로 구현하여 평가하는 프레임워크를 제안한다 [Figure 2]. 저자들은 각 태스크의 어려움(difficulty)을 시간적 지평(temporal horizon)과 추론 복잡성으로 정밀하게 제어하였으며, 특히 8개의 태스크에 대해서는 중간 과정의 추론 단계를 검증할 수 있는 진단용 서브셋인 Video-MME-Logical-S를 도입하였다 [Figure 3]. 주요 실험 결과, 인간의 성과(95.9% 정확도)와 최신 MLLMs(최고 성능인 Gemini-3.1 Pro가 28.6% 기록) 사이에는 상당한 성능 격차(human-model gap)가 존재함이 확인되었다 [Table 2]. 중간 상태 진단 평가 결과, 최종 답변은 맞더라도 추론 과정이 잘못된 경우가 빈번하게 나타나며, GPT-5.4와 Gemini-3.1 Pro가 중간 단계 추론에서 상대적으로 우수한 성과를 보였으나, 오픈소스 모델들과는 큰 격차를 보였다 [Table 3]. 마지막으로, 500K 규모의 생성 데이터를 사용한 SFT(Supervised Fine-Tuning) 실험 결과, 데이터 규모 증가가 성능 향상을 이끌어내지만 375K 이후에는 포화 상태에 이르며, 여전히 복잡한 논리적 구조를 해결하기에는 부족함을 보여주었다 [Table 4].
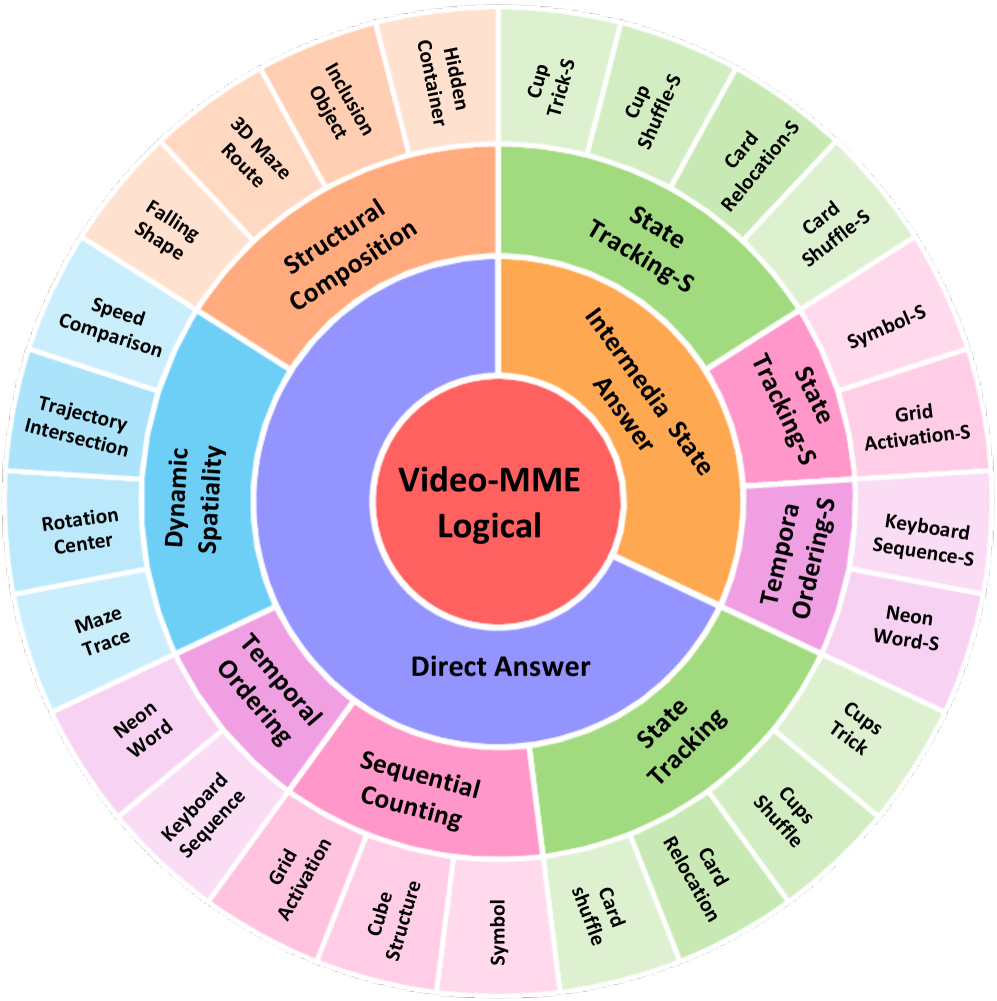
Figure 2 — 벤치마크의 태스크 분류 체계
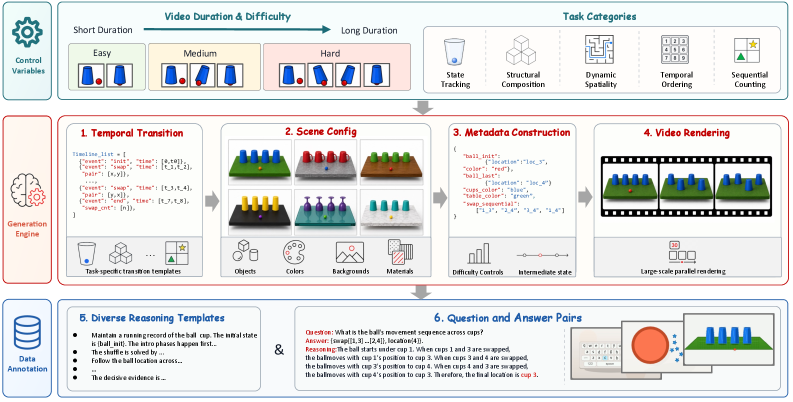
Figure 3 — 25개 태스크의 구조적 설계
4. Conclusion & Impact (결론 및 시사점)
본 논문은 비디오 시간-논리적 추론 능력을 체계적으로 진단하기 위한 Video-MME-Logical 벤치마크를 성공적으로 구축하고 그 타당성을 입증하였다. 연구 결과는 단순한 데이터 스케일링이나 일반적인 모델 학습만으로는 고도화된 시간적 논리 추론 능력을 확보하는 데 한계가 있음을 시사한다. 이 연구가 제공하는 통제된 평가 환경과 중간 상태 진단 도구는 향후 더 나은 비디오 추론 모델을 개발하고, 모델의 실패 원인을 정밀하게 분석하는 데 중요한 가이드라인이 될 것으로 기대된다.

Figure 4 — 중간 상태 평가 예시
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Current World Models Lack a Persistent State Core
- [논문리뷰] X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
- [논문리뷰] LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
- [논문리뷰] CurveStream: Boosting Streaming Video Understanding in MLLMs via Curvature-Aware Hierarchical Visual Memory Management
- [논문리뷰] TextPecker: Rewarding Structural Anomaly Quantification for Enhancing Visual Text Rendering
Review 의 다른글
- 이전글 [논문리뷰] Trimming the Long-Tail of Visual World Modeling Evaluation
- 현재글 : [논문리뷰] Video-MME-Logical: A Controlled Diagnostic Benchmark for Video Temporal-Logical Reasoning
- 다음글 [논문리뷰] Walking in the Implicit: Interactive World Exploration via Neural Scene Representation
댓글