[논문리뷰] M^3: Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM
링크: 논문 PDF로 바로 열기
저자: Kerui Ren, Guanghao Li, Changjian Jiang, Yingxiang Xu, Tao Lu, Linning Xu, Junting Dong, Jiangmiao Pang, Mulin Yu, Bo Dai
1. Key Terms & Definitions (핵심 용어 및 정의)
- M³ (Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM) : 저자들이 제안하는 프레임워크로, dense matching과 multi-view foundation model을 monocular Gaussian Splatting SLAM에 통합한 시스템을 지칭합니다.
- Pi3X : M³ 프레임워크의 기반이 되는 multi-view foundation model로, 카메라 pose 및 depth estimation을 효율적으로 수행하도록 설계된 permutation-equivariant feed-forward network입니다.
- 3DGS (3D Gaussian Splatting) : 고품질 렌더링을 위해 장면을 anisotropic Gaussian primitives로 표현하는 기술입니다.
- ATE RMSE (Absolute Trajectory Error Root Mean Square Error) : SLAM 시스템의 pose estimation 정확도를 평가하는 주요 지표 중 하나입니다.
- PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index Measure), LPIPS (Learned Perceptual Image Patch Similarity) : 렌더링 품질을 평가하는 데 사용되는 주요 지표들입니다. PSNR과 SSIM은 높을수록, LPIPS는 낮을수록 좋습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
uncalibrated monocular video로부터 streaming reconstruction을 수행하는 것은 고정밀 pose estimation과 동적 환경에서의 계산적으로 효율적인 online refinement가 모두 필요하므로 여전히 challenging합니다. 기존 multi-view foundation model들은 주로 feed-forward 방식으로 pose를 추정하여, rigorous geometric optimization에 필요한 pixel-level correspondences의 정밀도가 부족하다는 한계가 있었습니다. 특히, 대부분의 foundation model은 개별 scene geometry에 disproportionate하게 초점을 맞추어 inter-view relational consistency가 부족하고, 이는 Bundle Adjustment (BA) 의 강력한 epipolar constraints를 확립하는 데 어려움을 초래하여 catastrophic failure로 이어질 수 있습니다. 결과적으로, 기존 SLAM 시스템들은 종종 computational redundancy에 시달리거나 충분한 geometric precision을 확보하지 못했습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 M³ 를 제안합니다. M³는 기존 Pi3X multi-view foundation model에 dedicated Matching head 를 추가하여 pixel-level descriptors를 활용한 fine-grained dense correspondences를 가능하게 합니다. 이 enhanced foundation model은 robust Monocular Gaussian Splatting SLAM 프레임워크에 통합되어 frontend tracking과 backend global optimization을 단일 feed-forward inference를 통해 동시에 수행합니다
![Figure 2: The M³ Pipeline. The framework consists of joint tracking and global optimization for pose estimation and a mapper for scene reconstruction. For monocular sequences, Pi3X processes retrieved historical keyframes and new frames in one inference to facilitate factor graph construction and keyframe selection. Following the Neural Gaussian and LOD architecture of ARTDECO [19], Gaussians are initialized via Laplacian norm and optimized jointly with camera poses.](/paper-images/2026-03-18/2603.16844/figure_2.png) Figure 2: The M³ Pipeline. The framework consists of joint tracking and global optimization for pose estimation and a mapper for scene reconstruction. For monocular sequences, Pi3X processes retrieved historical keyframes and new frames in one inference to facilitate factor graph construction and keyframe selection. Following the Neural Gaussian and LOD architecture of ARTDECO [19], Gaussians are initialized via Laplacian norm and optimized jointly with camera poses.
Figure 2: The M³ Pipeline. The framework consists of joint tracking and global optimization for pose estimation and a mapper for scene reconstruction. For monocular sequences, Pi3X processes retrieved historical keyframes and new frames in one inference to facilitate factor graph construction and keyframe selection. Following the Neural Gaussian and LOD architecture of ARTDECO [19], Gaussians are initialized via Laplacian norm and optimized jointly with camera poses.
. 또한, M³ 는 dynamic area suppression 을 위한 descriptor-based motion estimation module 과 cross-inference intrinsic alignment 를 통해 tracking stability를 향상시킵니다. Neural Gaussian Reconstruction 과정에서는 Laplacian-of-Gaussian (LoG) probability map 을 활용하여 high-frequency details과 poorly reconstructed areas를 우선순위로 두고 Gaussians를 초기화하며, dynamic pixel을 명확히 배제합니다.
실험 결과, M³ 는 다양한 indoor 및 outdoor benchmarks에서 state-of-the-art 성능을 달성했습니다. Pose estimation 측면에서, M³ 는 VGGT-SLAM 2.0 대비 ATE RMSE 를 64.3% 감소시켰으며, 특히 ScanNet++ 데이터셋에서 0.065 m 의 가장 낮은 ATE RMSE 를 기록했습니다
 Table 1: Tracking comparisons in terms of ATE RMSE (m). We compare against state-of-the-art SLAM frameworks on both indoor and outdoor datasets. The best and second-best results are highlighted in bold and underline, respectively.
