[논문리뷰] GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent
링크: 논문 PDF로 바로 열기
저자: Yuri Kuratov, Matvey Kairov, Aydar Bulatov, Ivan Rodkin, Mikhail Burtsev
1. Key Terms & Definitions (핵심 용어 및 정의)
- GradMem : 제안하는 방법론으로, Test-Time Optimization을 활용하여 LLM이 컨텍스트를 메모리에 효율적으로
WRITE하고READ할 수 있도록 하는 메커니즘입니다. - Test-Time Optimization (TTO) : 모델 파라미터를 고정한 상태에서 추론 시점에 특정 인풋에 맞춰 메모리 토큰과 같은 내부 상태를 Gradient Descent를 통해 최적화하는 과정입니다.
- Context Removal Setting : 모델이 추론 시점에 원본 컨텍스트에 직접 접근할 수 없으며, 사전에 압축되어 메모리에 저장된 정보만을 활용하여 질의에 답변해야 하는 평가 환경입니다.
- Compressive Memory : 긴 컨텍스트를 한 번 읽어 compact한 상태로 저장한 후, 해당 상태에서 여러 쿼리에 답변함으로써 반복적인 컨텍스트 재처리를 피하는 메모리 방식입니다.
- Self-supervised Context Reconstruction Loss : GradMem의
WRITE단계에서 메모리 상태를 최적화하는 데 사용되는 목적 함수로, 메모리에 조건화되었을 때 원본 컨텍스트 토큰을 얼마나 잘 재구성하는지 측정합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Large Language Model(LLM) 애플리케이션들은 방대한 외부 컨텍스트에 의존하며, 이는 KV-cache 와 같은 방식으로 처리될 경우 상당한 메모리 오버헤드를 발생시킵니다. 기존의 Compressive Memory 접근 방식들은 대부분 컨텍스트 인코더를 통해 한 번의 forward pass로 메모리를 생성하는 forward-only WRITE 규칙을 사용하며, 이는 각 샘플에 대한 피드백이나 반복적인 에러 수정 기능을 제공하지 못합니다. 또한, 새로운 정보가 지속적으로 추가되는 환경에서 모델 전체를 retraining하거나 fine-tuning하지 않고 현재 컨텍스트에 빠르게 적응하는 것이 중요합니다. 따라서 저자들은 원본 컨텍스트에 대한 직접적인 접근 없이도 효율적으로 정보를 저장하고 질의에 응답할 수 있는, compact하고 휴대 가능한 컨텍스트 표현 방법을 모색합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 GradMem 을 제안하며, 이는 Test-Time Optimization 을 통해 컨텍스트를 메모리에 WRITE합니다.
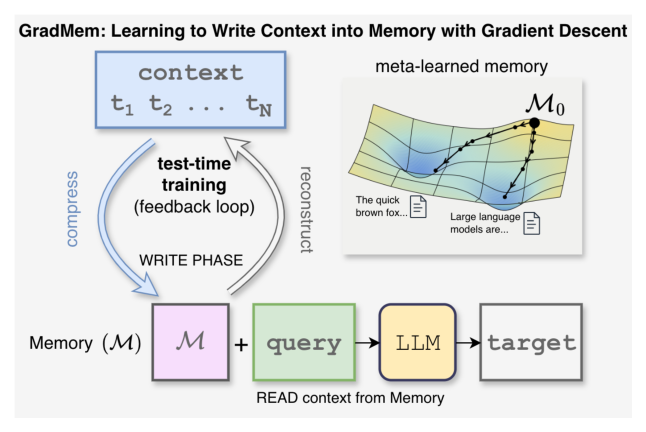 Figure 1: GradMem learns to write context into memory via per-sample test-time optimization.
Figure 1: GradMem learns to write context into memory via per-sample test-time optimization.
에서 볼 수 있듯이, GradMem 은 컨텍스트가 주어지면, 사전 정의된 소량의 메모리 토큰에 대해 Gradient Descent를 수행하여 self-supervised context reconstruction loss 를 최소화합니다. 이 과정에서 모델의 가중치는 고정하며, 메모리 토큰만이 업데이트됩니다. 메모리 초기화는 meta-learning 을 통해 학습되어 몇 번의 Gradient Step만으로 유용한 컨텍스트 표현을 WRITE할 수 있도록 합니다. READ 단계에서는 최적화된 메모리와 질의만을 사용하여 타겟을 예측합니다.
