[논문리뷰] Walking in the Implicit: Interactive World Exploration via Neural Scene Representation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhiqi Li, Chengrui Dong, Zhenhua Du, Hangning Zhou, Cong Qiu, Hailong Qin, Mu Yang, Dongxu Wei, Peidong Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Neural Implicit Scene (NIS): 고정된 길이의 latent token set으로, 특정 장면의 기하학적 구조와 외형 정보를 보존하며 카메라 포즈에 따른 렌더링이 가능한 핵심적인 장면 상태(scene state) 변수입니다.
- NIS-VAE: transformer 기반의 VAE 구조로, 입력된 포즈가 주어진 이미지를 NIS 토큰으로 인코딩하거나, 샘플링된 NIS로부터 대상 포즈의 뷰를 렌더링하는 역할을 합니다.
- NIS-DiT: set-based diffusion transformer로, 이전의 NIS 상태와 카메라 궤적, 히스토리 정보를 조건으로 입력받아 다음 단계의 local NIS 상태를 샘플링하는 동적 모델입니다.
- Unified Conditioner: NIS-VAE 인코더를 재사용하여 카메라 궤적, 참조 이미지, 검색된 히스토리 등 이질적인 정보들을 동일한 NIS modality로 매핑하여 NIS-DiT에 입력하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 카메라 제어 기반 상호작용 세계 모델(Interactive World Model)들이 겪는 장기적인 일관성 유지 문제를 해결하고자 합니다. 기존 방식은 관측값(frame latents)을 직접 생성하는 방식을 취하는데, 이는 상태 전이와 고해상도 이미지 합성이 얽혀 있어 rollout이 길어질수록 일관성이 급격히 저하됩니다 [Figure 1]. 이러한 엔터글먼트(entanglement) 문제는 매끄러운 카메라 이동과 반복 방문 시의 일관된 장면 재구성을 어렵게 만듭니다. 저자들은 상태 전이를 명시적인 3D 구조 재건보다 가볍고, 프레임 latent보다는 구조적인 'renderable scene state'로 전환하는 새로운 접근 방식을 제안합니다.
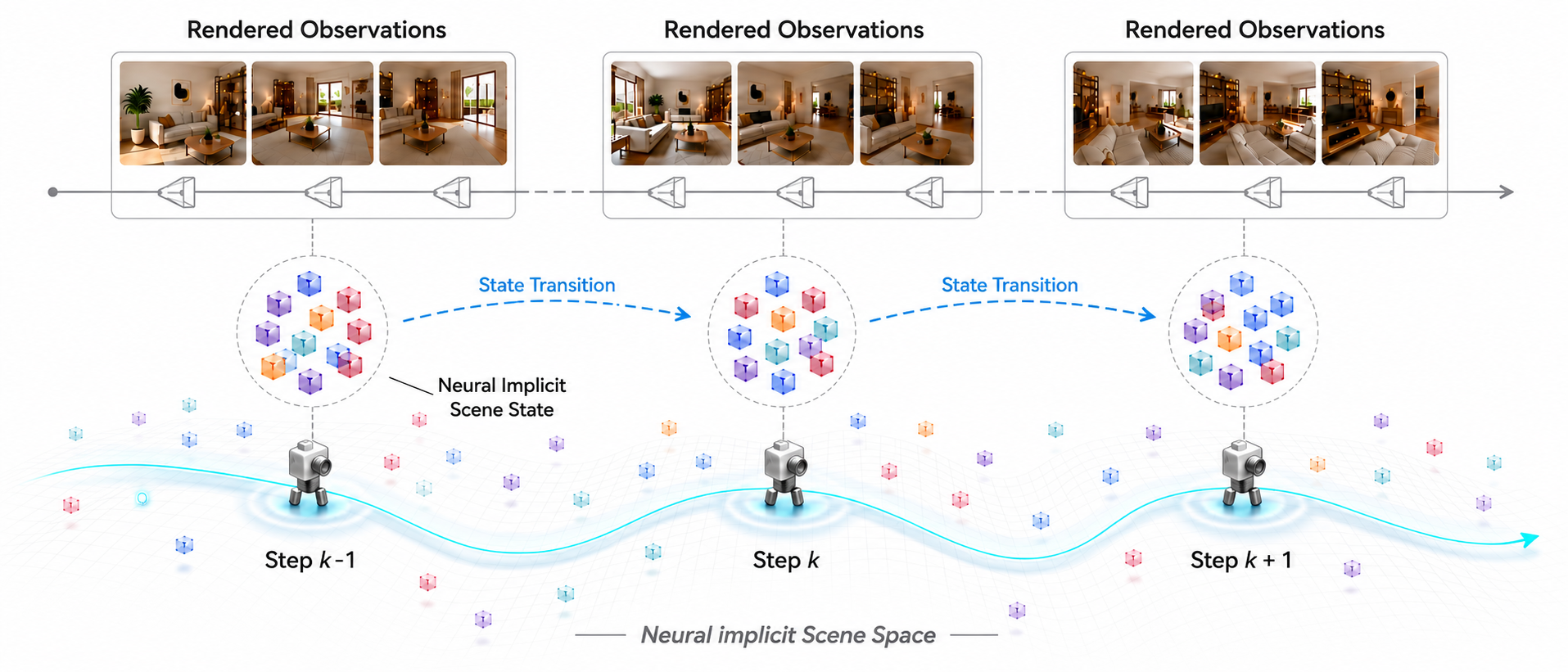
Figure 1 — NeuWorld의 핵심 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 상호작용 과정을 NIS 상태 전이와 pose-conditioned 렌더링으로 분리하는 Walking in the Implicit 패러다임을 제안합니다 [Figure 2]. 먼저 NIS-VAE를 통해 Sparse한 관측 데이터를 고정된 길이의 NIS 토큰으로 변환하고, 이를 기반으로 NIS-DiT가 다음 장면 상태를 확률적으로 샘플링하도록 설계되었습니다 [Figure 2]. 또한, 기하학적 정보를 반영한 메모리 검색(Geometry-aware retrieval)을 통해 장기 rollout 시의 드리프트(drift)를 방지하며, anti-drift condition augmentation을 통해 학습과 추론 시의 히스토리 품질 차이를 보정합니다. 실험 결과, NeuWorld는 Pretrained 비디오 백본이나 외부 3D 재건 모델 없이 공개 데이터셋(Re10K, DL3DV)에서 학습되었음에도 우수한 성능을 보였습니다. Re10K 데이터셋의 200번째 프레임 기준, 기존 베이스라인 대비 현저히 낮은 수준의 회전 오차(Rdist=0.083)와 이동 오차(Tdist=0.141)를 기록하며 강력한 장기 일관성을 입증했습니다 [Table 1]. 또한, 추론 효율성 측면에서도 렌더링 단계와 전이 단계를 효율적으로 분리하여 실시간 탐색 환경에 최적화된 성능을 제공합니다.
