[논문리뷰] InCoder-32B: Code Foundation Model for Industrial Scenarios
링크: 논문 PDF로 바로 열기
저자: Jian Yang, Wei Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- InCoder-32B : 하드웨어 의미론(hardware semantics), 특수 언어 구성체(specialized language constructs), 엄격한 자원 제약(strict resource constraints)이 요구되는 산업 시나리오를 위해 설계된 32B 파라미터 코드 파운데이션 모델입니다. 칩 설계, GPU 커널 최적화, 임베디드 시스템, 컴파일러 최적화, 3D 모델링 전반에 걸친 코드 인텔리전스를 통합합니다.
- Industrial Code Intelligence : 일반적인 소프트웨어 엔지니어링과 달리 도메인별 언어 구문, 하드웨어 인식 최적화, 엄격한 기능적 정확성, 타이밍 제약 조건 및 리소스 제약 조건을 처리해야 하는 산업용 소프트웨어 개발 영역을 위한 LLM의 능력을 의미합니다.
- Code-Flow pipeline : InCoder-32B 의 훈련에 사용되는 3단계 훈련 파이프라인으로, 사전 훈련(Pre-training & Annealing), 중간 훈련(Mid-training), 후속 훈련(Post-training)으로 구성됩니다.
- Execution-grounded verification : InCoder-32B 의 후속 훈련 단계에서 사용되는 검증 방식으로, 생성된 코드를 실제 실행 환경(compilation, simulation, test execution, performance profiling, formal checking)에서 검증하여 사실적 정확성과 성능을 보장합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 코드 대규모 언어 모델(LLMs)은 일반적인 프로그래밍 task에서 상당한 발전을 이루었지만, 하드웨어 의미론, 특수 언어 구성체 및 엄격한 자원 제약 조건에 대한 추론이 필요한 산업 시나리오에서는 그 성능이 크게 저하되는 문제를 겪고 있습니다. 기존의 최강 코드 LLM조차 Triton 연산자 생성에서 28.80% 의 낮은 호출 성공률과 Verilog 코드 생성에서 33.3% 의 정확도만을 보이는 등, 산업 task를 out-of-distribution task로 처리하는 한계를 보였습니다. 이러한 한계는 학계의 코드 벤치마크와 칩 설계, GPU 커널 최적화, 임베디드 시스템, 컴파일러 최적화, 3D 모델링과 같은 실제 산업 엔지니어링 도메인 간의 중요한 격차를 발생시킵니다. 본 연구는 이러한 격차를 해소하고 산업용 코드 인텔리전스를 위한 통합 파운데이션 모델의 필요성을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구에서는 산업용 코드 인텔리전스를 위해 설계된 최초의 32B 파라미터 코드 파운데이션 모델인 InCoder-32B 를 제안합니다. 이 모델은 Code-Flow pipeline 이라는 체계적인 3단계 훈련 방식을 따릅니다. 첫째, 일반 코드 사전 훈련과 선별된 산업 코드 어닐링(annealing)을 통해 데이터의 질을 높입니다. 둘째, 중간 훈련 단계에서는 8K 토큰에서 128K 토큰으로 점진적으로 Context Length를 확장하며, 합성된 산업 추론 데이터와 에이전트 궤적(agentic trajectories)을 활용합니다
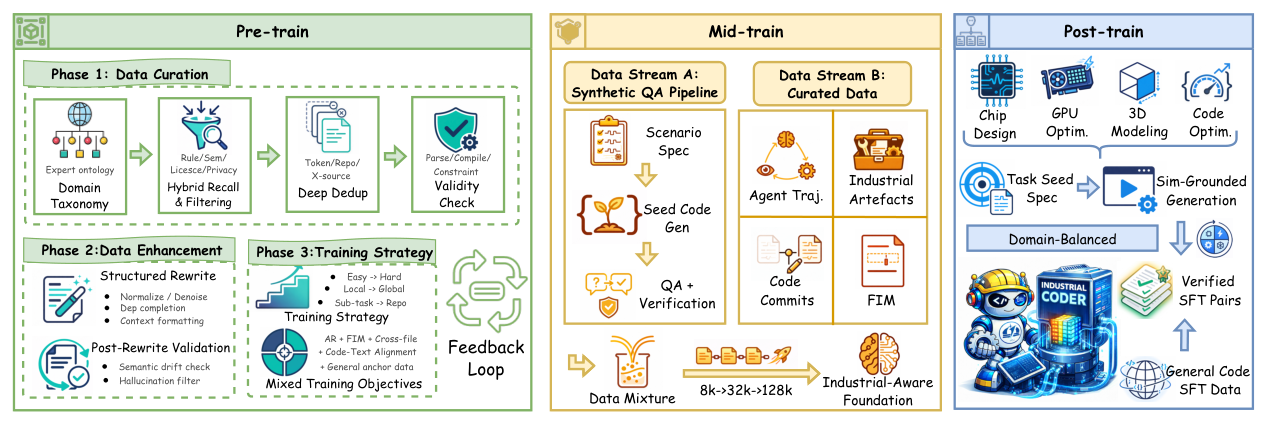 Figure 3: The three-stage training pipeline of InCoder-32B. Pre-train performs data curation and enhancement, Mid-train constructs an industrial-aware foundation with progressive context scaling from 8K to 128K, and Post-train produces simulation-grounded SFT data across industrial domains.
