[논문리뷰] Efficient Reasoning on the Edge
링크: 논문 PDF로 바로 열기
저자: Yelysei Bondarenko, Thomas Hehn, Rob Hesselink, et al.
1. Key Terms & Definitions
- LoRA (Low-Rank Adapters) : LLM의 특정 레이어에 저랭크 행렬을 추가하여 효율적인 Fine-Tuning을 가능하게 하는 Parameter-Efficient Fine-Tuning (PEFT) 기법입니다.
- KV-cache (Key-Value cache) : Transformer 모델의 디코딩 단계에서 이전에 계산된 Key 및 Value 임베딩을 저장하여 중복 계산을 방지하고 Latency를 줄이는 데 사용되는 캐시입니다.
- Budget Forcing : Reinforcement Learning (RL)을 활용하여 LLM이 불필요하게 긴 Reasoning Trace를 생성하는 것을 억제하고, 지정된 Token Budget 내에서 간결한 응답을 생성하도록 유도하는 방법론입니다.
- Switcher Module : 들어오는 쿼리의 복잡성을 분석하여 Reasoning Mode (LoRA Adapters 활성화) 또는 Fast Base Model Mode (LoRA Adapters 비활성화)로 동적으로 라우팅하는 경량 분류 모듈입니다.
- W4A16KV8 : Weights는 4-bit, Activations는 16-bit, Key-Value Cache는 8-bit로 Quantization하는 기법을 지칭하는 용어입니다.
- FPTQuant (Function-Preserving Transforms for Quantization) : 모델의 기능을 유지하면서 중간 Activation 분포를 Quantization 친화적으로 재구성하는 변환 기법으로, Post-Training Quantization (PTQ)의 정확도 손실을 최소화합니다.
2. Motivation & Problem Statement
Large Language Models (LLMs)는 Chain-of-Thought (CoT) Reasoning을 통해 복잡한 문제 해결에서 최첨단 성능을 달성하지만, Edge Device 배포에는 여러 제약이 따릅니다. 주요 문제는 방대한 Reasoning Trace 와 대규모 Context 요구 사항 으로 인해 높은 Token Generation Cost, 큰 KV-cache Footprint, 그리고 소형 모델로 Reasoning 기능을 Distill할 때의 비효율성입니다. 기존 Distillation 접근 방식은 종종 Large Model의 Verbose하고 스타일적으로 중복되는 Reasoning Trace에 의존하여 On-Device 추론에 부적합합니다. 모바일 Device는 DRAM 용량, 전력 소비, Latency, 그리고 제한된 모델 크기로 인해 심각한 Memory Bottleneck에 직면하며, 이는 LLM Reasoning을 Edge에서 실용화하는 데 큰 장애물로 작용합니다.
3. Method & Key Results
본 연구는 Edge Device에서 효율적인 Reasoning을 위해 LoRA 기반 Fine-Tuning, Budget Forcing, 동적 Adapter Routing, 병렬 Inference-Time Scaling 및 Quantization을 통합한 End-to-End Pipeline 을 제안합니다.
-
LoRA 기반 Reasoning 활성화 : Parameter-Efficient LoRA Adapters와 Supervised Fine-Tuning (SFT)을 사용하여 Qwen2.5-7B-Instruct 모델에 Reasoning 기능을 부여했습니다. OT3 데이터셋에 LoRA Rank 128 로 Fine-Tuning한 결과, Dense Fine-Tuning 방식의 성능 향상 대부분을 회복하고, R1-Distill-Qwen-7B Baseline에 근접한 성능을 달성했습니다. 이는 경량 Adapter 학습만으로도 증류 모델의 기능을 상당 부분 복구할 수 있음을 시사합니다.