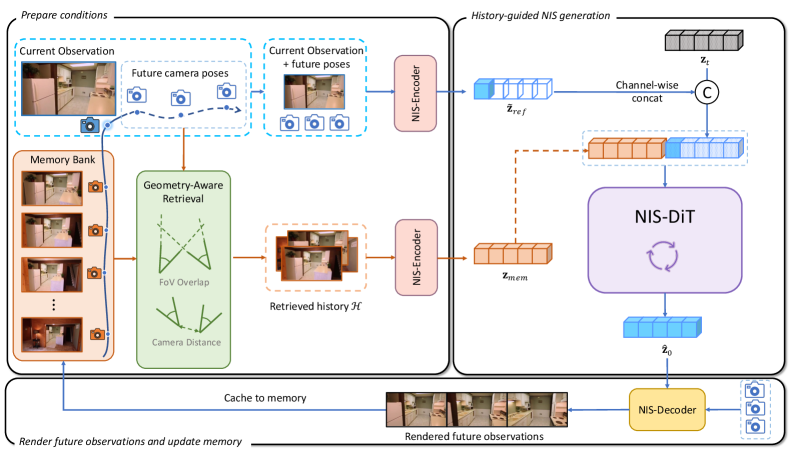
Figure 2 — 제안 방법론 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고정 길이의 implicit scene representation을 rollout 변수로 활용함으로써 상호작용 비디오 생성 분야의 장기 일관성 문제를 효과적으로 해결하였습니다. NeuWorld는 복잡한 외부 재건 기법 없이도 학습된 compact scene state만으로 일관된 시각적 탐색을 지원하며, 이는 향후 로봇 공학이나 가상 시뮬레이터와 같은 인터랙티브 시스템의 기반 모델로서 큰 잠재력을 가집니다. 본 연구는 장면 표현과 생성 모델을 결합한 새로운 패러다임이 카메라 제어 세계 모델의 효율성과 안정성을 동시에 개선할 수 있음을 실증적으로 보여주었습니다.
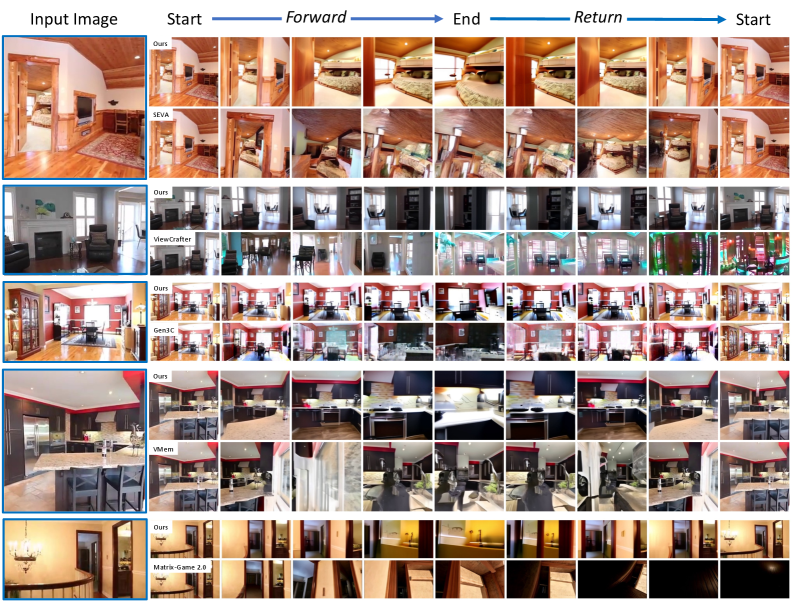
Figure 3 — 정성적 비교 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive
- [논문리뷰] MemLearner: Learning to Query Context memory for Video World Models
- [논문리뷰] PhysiFormer: Learning to Simulate Mechanics in World Space
- [논문리뷰] UnityShots: Memory-Driven Multi-Shot Audio-Video Generation with Boundary-Aware Gating
- [논문리뷰] TryOnCrafter: Unleashing Camera Trajectories for Realistic Video Virtual Try-on via a Renderable 4D Try-on Proxy
Review 의 다른글
- 이전글 [논문리뷰] Video-MME-Logical: A Controlled Diagnostic Benchmark for Video Temporal-Logical Reasoning
- 현재글 : [논문리뷰] Walking in the Implicit: Interactive World Exploration via Neural Scene Representation
- 다음글 [논문리뷰] ZooClaw-FashionSigLIP2: Distilled Fine-tuning for Robust Fashion Retrieval
댓글