[논문리뷰] FinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
링크: 논문 PDF로 바로 열기
저자: Jiaxuan Lu*, Kong Wang*, Yemin Wang, Qingmei Tang, Hongwei Zeng, Xiang Chen, Jiahao Pi, Shujian Deng, Lingzhi Chen, Yi Fu, Kehua Yang, Xiao Sun, et al.
키워: LLM Agents, Tool Use, Financial Benchmarks, Real-World APIs, Finance-Aware Tool Routing, Compliance Metrics, Trace-level Evaluation
1. Key Terms & Definitions (핵심 용어 및 정의)
- FinToolBench : 금융 도메인의 LLM Agent 를 위한 최초의 실세계, 실행 가능한(runnable) benchmark 로, 760개 의 실행 가능한 금융 도구와 295개 의 도구-필요(tool-required) 쿼리를 포함합니다.
- FATR (Finance-Aware Tool Routing): FinToolBench 를 위한 lightweight baseline 으로, 금융 속성(finance attributes)을 tool card 에 주입하고 안정화된 실행(stabilized execution)을 통해 LLM planner 의 도구 선택 및 추론을 가이드합니다.
- TMR (Timeliness Mismatch Rate), IMR (Intent Mismatch Rate), DMR (Domain Mismatch Rate): FinToolBench 에서 도구 호출(tool call)의 금융 특정 제약 조건(finance-specific constraints) 위반을 측정하는 compliance metrics 입니다.
- TIR (Tool Invocation Rate), TESR (Tool Execution Success Rate), CER (Conditional Execution Rate), SOFT SCORE , CSS (Conditional Soft Score): FinToolBench 에서 LLM Agent 의 도구 사용 능력(capability)을 평가하는 지표입니다.
- Tool Card : 도구의 이름, 설명 및 finance attributes 를 포함하여 LLM planner 가 활용할 수 있도록 정규화된 도구 정보 형식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Models (LLMs)의 금융 도메인 통합은 정적 정보 검색에서 동적이고 에이전트적인 상호작용으로의 paradigm shift 를 주도하고 있습니다. 기존의 일반적인 tool learning benchmark 들은 금융 도메인의 엄격함, 높은 이해 관계(high stakes), 엄격한 규정 준수(strict compliance) 및 빠른 데이터 변동성(rapid data volatility)을 반영하지 못하며, 종종 가상 환경(toy environments)이나 소수의 모의 API 에 의존하는 한계를 가집니다. 반면, 기존 금융 benchmark 는 주로 정적 텍스트 분석이나 문서 기반 QA 에 초점을 맞춰, 복잡한 도구 실행의 현실을 무시합니다.
본 연구는 이러한 격차를 해소하고자 하며, 특히 금융 도메인에서 잘못된 도구 호출이 잘못된 자유 형식 답변보다 더 큰 손해를 야기할 수 있다는 점을 강조합니다. 따라서 평가는 단순히 도구가 성공적으로 호출되고 실행되는지 여부를 넘어, 결과로 생성되는 tool trace 가 timeliness , intent restraint , domain alignment 와 같은 금융 특정 제약 조건(finance-specific constraints)을 준수하는지 여부를 평가해야 합니다. 기존 benchmark 들은 이러한 금융 특정 수용 가능성 제약 조건(acceptability constraints)을 테스트하지 못하는 근본적인 문제점을 가지고 있습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 금융 도메인의 LLM Agent 평가를 위한 최초의 실세계, 실행 가능한 benchmark 인 FinToolBench 를 제안합니다. FinToolBench 는 760개 의 실행 가능한 금융 도구와 295개 의 도구-필요 쿼리로 구성된 방대한 ecosystem 을 구축합니다. 각 도구에는 timeliness , intent type , regulatory domain 의 세 가지 금융 속성이 명시적으로 주석(annotate)되어 있어, call-level compliance mismatch rates 인 TMR , IMR , DMR 를 계산할 수 있습니다. 이는 기존의 이진 실행 성공(binary execution success) 평가를 넘어 금융에 중요한 차원들을 평가합니다.
FinToolBench는 아래 Figure 2에 나타난 8단계의 데이터셋 구축 pipeline을 따릅니다.
