[논문리뷰] Kinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
링크: 논문 PDF로 바로 열기
저자: Mutian Xu, Tianqi Liu, Zhaoxi Chen, Tianbao Zhang, Xiaoguang Han, Ziwei Liu et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Kinema4D : 로봇-월드 상호작용을 4D Spatiotemporal Events로 모델링하고 시뮬레이션하기 위해 제안된 action-conditioned 4D generative robotic simulator.
- 4D Spatiotemporal Events : 3D 공간과 시간(time) 축을 모두 고려한 로봇-월드 상호작용으로, 물리적 및 기하학적 일관성을 요구하는 개념입니다.
- Kinematic Control : 로봇의 URDF 모델과 Inverse Kinematics (IK), Forward Kinematics (FK)를 활용하여 정밀한 4D 로봇 control trajectory를 생성하는 과정입니다.
- Pointmap : 카메라 space의 (x, y, z) 좌표를 pixel 값으로 저장하는 4D spatial representation으로, 로봇 trajectory나 환경의 3D geometry 정보를 인코딩합니다.
- Diffusion Transformer (DiT) : Kinema4D의 핵심 generative backbone으로, synchronized RGB 및 pointmap sequences를 생성하여 환경의 reactive dynamics를 모델링하는 데 사용됩니다.
- Robo4D-200k : Kinema4D 학습을 위해 curation된 대규모 4D robotic dataset으로, 201,426개의 robot interaction episode와 high-quality 4D annotation을 포함합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Embodied AI 분야에서 로봇 trajectory를 세계 환경 내에서 roll out하는 능력은 demonstration 확장, policy evaluation 및 reinforcement learning에 매우 중요합니다. 하지만 실제 환경에서의 action 실행은 비용이 많이 들고 안전하지 않으며 지속적인 전문가 유지보수가 필요합니다. 기존의 물리 simulator들은 시각적 realism이 부족하고 hand-crafted된 물리적 특성 및 규칙에 의존하여 확장성에 한계가 있었습니다. 최근 비디오 생성 모델을 활용한 연구는 이러한 한계를 극복하려 했지만, 주로 2D pixel space 에서 작동하거나 static environmental cues 에 의존하여 로봇-월드 상호작용의 본질적인 4D spatiotemporal events 특성을 간과했습니다. 일부 최신 4D simulation 연구는 high-level linguistic instruction을 사용했으나, material deformation이나 occluded object dynamics와 같은 high-fidelity 상호작용 모델링에 필수적인 precise guidance 가 부족했습니다. 이 논문은 이러한 한계를 극복하고 로봇 control의 정확성을 유지하면서 4D 본질을 복원하는 새로운 action-conditioned 4D generative robotic simulator인 Kinema4D를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Kinema4D를 제안하며 로봇-월드 상호작용을 Kinematic Control 과 Generative 4D Modeling 두 가지 synergistic한 통찰력으로 분리하여 시뮬레이션합니다
![Figure 2: Overview of our Kinema4D. 1) Kinematics Control: Given a 3D robot with its URDF at initial canonical setup space, and an action sequence, we drive the 3D robot via kinematics to produce a 4D robot trajectory, which is then projected into a pointmap sequence. This process re-represents raw actions as a spatiotemporal visual signal. 2) 4D Generative Modeling: This signal and the initial main-view world image are sent to a shared VAE encoder, then fused with an occupancy-aligned robot mask and noise, which are denoised by a Diffusion Transformer [56] to generate a full future 4D (pointmap+RGB) world sequence.](/paper-images/2026-03-18/2603.16669/figure_2.png) Figure 2: Overview of our Kinema4D. 1) Kinematics Control: Given a 3D robot with its URDF at initial canonical setup space, and an action sequence, we drive the 3D robot via kinematics to produce a 4D robot trajectory, which is then projected into a pointmap sequence. This process re-represents raw actions as a spatiotemporal visual signal. 2) 4D Generative Modeling: This signal and the initial main-view world image are sent to a shared VAE encoder, then fused with an occupancy-aligned robot mask and noise, which are denoised by a Diffusion Transformer [56] to generate a full future 4D (pointmap+RGB) world sequence.