주요 실험 결과는 다음과 같습니다:
- Associative KV-retrieval 태스크에서, GradMem 은 동일한 메모리 크기의 forward-only 메모리
WRITE방식(RMT)보다 우수한 성능을 보였습니다.
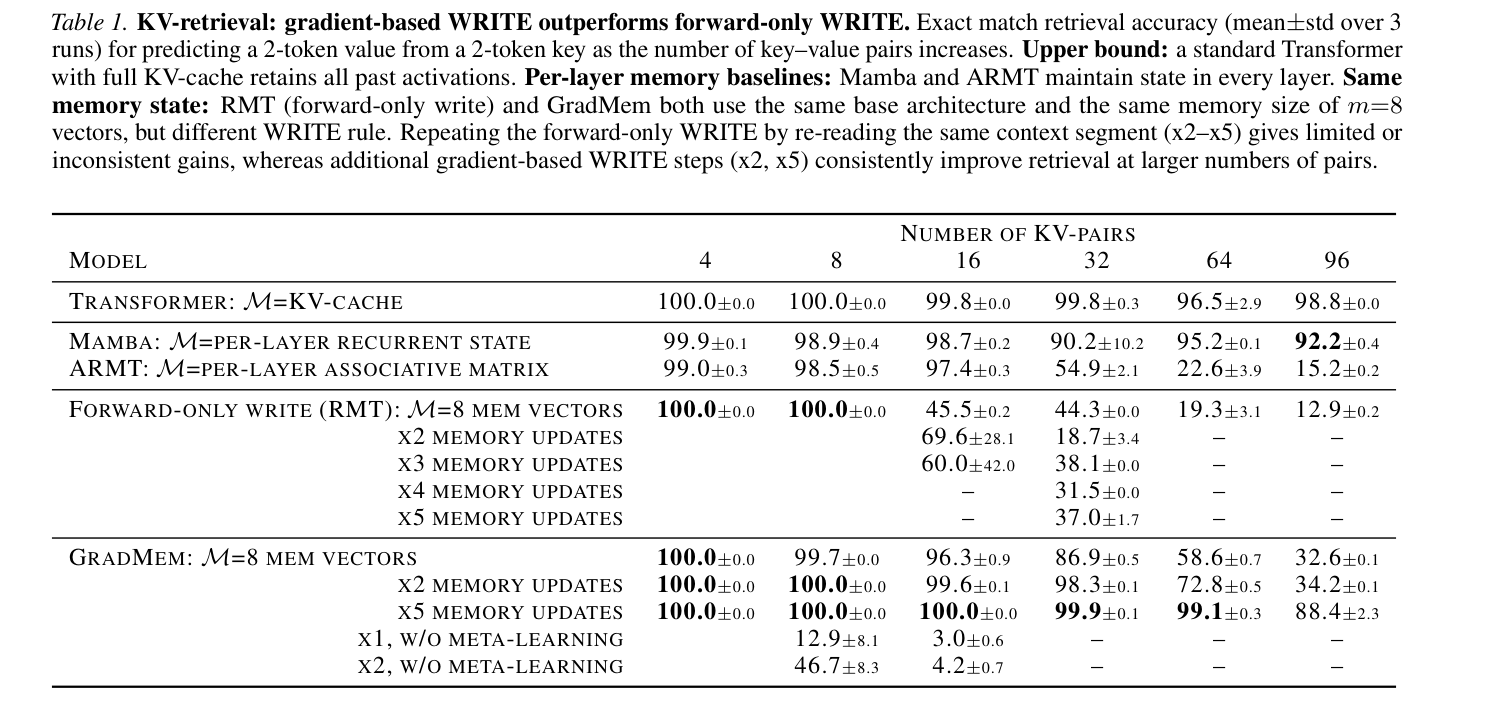 Table 1: KV-retrieval: gradient-based WRITE outperforms forward-only WRITE. Exact match retrieval accuracy (mean±std over 3 runs) for predicting a 2-token value from a 2-token key as the number of key-value pairs increases.
Table 1: KV-retrieval: gradient-based WRITE outperforms forward-only WRITE. Exact match retrieval accuracy (mean±std over 3 runs) for predicting a 2-token value from a 2-token key as the number of key-value pairs increases.