Figure 3: The three-stage training pipeline of InCoder-32B. Pre-train performs data curation and enhancement, Mid-train constructs an industrial-aware foundation with progressive context scaling from 8K to 128K, and Post-train produces simulation-grounded SFT data across industrial domains.
. 이 합성 데이터는 실제 산업 시나리오를 반영하며, 코드 실행 검증, 정적 분석, 논리적 일관성 검증을 통해 사실적 정확성을 보장합니다. 셋째, 후속 훈련 단계에서는 execution-grounded verification 을 통해 생성된 코드를 실제 환경에서 검증하고, 실패한 코드에 대한 피드백 기반의 수정(Feedback-Driven Repair)을 포함하여 견고성을 높입니다.
InCoder-32B 는 14개의 주류 일반 코드 벤치마크와 4개 전문 분야에 걸친 9개의 산업 벤치마크에서 광범위하게 평가되었습니다. 일반 task에서 SWE-bench Verified 에서 74.8% , LiveCodeBench 에서 49.14% , BFCL 에서 60.99% 를 달성하며 유사 규모 또는 더 큰 규모의 선도 모델들과 경쟁력 있는 성능을 보였습니다. 특히, 산업용 벤치마크에서는
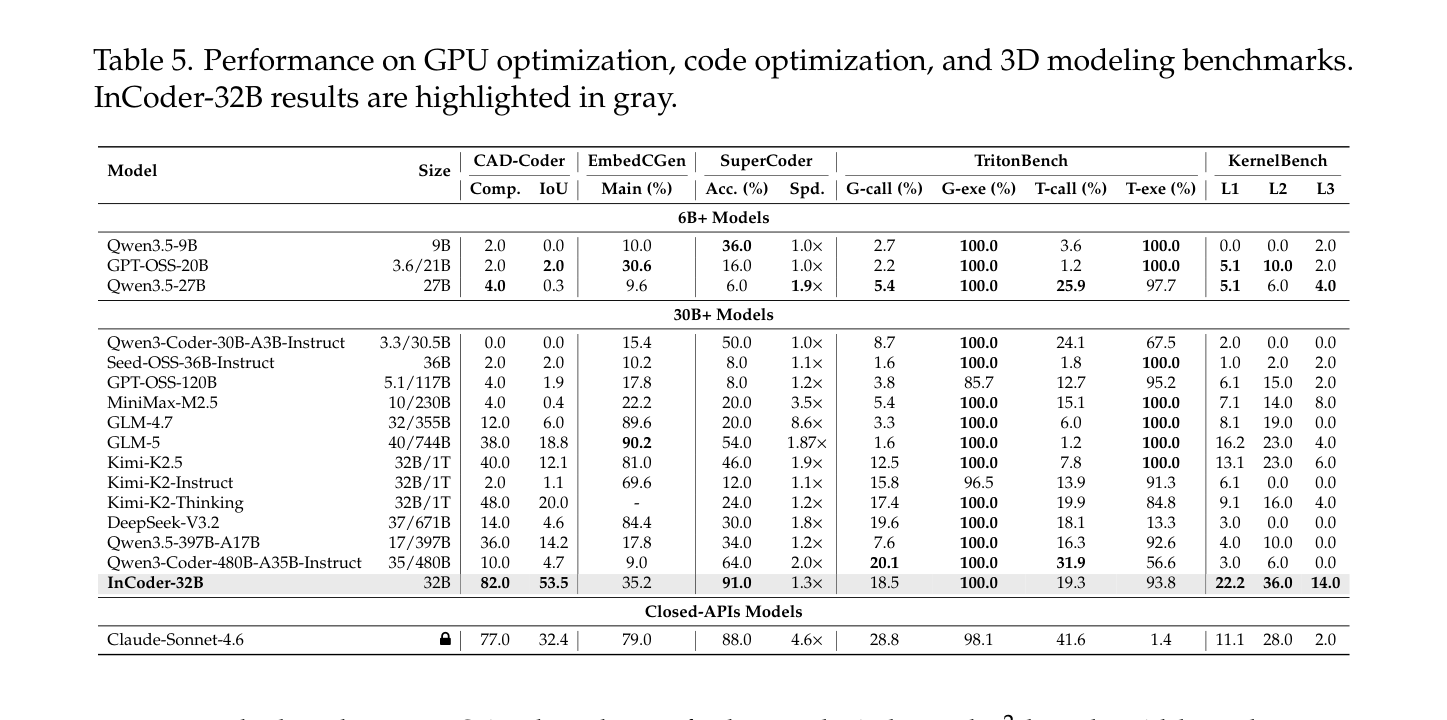 Table 5: Performance on GPU optimization, code optimization, and 3D modeling benchmarks. InCoder-32B results are highlighted in gray.
Table 5: Performance on GPU optimization, code optimization, and 3D modeling benchmarks. InCoder-32B results are highlighted in gray.