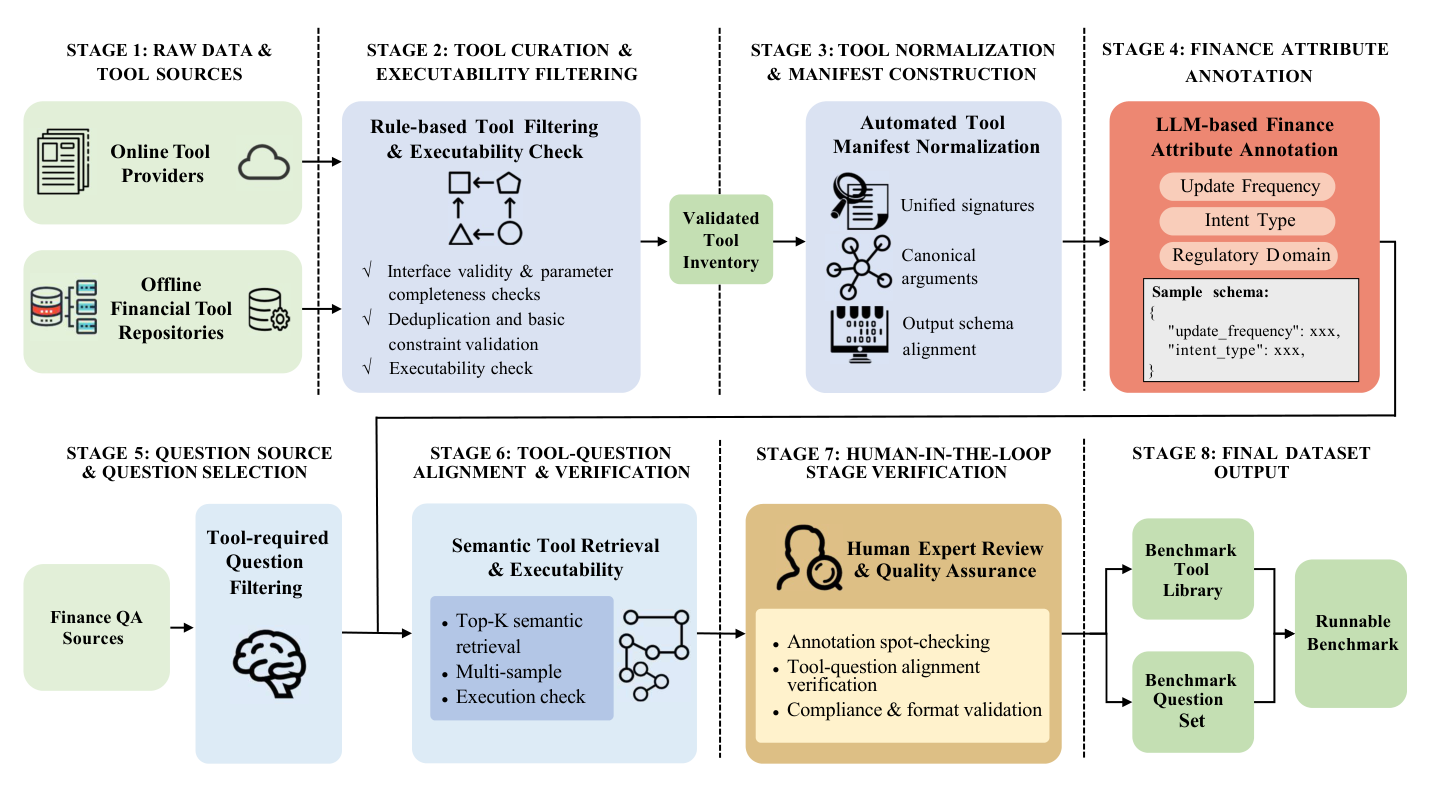 Figure 2: FinToolBench dataset construction pipeline. Stage 1 collects raw tool sources. Stage 2 performs tool curation and executability filtering to obtain a validated tool inventory. Stage 3 normalizes tools into a unified manifest with standardized signatures, canonical arguments, and aligned output schemas. Stage 4 annotates each tool with finance attributes (timeliness, intent type, regulatory domain). Stage 5 sources and selects tool-required questions. Stage 6 aligns questions with tools via semantic retrieval, multi-sample verification, and execution checks. Stage 7 adds human-in-the-loop quality assurance. Stage 8 outputs the benchmark tool library and benchmark question set as a runnable benchmark.
Figure 2: FinToolBench dataset construction pipeline. Stage 1 collects raw tool sources. Stage 2 performs tool curation and executability filtering to obtain a validated tool inventory. Stage 3 normalizes tools into a unified manifest with standardized signatures, canonical arguments, and aligned output schemas. Stage 4 annotates each tool with finance attributes (timeliness, intent type, regulatory domain). Stage 5 sources and selects tool-required questions. Stage 6 aligns questions with tools via semantic retrieval, multi-sample verification, and execution checks. Stage 7 adds human-in-the-loop quality assurance. Stage 8 outputs the benchmark tool library and benchmark question set as a runnable benchmark.
이 pipeline 은 원본 도구 소스(raw tool sources) 수집, 도구 선별 및 실행 가능성 필터링(executability filtering), 도구 정규화(tool normalization) 및 manifest 구성, LLM 기반 금융 속성 주석(finance attribute annotation) 등을 포함합니다. 쿼리 측면에서는 금융 QA dataset 에서 tool-required question 을 선별하고, 도구와 쿼리 간의 semantic alignment 및 다중 샘플 검증(multi-sample verification)을 수행한 후, human-in-the-loop 검증을 거쳐 최종 benchmark 를 완성합니다.