에 따르면, GradMem (K=1) 은 16개 KV-pair 에 대해 96.3% 의 정확도를 달성한 반면, RMT (K=1) 는 45.5% 에 그쳤습니다. K=5 Gradient Step을 적용한 GradMem 은 32개 KV-pair 에 대해 100% , 96개 KV-pair 에 대해 88.4% 의 정확도를 기록하며 RMT 의 반복적인 forward write 방식보다 훨씬 뛰어난 성능을 보였습니다.
- 메모리 용량 스케일링 측면에서, 추가적인 Gradient Step(K 증가)은 메모리 용량과 검색 정확도를 지속적으로 향상시켰습니다.
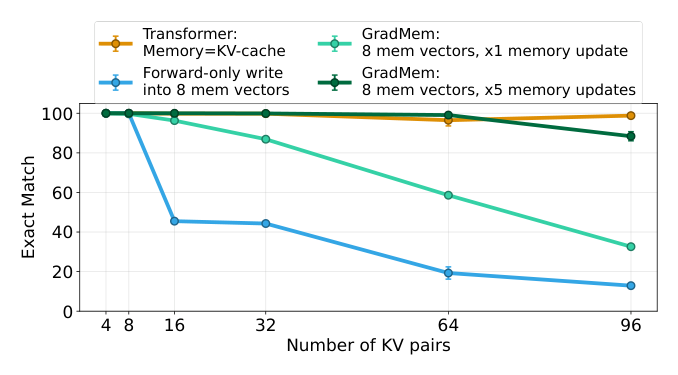 Figure 3: Gradient-based memory updates (GradMem) outperform forward-only updates at the same memory size.
Figure 3: Gradient-based memory updates (GradMem) outperform forward-only updates at the same memory size.
은 GradMem 이 x5 memory updates 를 통해 x1 업데이트나 forward-only 방식보다 훨씬 높은 성능을 달성하는 것을 시각적으로 보여줍니다. [Figure 4a]는 추론 시점에 K_eval 을 늘리는 것이 fine-tuning 없이도 정확도를 크게 높일 수 있음을 입증합니다.
- 자연어 태스크(bAbI, Short SQUAD, Language Modeling) 에서 GradMem 은 경쟁력 있는 성능을 유지했습니다. [Table 2]에서 GradMem (GPT-2, K=1) 은 bAbI QA2 에서 94.2% EM 을 기록하여 RMT (GPT-2) 의 93.9% EM 보다 약간 높은 수치를 보였습니다. Short SQUAD 태스크에서는 GradMem (GPT-2, K=1) 이 38.1% EM 을 달성했으며, K 를 증가시키자 54.9% EM 으로 향상되어 RMT 의 42.6% EM 을 뛰어넘었습니다.
- 연산 효율성 분석 결과, [Figure 7]에서 보듯이, 동일한 컨텍스트에 대해 다수의 질의를 처리할 경우, GradMem 은 GPT-2 및 Mamba 와 비교했을 때 경쟁력 있는
latency를 보였습니다. 특히, 컨텍스트 길이가 256 및 1024 토큰일 때, GradMem 은 약 64회 의READ작업 이후 GPT-2 와break-even을 이루며 Mamba 보다 일관되게 우수한 성능을 보였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Test-Time Gradient Descent 를 활용하여 컨텍스트를 메모리 토큰에 WRITE하는 GradMem 이라는 새로운 WRITE/READ 메모리 메커니즘을 제안합니다. 이 loss-driven 방식은 반복적인 에러 수정을 통해 고정된 메모리 크기에서 forward-only 방식보다 훨씬 많은 정보를 저장하고 높은 정확도를 달성함을 입증했습니다. 특히, fine-tuning 없이 추론 시점에 Gradient Step(K)만 늘려도 메모리 용량을 확장할 수 있다는 점은 이 방법의 핵심적인 이점입니다. GradMem 은 긴 컨텍스트를 처리해야 하는 LLM 애플리케이션에서 효율적인 대안을 제시하며, 향후 더욱 효율적인 meta-training 기법과 개선된 self-supervised WRITE objective 개발에 대한 연구 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] AgenticDataBench: A Comprehensive Benchmark for Data Agents
- [논문리뷰] Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity
- [논문리뷰] Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
Review 의 다른글
- 이전글 [논문리뷰] FinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
- 현재글 : [논문리뷰] GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent
- 다음글 [논문리뷰] InCoder-32B: Code Foundation Model for Industrial Scenarios
댓글