에서 볼 수 있듯이, 모든 평가 도메인에서 가장 강력한 오픈 소스 baseline을 확립했습니다. 예를 들어, CAD-Coder 및 KernelBench 의 모든 3개 레벨에서 모든 오픈 소스 baseline을 능가했으며, 심지어 독점 모델인 Claude-Sonnet-4.6 의 CAD-Coder IoU 및 KernelBench L1/L2/L3 성능을 뛰어넘었습니다. 또한, RealBench 모듈 레벨 task에서 가장 우수한 오픈 소스 결과를 달성했습니다. SFT 데이터 스케일링은 83M 에서 250M 토큰으로 증가함에 따라 대부분의 벤치마크에서 일관된 성능 향상을 보여주었습니다 [Figure 6].
4. Conclusion & Impact (결론 및 시사점)
InCoder-32B 는 일반 코드 인텔리전스와 산업용 소프트웨어 개발의 엄격한 요구 사항 사이의 간극을 효과적으로 연결하는 코드 파운데이션 모델입니다. 이 모델은 하드웨어 동작 및 산업 제약 조건에 대한 추론 능력을 습득하면서도 일반 프로그래밍 성능을 희생하지 않으며, 통합된 instruction tuning 및 분석적 추론 프레임워크를 제공합니다. InCoder-32B 의 광범위한 평가는 일반 task에서 선도적인 모델과 경쟁력 있는 성능을 달성함과 동시에 칩 설계, GPU 커널 최적화, 임베디드 시스템, 컴파일러 최적화와 같은 산업 도메인에서 강력한 baseline을 구축했음을 입증합니다. 이러한 연구는 LLM을 실제 산업 시나리오에 적용하는 데 중요한 진전을 보여주며, 향후 산업용 코드 생성 분야의 발전을 가속화할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
- [논문리뷰] AgentKernelArena: Generalization-Aware Benchmarking of GPU Kernel Optimization Agents
- [논문리뷰] Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
- [논문리뷰] K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model
- [논문리뷰] UCoder: Unsupervised Code Generation by Internal Probing of Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent
- 현재글 : [논문리뷰] InCoder-32B: Code Foundation Model for Industrial Scenarios
- 다음글 [논문리뷰] Kinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
댓글