-
Budget Forcing을 통한 Verbosity 제어 : Reinforcement Learning (RL)을 사용하여 LoRA Adapters에 Budget Forcing을 적용하여 응답 길이를 크게 줄였습니다. 본 방법은 평균 Completion Length를 약 2.4배 단축했으며, 특정 쿼리에서는 최대 8배 의 압축률을 달성했습니다
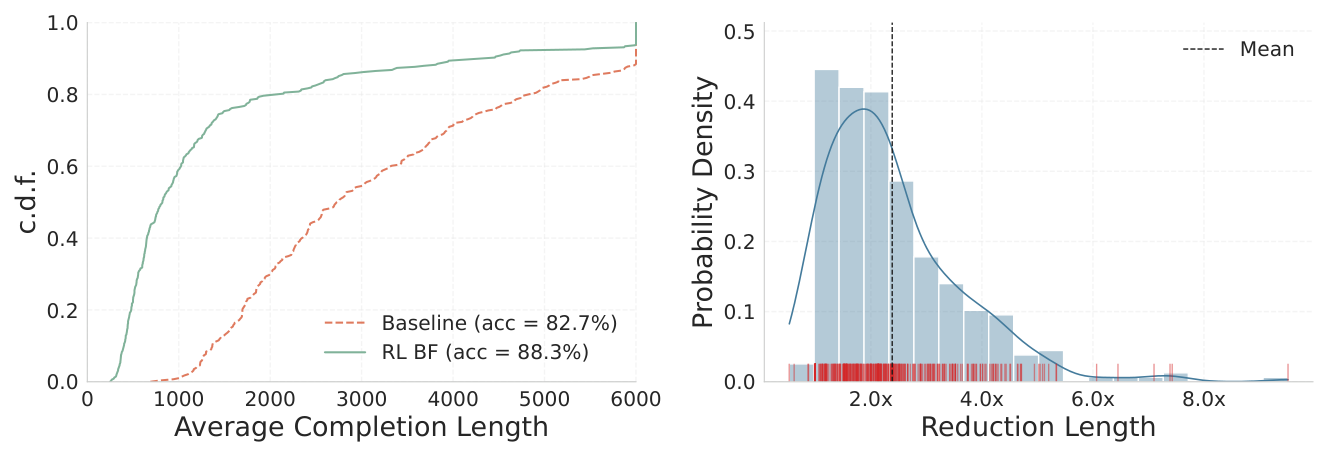 Figure 5: Average Completion Length Comparison.
Figure 5: Average Completion Length Comparison.
. 이와 동시에 Task Accuracy는 최소한의 손실만을 보였으며, 이는 MATH500 벤치마크에서 SFT Baseline 대비 최대 10% 향상된 Accuracy를 유지하며 Verbosity를 줄였습니다 [Table 8].
-
동적 LoRA Routing (Switcher Module) : 경량 Switcher Module을 도입하여 Reasoning이 필요할 때만 LoRA Adapters를 활성화하도록 했습니다. 이 Switcher는 Base LLM의 Hidden State를 기반으로 쿼리 복잡성을 분류합니다. 특히, Masked LoRA Training 전략을 통해 Prefill 단계에서 LoRA 가중치를 Mask하여 Base Model과 Reasoning Mode가 동일한 KV-cache를 공유하도록 함으로써 Re-encoding으로 인한 Latency 및 Compute Penalty를 완전히 제거했습니다.
-
병렬 Test-Time Scaling 및 경량 Verifier : Memory-Bound Decoding 시 Accuracy를 향상시키기 위해 병렬 Test-Time Scaling과 경량 Verifier를 활용했습니다. Verifier는 생성된 Response의 Correctness를 평가하는 Linear Head와 Sigmoid Activation으로 구성되며, Generator의 KV-cache를 재사용하여 오버헤드를 최소화합니다. MATH500 벤치마크에서 Weighted Majority Voting 은 Greedy Baseline 71.0% 및 Standard Majority Voting 70.0% 를 뛰어넘어, 2개 병렬 응답 시 72.7% , 8개 병렬 응답 시 78.2% 의 Accuracy를 달성하여 Baseline 대비 최대 10% Accuracy 향상을 보였습니다
 Table 9: Accuracy of our lightweight verifier weighted majority voting compared to majority voting without verifier and greedy decoding on MATH500.
Table 9: Accuracy of our lightweight verifier weighted majority voting compared to majority voting without verifier and greedy decoding on MATH500.
.
- Quantization을 통한 Edge 배포 : Qwen2.5-7B-Instruct 모델에 W4A16KV8 Quantization과 FPTQuant 변환을 적용하여 Base Model의 Predictive Performance를 강력하게 유지했습니다. FPTQuant 는 CSR 에서 Full-Precision Accuracy를 달성하고, WikiText-2 에서 Perplexity를 약 0.4 감소시키는 우수한 결과를 보였습니다. 여기에 Quantization-Aware Modular Reasoning (QAMR) 기법을 추가하여 4-bit Weight Quantized Qwen2.5-7B 모델이 Full-Precision Reasoning Model 대비 2% 이내의 Accuracy 손실로 Reasoning 성능을 달성하도록 했습니다.