Table 1: Tracking comparisons in terms of ATE RMSE (m). We compare against state-of-the-art SLAM frameworks on both indoor and outdoor datasets. The best and second-best results are highlighted in bold and underline, respectively.
. Scene reconstruction 품질에서는 ARTDECO 대비 ScanNet++ 에서 PSNR 이 2.11 dB 향상되었고, 28.82 dB PSNR , 0.892 SSIM , 0.190 LPIPS 로 모든 SLAM-based Gaussian Splatting methods 중 가장 우수한 성능을 보였습니다
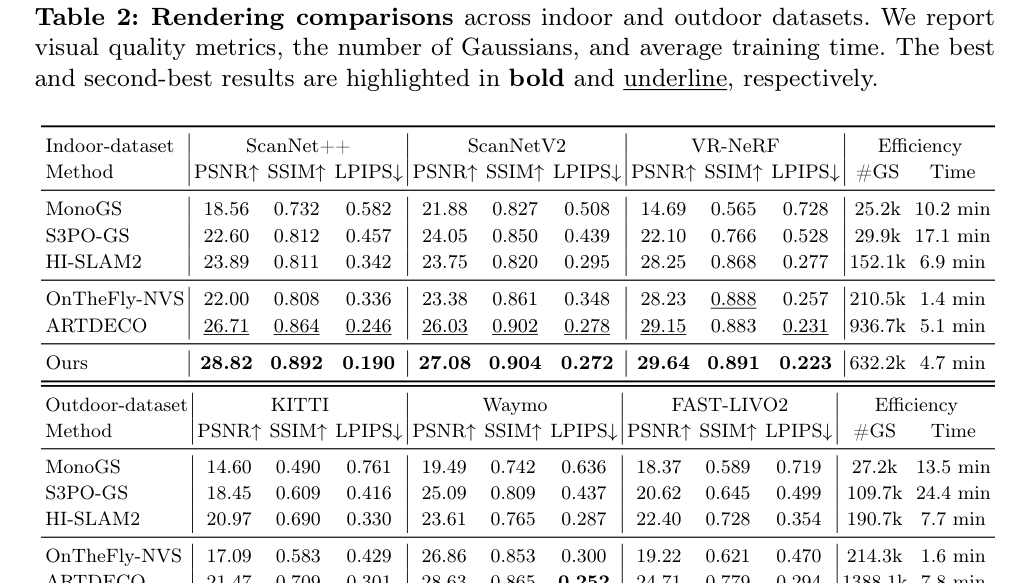 Table 2: Rendering comparisons across indoor and outdoor datasets. We report visual quality metrics, the number of Gaussians, and average training time. The best and second-best results are highlighted in bold and underline, respectively.
Table 2: Rendering comparisons across indoor and outdoor datasets. We report visual quality metrics, the number of Gaussians, and average training time. The best and second-best results are highlighted in bold and underline, respectively.
. Feed-forward Gaussian Splatting methods와 비교했을 때도, M³ 는 ScanNet++에서 27.789 PSNR 을 기록하여 AnySplat 의 22.337 PSNR 보다 월등히 높은 reconstruction quality를 달성했습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
결론적으로, M³ 는 uncalibrated monocular video를 위한 효율적이고 robust한 streaming reconstruction 프레임워크를 제시합니다. 이 연구의 핵심은 multi-view foundation model인 Pi3X 를 pixel-level dense matching으로 강화하고 이를 SLAM pipeline에 긴밀하게 통합한 것입니다. 이러한 설계는 pose optimization을 위한 consistent dense correspondences를 가능하게 하고, redundant model inference를 줄여주며, long video stream에서 고품질 3DGS reconstruction과 안정적인 tracking을 지원합니다. 또한, M³ 는 descriptor-based dynamic region suppression 및 intrinsic alignment 를 통해 real-world 환경의 복잡성을 효과적으로 처리하고 global consistency를 향상시켜 trajectory drift를 완화합니다. 이 연구는 practical하고 scalable한 streaming reconstruction을 향한 중요한 진전으로 평가됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ArtHOI: Taming Foundation Models for Monocular 4D Reconstruction of Hand-Articulated-Object Interactions
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Vision as Unified Multimodal Generation
- [논문리뷰] Image2Sim: Scaling Embodied Navigation via Generative Neural Simulator
- [논문리뷰] PixWorld: Unifying 3D Scene Generation and Reconstruction in Pixel Space
Review 의 다른글
- 이전글 [논문리뷰] Kinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
- 현재글 : [논문리뷰] M^3: Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM
- 다음글 [논문리뷰] MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
댓글