[논문리뷰] OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
링크: 논문 PDF로 바로 열기
저자: Yaofeng Su, Yuming Li, Zeyue Xue, Jie Huang, Siming Fu, Haoran Li, Ying Li, Zezhong Qian, Haoyang Huang, Nan Duan
1. Key Terms & Definitions (핵심 용어 및 정의)
- OmniForcing : 오프라인의 양방향 Joint Audio-Visual Diffusion Model을 고품질 스트리밍 Autoregressive Generator로 Distill하는 프레임워크입니다.
- Time-To-First-Chunk (TTFC) : 첫 번째 데이터 Chunk를 생성하고 디코딩하는 데 걸리는 Wall-clock 시간을 측정하는 Latency 지표입니다.
- Asymmetric Block-Causal Alignment : Audio와 Video 모달리티 간의 심각한 Temporal Asymmetry를 해결하기 위해 고안된 마스킹 전략입니다.
- Audio Sink Tokens with Identity RoPE : Sparse한 Causal Audio Attention으로 인한 Gradient Explosion과 Softmax Collapse를 완화하기 위해 도입된 Position-agnostic Global Memory Buffer입니다.
- Joint Self-Forcing Distillation : Long Rollout 중에 Cross-modal Error Accumulation으로 인해 증폭되는 Exposure Bias를 동적으로 자가 수정하기 위한 Distillation 패러다임입니다.
- Modality-Independent Rolling KV-Cache : Per-step Context Complexity를 O(L)로 줄이고 두 모달리티 스트림의 동시 실행을 가능하게 하는 추론(Inference) Scheme입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 LTX-2 와 Veo 3 와 같은 Joint Audio-Visual Diffusion Model들은 탁월한 Generation Quality를 보여주지만, Bidirectional Attention Dependency로 인해 높은 Latency를 겪어 Real-time Application에 적용하기 어렵습니다. 기존 연구들은 주로 Video를 먼저 생성하고 Audio를 합성하는 Cascaded Pipeline을 사용하거나, Video-only Diffusion Model을 Causal Autoregressive Framework로 Adapt하는 방식이었습니다. 그러나 이러한 방식들은 Joint Distribution을 손상시키거나, 모달리티 간의 심각한 Temporal Asymmetry로 인해 Dual-stream 아키텍처로의 확장이 비현실적입니다. 특히, Audio Stream의 극심한 Token Sparsity는 Training Instability, Softmax Collapse, 그리고 Gradient Explosion을 유발합니다. 저자들은 이러한 Latency Bottleneck과 Training Instability 문제를 해결하고, 오프라인 모델의 High-fidelity를 유지하면서 Real-time Streaming Generation을 가능하게 하는 새로운 프레임워크의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Bidirectional Joint Audio-Visual Diffusion Model을 High-fidelity Streaming Autoregressive Generator로 Distill하는 최초의 프레임워크인 OmniForcing 을 제안합니다. 이 방법론은 세 단계의 Distillation Pipeline을 통해 이루어집니다
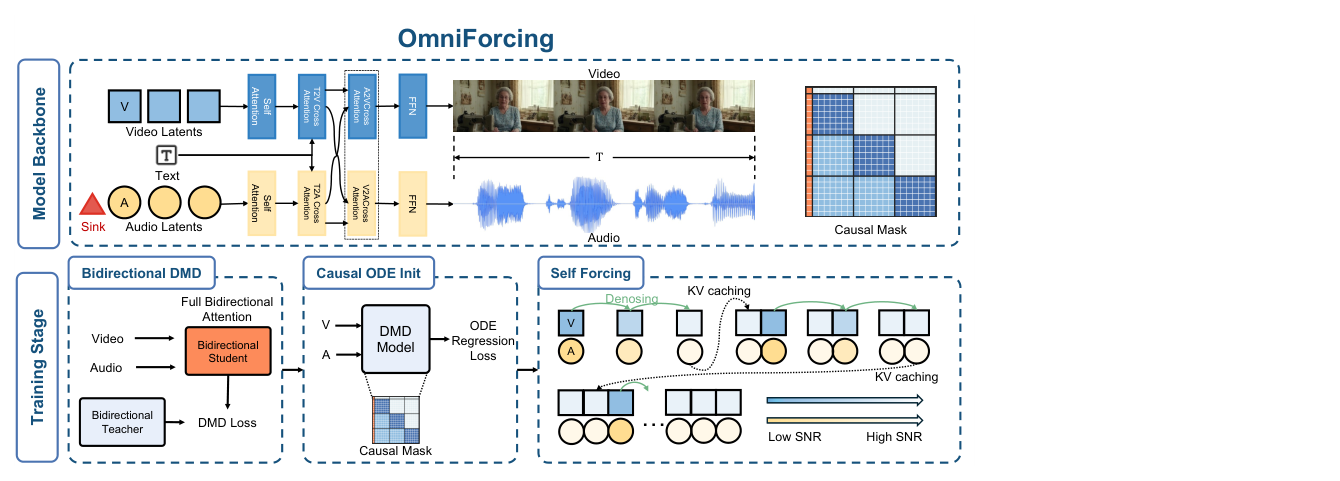 Figure 2: The three-stage OmniForcing distillation pipeline.
Figure 2: The three-stage OmniForcing distillation pipeline.
