[논문리뷰] MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
링크: 논문 PDF로 바로 열기
저자: S. Bai, L. Bing, L. Lei, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MiroThinker-1.7 : 복잡한 long-horizon reasoning task를 위해 설계된 새로운 연구 에이전트. Structured planning, contextual reasoning, tool interaction에 중점을 둔 agentic mid-training stage를 통해 각 interaction step의 reliability를 향상시킨다.
- MiroThinker-H1 : MiroThinker-1.7을 기반으로 heavy-duty reasoning capabilities를 확장한 에이전트. Local Verifier와 Global Verifier를 통합하여 reasoning process에 verification을 직접 포함함으로써 multi-step problem solving의 reliability를 강화한다.
- ReAct paradigm : Language model이 reasoning과 tool invocation을 번갈아 수행하며 환경과 상호작용하는 agent-environment interaction loop를 구현하는 프레임워크. MiroThinker-1.7은 이를 기반으로 context management 및 tool-call correction 기능을 추가한다.
- Local Verifier : MiroThinker-H1의 핵심 구성 요소로, inference 중에 intermediate reasoning decision (예: planning decision, tool invocation, hypothesis updates)을 평가하고 refine하여 잠재적 오류를 reasoning trajectory 초기에 수정하도록 돕는다.
- Global Verifier : MiroThinker-H1의 핵심 구성 요소로, overall reasoning trajectory를 audit하고 candidate solution path를 비교하여 최종 답변이 coherent하고 well-grounded chain of evidence에 의해 뒷받침되는지 확인한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Large Language Models (LLMs)는 유창한 텍스트 생성 및 광범위한 질문 답변 능력에서 상당한 발전을 이루었지만, scientific analysis, financial reasoning, open-ended research와 같은 많은 real-world 문제들은 단순한 conversational ability를 넘어선다. 이러한 태스크들은 일반적으로 long chains of reasoning, iterative information gathering, 그리고 intermediate conclusion을 최종 답변으로 확정하기 전에 verify하는 능력을 요구한다.
기존의 agentic AI 시스템들은 multi-step reasoning 및 decision making을 통해 문제를 해결하기 위해 LLM이 도구, 환경 및 외부 지식 소스와 상호작용하도록 설계되었지만, 단순히 reasoning trajectory의 길이를 늘리는 것만으로는 성능이 reliably 향상되지 않았다. Intermediate step이 inaccurate하거나 poorly grounded된 경우, 긴 interaction trajectory는 noise를 축적하고 오류를 전파하여 궁극적으로 solution quality를 저하시킬 수 있었다. 이에 MiroMind Team은 long-horizon reasoning의 성능을 개선하기 위해 단순히 interaction length를 늘리는 것이 아니라 effective interaction scaling 이 필요하다는 문제 인식을 제시했다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 MiroThinker-1.7 과 그 확장 모델인 MiroThinker-H1 을 제안하여 이러한 문제를 해결한다.