또한, 저자들은 FATR ( Finance-Aware Tool Routing )이라는 lightweight baseline 을 제안합니다. FATR 은 [Figure 3] 와 같이 LLM planner 에 금융 제약 조건을 명시적으로 주입하는 방식으로 작동합니다. FATR 은 tool retrieval , finance attribute injection , 그리고 stabilized execution (caching, retries, output compression)을 통합하여 금융 도메인의 특정 과제를 해결합니다. 특히 [Figure 4] 와 같은 tool card 에 금융 속성을 주입함으로써 planner 의 도구 선택 및 추론을 가이드합니다.
주요 실험 결과는 아래 Table 3과 같습니다. Qwen3-8B는 가장 높은 TIR( 0.8712 )과 SOFT SCORE ( 0.4234 )를 보였으나, CER ( 0.3385 )은 상대적으로 낮아 인자 생성 오류(argument instantiation errors)나 실행 실패가 잦았음을 시사합니다. 반면, Doubao-Seed-1.6 는 가장 균형 잡힌 성능을 보이며 가장 높은 TESR ( 0.3254 )와 두 번째로 높은 CER ( 0.5000 )을 달성하여 안정적인 도구 계획 및 인자 생성을 나타냈습니다. GPT-40 는 매우 보수적인 전략으로 가장 낮은 TIR ( 0.2267 )을 기록했지만, 일단 도구를 호출하면 매우 높은 정밀도( CER 0.6176 , CSS 0.6700 )를 보였습니다. 이는 GPT-40 이 안전성과 정밀도를 recall 보다 우선시하는 trade-off 를 보여줍니다. [Figure 5] 는 금융 속성 주입이 TIR 을 약간 감소시키지만 CER 을 개선하고 TMR , IMR , DMR 과 같은 불일치율(mismatch rates)을 감소시켜 도구 선택 및 규정 준수 정렬(compliance alignment)을 향상시킨다는 것을 보여줍니다.
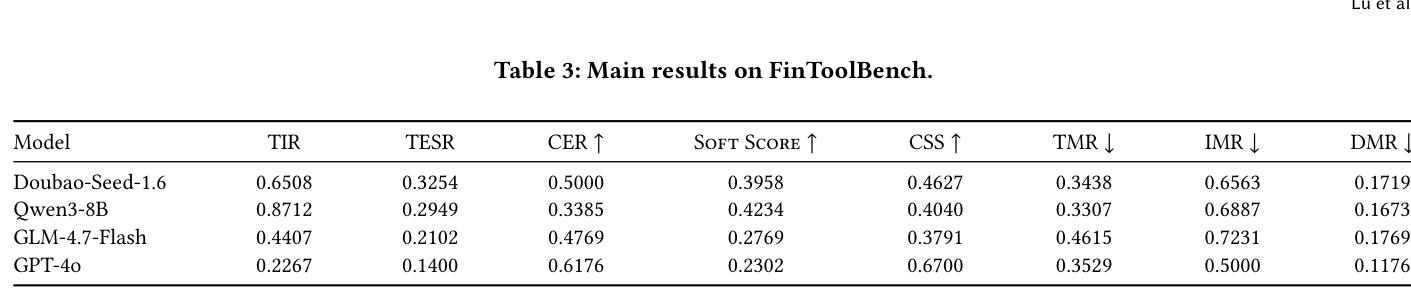 Table 3: Main results on FinToolBench.
Table 3: Main results on FinToolBench.
4. Conclusion & Impact (결론 및 시사점)
FinToolBench 는 금융 도구 사용 평가를 call-level capability 와 엄격한 regulatory compliance 중심으로 설계한 포괄적인 framework 입니다. 이 benchmark 는 760개 의 free-tier 도구 카탈로그와 295개 의 복잡하고 도구-필요 쿼리를 유기적으로 결합하여 독특한 가치를 제공합니다. 특히 capability metrics (에이전트가 도구를 호출하고 실행할 수 있는지)와 compliance metrics (도구 선택이 timeliness , intent , domain constraints 를 준수하는지)를 분리하여 평가하는 프로토콜은 실세계 금융 요구 사항을 정확하게 반영합니다.
이 연구는 FATR 과 같은 실용적인 baseline 을 제공함으로써, 금융 속성 주입(attribute injection)과 안정화된 실행(stabilized execution)을 통해 이러한 제약 조건들을 효과적으로 구현합니다. FinToolBench 는 auditable , agentic financial execution 을 위한 최초의 testbed 를 제공함으로써 금융 분야에서 신뢰할 수 있는 AI 의 새로운 표준을 제시합니다. 이는 연구 커뮤니티가 공통의 실행 가능한 benchmark 에서 agent 를 표준화된 방식으로 평가하고 비교할 수 있도록 하여 미래 연구를 촉진할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Efficient Reasoning on the Edge
- 현재글 : [논문리뷰] FinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
- 다음글 [논문리뷰] GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent
댓글