. 첫째, Stage I 에서는 Distribution Matching Distillation (DMD) 를 통해 사전 훈련된 모델을 Few-step Fast Denoising이 가능한 Bidirectional Student Model로 Distill합니다. 둘째, Stage II 에서는 Causal ODE Regression 을 사용하여 네트워크 Weights를 Asymmetric Block-Causal Mask에 Adapt합니다
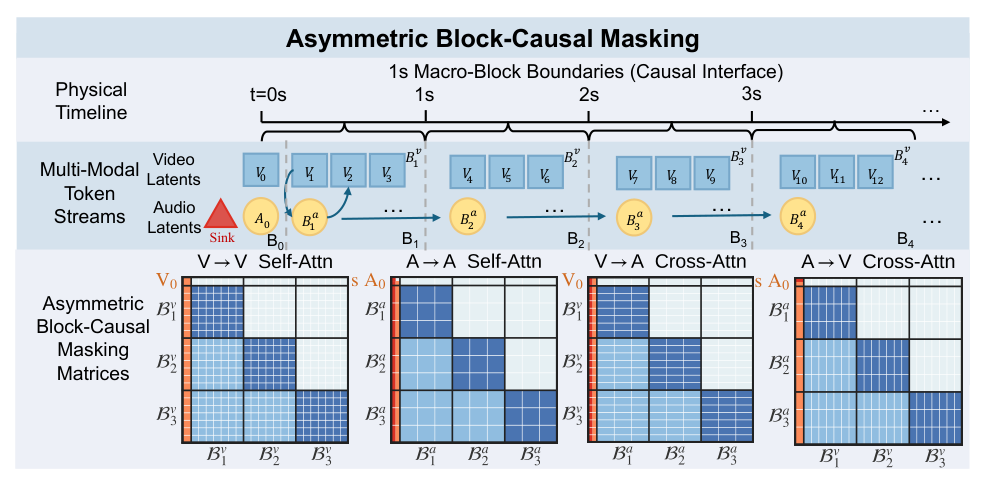 Figure 3: Asymmetric Block-Causal Masking.
Figure 3: Asymmetric Block-Causal Masking.
. 이 과정에서 Zero-truncation Global Prefix 를 도입하여 Temporal Origin에 Cross-modal Anchor를 설정하고, Audio Sink Token mechanism with Identity RoPE 를 통해 Audio Stream의 극심한 Token Sparsity로 인한 Softmax Collapse 및 Gradient Explosion 문제를 해결합니다. Identity RoPE 는 이 Sink Token들이 Positional Bias를 가지지 않도록 보장합니다. Ablation Study 결과, S ≥ 4 개의 Audio Sink Tokens 와 Identity RoPE 를 사용했을 때 NaN Gradient 없이 안정적인 Convergence를 달성함을 확인했습니다 [Table 3]. 셋째, Stage III 에서는 Joint Self-Forcing Distillation 패러다임을 적용하여 Long Rollout 동안 발생하는 Exposure Bias와 Cross-modal Synchronization Drift를 완화합니다. 추론 단계에서는 Modality-Independent Rolling KV-Cache 를 활용하여 Per-step Context Complexity를 O(L) 로 줄이고, ~25 FPS 의 Real-time Streaming Generation을 단일 GPU에서 가능하게 합니다. 핵심 결과로, OmniForcing 은 5초 길이의 480p Audio-visual Clip 을 ~5.7s 만에 생성하며, ~0.7s 의 낮은 TTFC 를 달성합니다 [Figure 1]. 이는 오프라인 LTX-2 Teacher 모델 대비 ~35x 의 속도 향상입니다
![Table 1: Main results on JavisBench [23].](/paper-images/2026-03-16/2603.11647/table_1.png) Table 1: Main results on JavisBench [23].
Table 1: Main results on JavisBench [23].
. JavisBench 평가에서 FVD 137.2 , FAD 5.7 을 기록하며 Teacher Model과 비견할 만한 Audio-Visual Quality를 유지했고, Text-consistency에서 CLIP Score 0.322 로 모든 Baseline 중 최고 성능을 달성했습니다 [Table 1].
4. Conclusion & Impact (결론 및 시사점)
이 연구는 오프라인의 Bidirectional Joint Audio-Visual Diffusion Model을 Real-time Streaming Autoregressive Generator로 성공적으로 Distill하는 최초의 프레임워크인 OmniForcing 을 제시했습니다. 제안된 Asymmetric Block-Causal Alignment , Audio Sink Tokens with Identity RoPE , Joint Self-Forcing Distillation , 그리고 Modality-Independent Rolling KV-Cache 는 Multi-modal Distillation의 본질적인 Temporal Asymmetry와 Gradient Instability 문제를 효과적으로 해결합니다. OmniForcing 은 단일 GPU에서 ~25 FPS 의 스트리밍 성능을 달성하면서도 Bidirectional Teacher 모델에 필적하는 Visual Quality와 Multi-modal Synchronization을 유지합니다. 이 연구는 Interactive하고 Latency-sensitive한 시나리오에서 Multi-modal Foundation Model을 배포할 수 있는 새로운 가능성을 열어줌으로써, Real-time Generative AI 분야에 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models
- [논문리뷰] Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
- [논문리뷰] VLM-SubtleBench: How Far Are VLMs from Human-Level Subtle Comparative Reasoning?
- [논문리뷰] UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
- [논문리뷰] Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Review 의 다른글
- 이전글 [논문리뷰] Multimodal OCR: Parse Anything from Documents
- 현재글 : [논문리뷰] OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
- 다음글 [논문리뷰] SimRecon: SimReady Compositional Scene Reconstruction from Real Videos
댓글