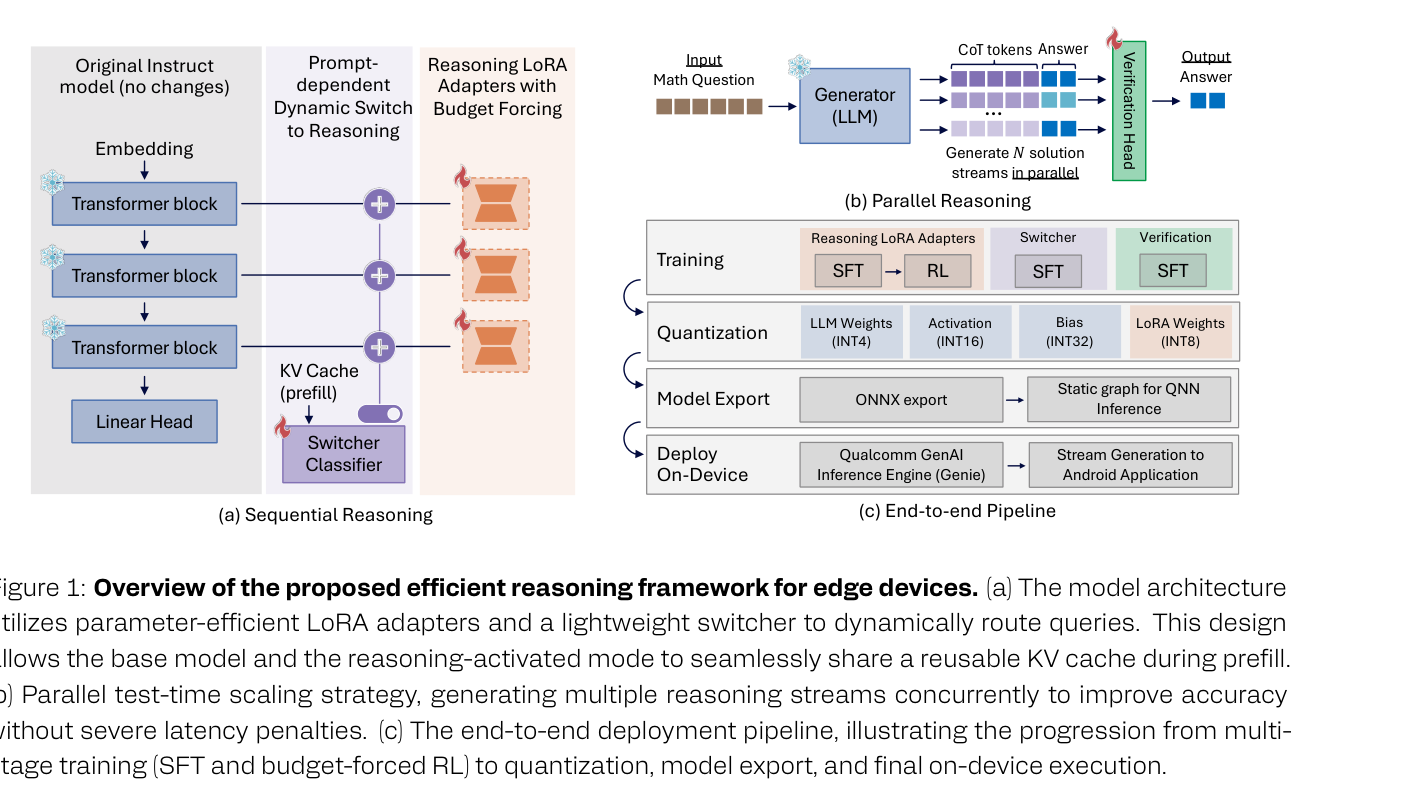 Figure 1: Overview of the proposed efficient reasoning framework for edge devices
Figure 1: Overview of the proposed efficient reasoning framework for edge devices
은 이 모든 구성 요소가 통합된 프레임워크의 개요를 보여줍니다.
4. Conclusion & Impact
본 연구는 LoRA Adapter, 동적 Switcher Routing, Budget Forced Reinforcement Learning, 병렬 Test-Time Scaling 및 하드웨어-인지 Quantization을 통합한 End-to-End Framework 를 제안하여, Resource 제약이 심한 Edge Device에서도 State-of-the-Art LLM Reasoning을 실용화하는 데 성공했습니다. 특히, KV-cache Reuse를 최대화하고, Quantization을 Adapter, Switcher, Verifier 학습에 직접 통합하는 등 하드웨어 인지적 접근 방식을 통해 클라우드 기반 Reasoning과 모바일 하드웨어의 엄격한 메모리, Latency, 전력 예산 간의 격차를 효과적으로 해소했습니다. 이는 온디바이스 AI 발전을 위한 실용적인 청사진 을 제시하며, Edge Device에서 지능형 개인 비서와 같은 새로운 Application의 가능성을 열어줄 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
Review 의 다른글
- 이전글 [논문리뷰] Demystifing Video Reasoning
- 현재글 : [논문리뷰] Efficient Reasoning on the Edge
- 다음글 [논문리뷰] FinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
댓글