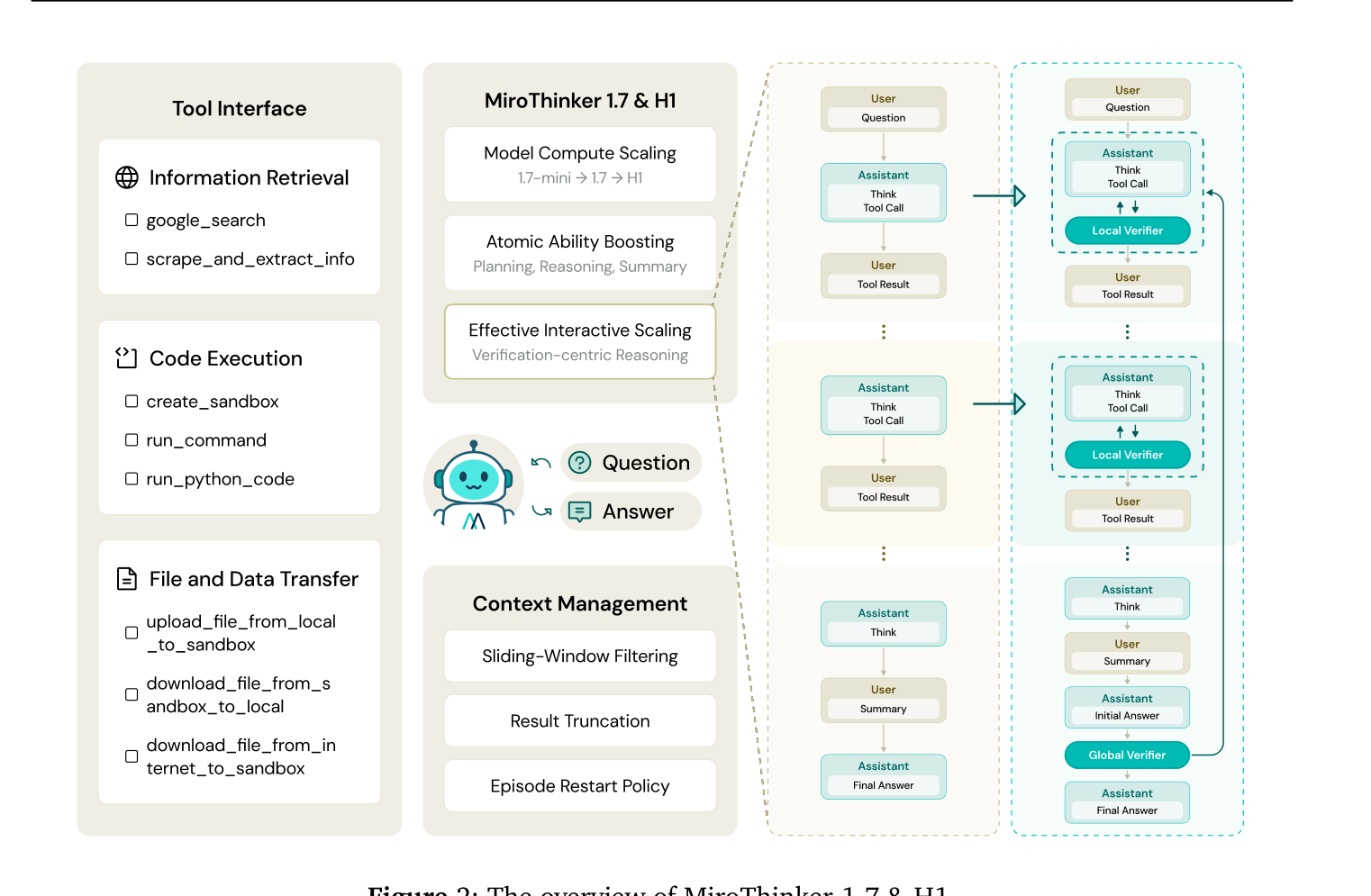 Figure 2: The overview of MiroThinker-1.7 & H1.
Figure 2: The overview of MiroThinker-1.7 & H1.
는 MiroThinker-1.7 및 H1의 전반적인 아키텍처를 보여준다. MiroThinker-1.7은 structured planning, contextual reasoning, tool interaction, answer summarization을 강조하는 agentic mid-training stage를 통해 step-level agentic atomic capabilities를 강화하여 보다 effective한 interaction scaling을 가능하게 한다. MiroThinker-H1은 여기에 Local Verifier 와 Global Verifier 를 통합하여 verification-centric reasoning mode를 도입한다. Local Verifier는 intermediate reasoning decision을 평가하고 refine하며, Global Verifier는 overall reasoning trajectory를 audit하여 coherent한 증거 체인을 보장한다.
모델은 Qwen3 MoE 모델을 기반으로 4단계 훈련 파이프라인을 거친다. [Figure 4]에서 볼 수 있듯이, 1단계 Mid-training은 atomic agentic capabilities (planning, reasoning, tool call, answer summarization)를 강화하고, 2단계 Supervised Fine-Tuning (SFT)은 structured agentic interaction behaviors를 학습시킨다. 3단계 Preference Optimization (DPO)은 task objectives와 behavior preferences에 맞게 모델을 정렬하며, 4단계 Reinforcement Learning (RL)은 real-world 환경에서 creative exploration과 generalization을 촉진한다.