Figure 2: Overview of our Kinema4D. 1) Kinematics Control: Given a 3D robot with its URDF at initial canonical setup space, and an action sequence, we drive the 3D robot via kinematics to produce a 4D robot trajectory, which is then projected into a pointmap sequence. This process re-represents raw actions as a spatiotemporal visual signal. 2) 4D Generative Modeling: This signal and the initial main-view world image are sent to a shared VAE encoder, then fused with an occupancy-aligned robot mask and noise, which are denoised by a Diffusion Transformer [56] to generate a full future 4D (pointmap+RGB) world sequence.
. 첫째, Kinematic Control 단계에서는 URDF 기반 3D 로봇 모델을 사용하여 Inverse Kinematics (IK) 및 Forward Kinematics (FK)를 통해 정밀한 4D 로봇 control trajectory를 생성합니다. 이 trajectory는 pointmap sequence 로 projection되어 spatiotemporal visual signal로 사용됩니다. 둘째, Generative 4D Modeling 단계에서는 이 4D robot pointmap sequence 와 initial world image를 입력으로 받아, Diffusion Transformer (DiT) backbone을 통해 future robot-world interactions를 synchronized RGB 및 pointmap sequences로 4D 공간에서 생성합니다. 이는 LoRA (Low-Rank Adaptation)를 사용하여 WAN 2.1 (14B parameters) base model에 4DNex pre-trained weights로 fine-tuning됩니다. Robo4D-200k 라는 201,426개의 에피소드를 포함하는 대규모 4D robotic dataset을 구축하여 모델 학습을 지원했습니다.
핵심 실험 결과는 다음과 같습니다:
- Video Generation Metrics : Kinema4D는 PSNR↑ 22.50 , SSIM↑ 0.864 , FID↓ 25.2 , FVD↓ 98.5 를 기록하며 UniSim, IRASim, Ctrl-World 등 기존 2D output baselines 및 TesserAct와 같은 4D output baseline 대비 대부분의 지표에서 우수한 성능을 보였습니다
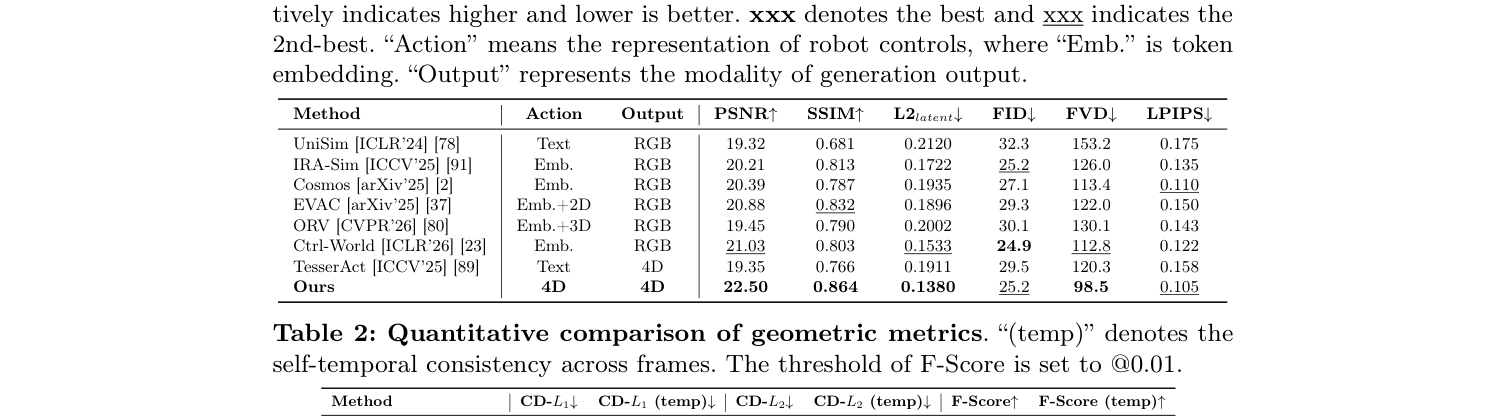 Table 1: Quantitative comparison of video generation metrics. ↑ and ↓ respectively indicates higher and lower is better. xxx denotes the best and xxx indicates the 2nd-best. "Action" means the representation of robot controls, where "Emb." is token embedding. "Output" represents the modality of generation output.