광범위한 벤치마크 평가 결과, MiroThinker-H1 은 open-web research, scientific reasoning, financial analysis 등 다양한 deep research task에서 State-of-the-Art (SOTA) 성능을 달성했다.
- MiroThinker-H1 은 BrowseComp에서 88.2 , BrowseComp-ZH에서 84.4 를 기록하여 Gemini-3.1-Pro ( 85.9 ) 및 Claude-4.6-Opus ( 84.0 )와 같은 강력한 commercial agent를 능가한다.
- GAIA 벤치마크에서는 88.5 로 기존 SOTA 모델인 OpenAI-GPT-5 ( 76.4 )를 12.1%p 앞서며, SEAL-0에서 61.3 을 달성하여 모든 평가 모델 중 최고 기록을 세웠다.
- 전문 도메인 벤치마크에서는 FrontierSci-Olympiad ( 79.0 ), FinSearchComp ( 73.9 ), MedBrowseComp ( 56.5 )에서 최고 성능을 기록했다.
- MiroThinker-1.7-mini (3B parameters) 또한 BrowseComp-ZH 및 GAIA에서 GPT-5 및 DeepSeek-V3.2와 같은 강력한 모델보다 뛰어난 경쟁력 있는 결과를 보여준다.
- MiroThinker-1.7-mini는 MiroThinker-1.5-30B 대비 평균 16.7% 더 높은 성능을 달성하며, 평균 43.0% 더 적은 interaction rounds를 사용했다. 특히 long-horizon task인 HLE에서는 61.6% 더 적은 rounds로 17.4% 향상된 성능을 보였다. [Figure 6]은 이러한 성능과 interaction rounds 간의 관계를 보여준다.
- Local Verifier는 BrowseComp hard subset (295개 질문)에서 Pass@1을 32.1 에서 58.5 로 +26.4%p 향상시켰으며, 필요한 interaction step 수를 1185.2 에서 210.8 로 약 6분의 1 수준으로 줄였다.
- Global Verifier는 BrowseComp와 SEAL-0과 같은 search-intensive task에서 각각 +14.2%p 와 +8.3%p 의 성능 향상을 가져왔으며, FrontierScience-Olympiad와 HLE와 같은 challenging reasoning task에서도 각각 +7.5%p 와 +4.8%p 의 개선을 보였다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 agentic AI의 long-horizon reasoning에 내재된 도전 과제를 해결하기 위해 MiroThinker-1.7 과 플래그십 시스템인 MiroThinker-H1 을 도입했다. 단순히 trajectory 길이를 늘리는 것이 아니라 effective interaction scaling을 강조함으로써, 계획, 추론, 도구 사용 능력을 크게 향상시키는 강화된 훈련 파이프라인을 개발했다. 또한, local 및 global 수준에서 verification-centric reasoning mode를 통합하여 intermediate step이 지속적으로 감사되고 refine되며, 최종 solution에 대한 확신을 높였다.
BrowseComp, FrontierScience-Olympiad, FinSearchComp 등 다양하고 복잡한 벤치마크에 대한 광범위한 평가는 MiroThinker-H1이 leading open-source 및 commercial research agent를 능가하는 새로운 SOTA를 확립했음을 입증했다. 이러한 결과는 agent-native training과 verification-centric reasoning의 결합이 complex real-world 환경에서 지속적인 long-chain reasoning 및 reliable problem solving이 가능한 AI 시스템을 구축하는 유망한 경로임을 시사한다. 이는 학계와 산업계 모두에서 더욱 신뢰할 수 있고 효율적인 AI 연구 도우미 개발에 중요한 영향을 미칠 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
- [논문리뷰] MemTrain: Self-Supervised Context Memory Training
- [논문리뷰] Learning When to Act or Refuse: Guarding Agentic Reasoning Models for Safe Multi-Step Tool Use
- [논문리뷰] MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning
- [논문리뷰] Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
Review 의 다른글
- 이전글 [논문리뷰] M^3: Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM
- 현재글 : [논문리뷰] MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
- 다음글 [논문리뷰] Mixture of Style Experts for Diverse Image Stylization
댓글