Table 1: Quantitative comparison of video generation metrics. ↑ and ↓ respectively indicates higher and lower is better. xxx denotes the best and xxx indicates the 2nd-best. "Action" means the representation of robot controls, where "Emb." is token embedding. "Output" represents the modality of generation output.
. 특히 FVD (Fréchet Video Distance)와 LPIPS (Learned Perceptual Image Patch Similarity)에서 현저히 낮은 값(더 좋음)을 달성하며 높은 시각적 fidelity를 입증했습니다.
- Geometric Metrics : 4D output에 대한 geometric metrics 비교에서 Kinema4D는 CD-L1↓ 0.0479 , CD-L1 (temp)↓ 0.0077 , F-Score↑ 0.4733 를 기록하며 TesserAct 대비 우수한 geometric accuracy와 temporal consistency를 보였습니다 [Table 2].
- Policy Evaluation : Simulation 환경에서 ground truth와 유사한 success rate를 달성했으며, zero-shot OOD (Out-Of-Distribution) real-world 환경에서도 합리적인 수준의 성능을 보여, 실제 환경에서의 policy evaluation을 위한 잠재력을 입증했습니다 [Table 3].
- Qualitative Results : Ctrl-World 대비 왜곡되지 않은 로봇 action과 현실적인 환경 전환을 보여주며 우수한 fidelity를 달성했습니다 [Figure 4]. TesserAct 대비 "near-miss" failure cases를 포함한 ground-truth 실행을 정확히 반영했으며, RGB texture가 2D view에서 겹칠 때도 gripper와 object 사이의 spatial gap을 정확하게 해석하는 능력을 보여주었습니다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
Kinema4D는 로봇 시뮬레이션 패러다임을 4D spatiotemporal reasoning으로 전환하는 새로운 framework를 제시합니다. Kinematics-driven grounding stage와 diffusion transformer 기반의 generative pipeline을 통합함으로써, deterministic 로봇 motion과 stochastic 환경 반응을 효과적으로 decouple합니다. 실험 결과는 Kinema4D가 다양한 real-world dynamics를 시뮬레이션할 수 있음을 입증했으며, scalable하고 high-fidelity, 복잡한 Embodied Simulation을 위한 새로운 기반을 마련했습니다. 이 연구는 Embodied AI 분야에서 로봇 정책 평가 및 학습의 정확성과 신뢰성을 크게 향상시키고, 차세대 Embodied Simulation의 발전을 위한 중요한 foundation을 제공할 것입니다. 환경 dynamics가 통계적 합성(statistical synthesis)을 통해 학습되므로, 때로는 conservation laws를 위반하거나 penetration artifacts를 보일 수 있지만, 이는 향후 물리 법칙 통합을 통한 연구 과제로 남겨두었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
- [논문리뷰] Seed3D 1.0: From Images to High-Fidelity Simulation-Ready 3D Assets
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] Infinite Worlds with Versatile Interactions
- [논문리뷰] Imagined Rollouts are Kinematic, Not Dynamic: A Diagnosis of Long-Horizon World-Model Failure
Review 의 다른글
- 이전글 [논문리뷰] InCoder-32B: Code Foundation Model for Industrial Scenarios
- 현재글 : [논문리뷰] Kinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
- 다음글 [논문리뷰] M^3: Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM
댓글